Umformulieren von Web-Dokumenten soll KI-"Datenwand" überwinden

Das KI-Unternehmen Datology AI hat ein neues Framework namens BeyondWeb entwickelt, das synthetische Daten für das Training von Sprachmodellen nutzt. Die Methode soll das Problem knapper hochwertiger Trainingsdaten lösen und dabei deutlich effizienter sein als bisherige Ansätze.
Die KI-Industrie steht vor einem fundamentalen Problem: Während die Trainingsbudgets für große Sprachmodelle in die Billionen von Token wachsen, werden hochwertige Webdaten zunehmend knapp. Das KI-Unternehmen Datology AI präsentiert nun BeyondWeb als Lösung für diese "Datenwand": Das Framework wandelt bestehende Webdokumente in informationsdichtere Formate um, verbessert den pädagogischen Ton und strukturiert Inhalte neu.
Deutliche Leistungssteigerungen
Nach Angaben der Forschenden erreicht BeyondWeb bei 8B-Parameter-Modellen eine um 5,1 Prozentpunkte höhere Genauigkeit als Cosmopedia von Hugging Face und liegt 2,6 Prozentpunkte über Nvidias Nemotron-CC-Datensatz.
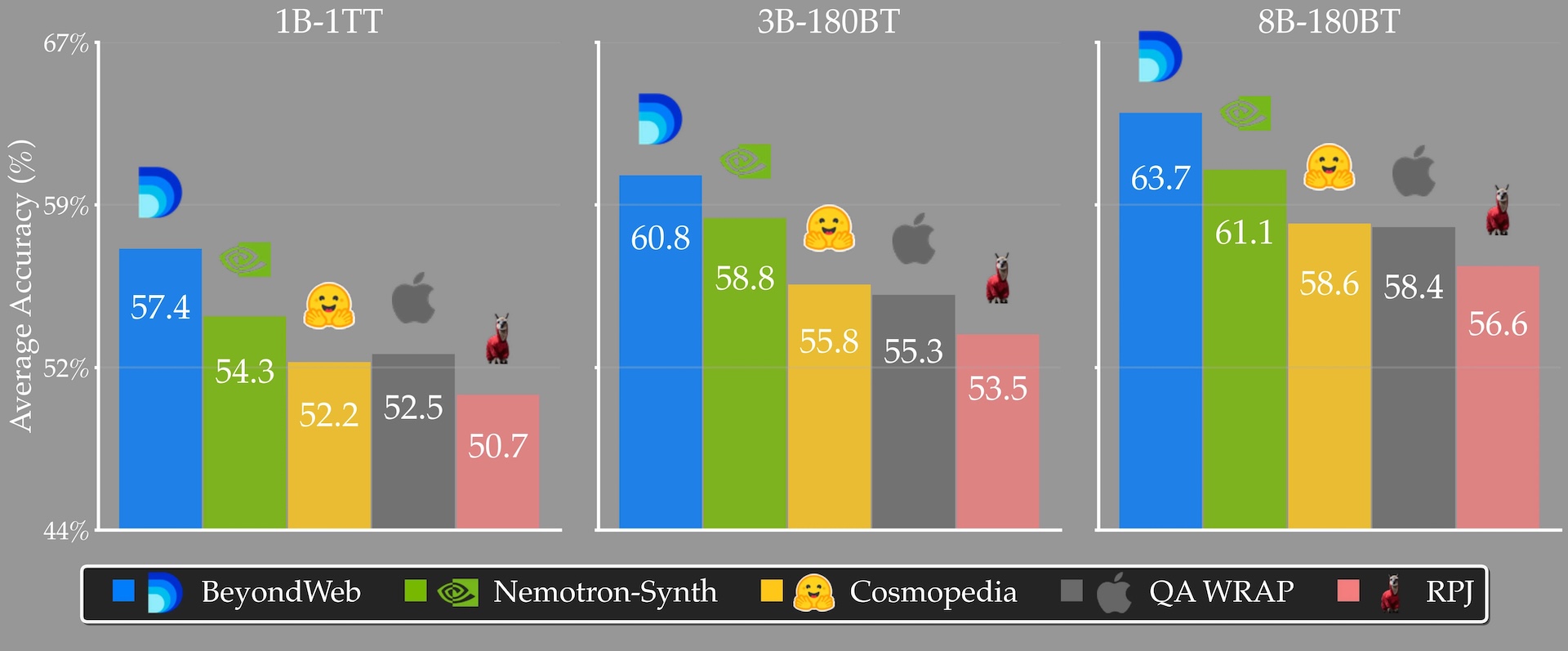
Bei der Trainingsgeschwindigkeit berichtet die Studie von erheblichen Unterschieden: BeyondWeb soll 7,7-mal schneller trainieren als offene Webdaten und 2,7-mal schneller als Nemotron Synthetic. Ein 3B-Parameter-Modell, das mit BeyondWeb trainiert wurde, übertraf laut den Forschenden sogar ein 8B-Modell mit dem gleichen Token-Budget auf Cosmopedia.
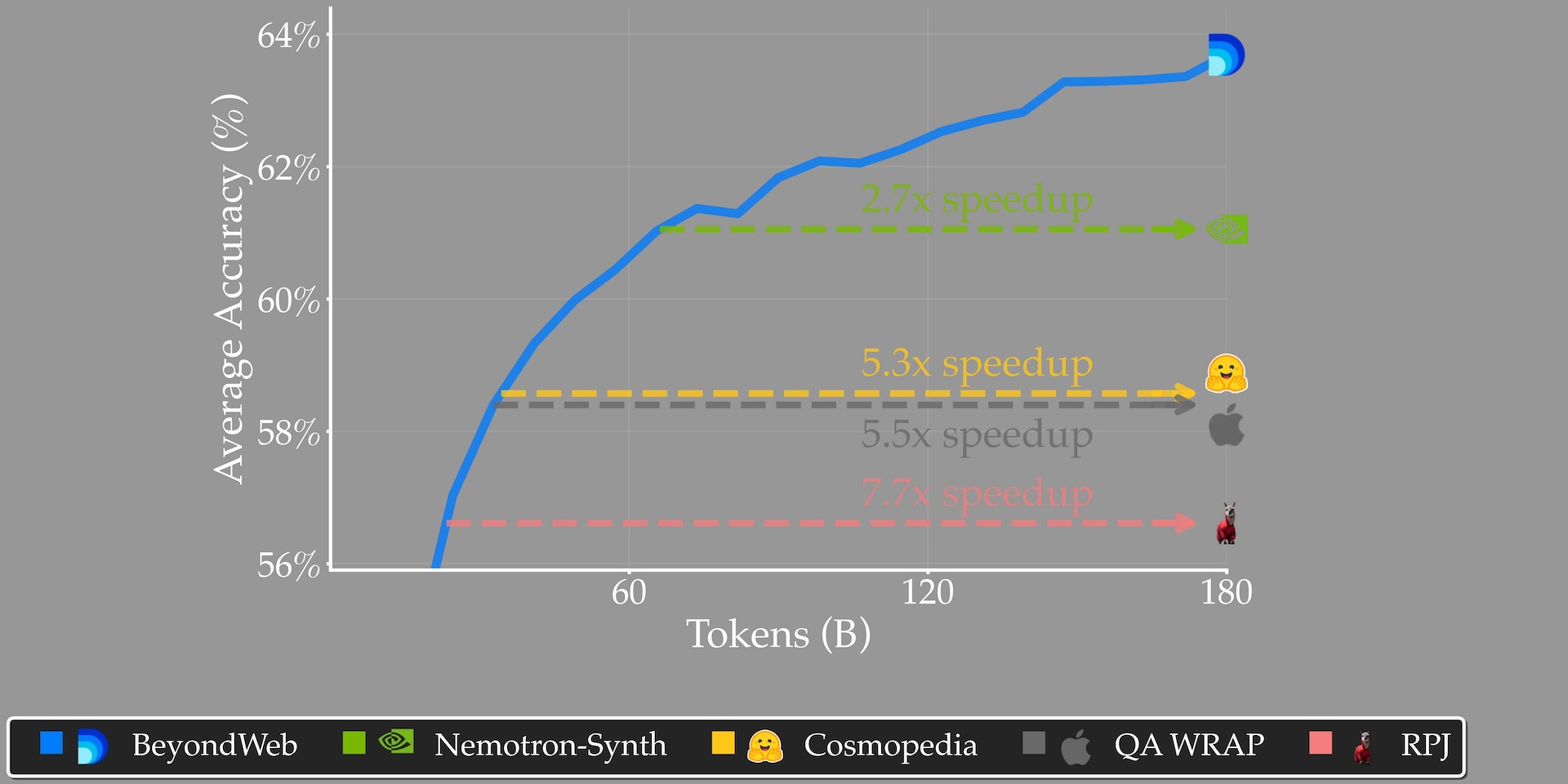
Die Forschenden untersuchten systematisch sieben Forschungsfragen zur synthetischen Datengenerierung. Ein zentraler Befund: Vielfalt ist entscheidend für nachhaltigen Erfolg. Während Standard-Methoden früh im Training Vorteile bieten, führt ihr Mangel an stilistischer Vielfalt zu abnehmenden Erträgen.
Interessant ist die Erkenntnis zur Stil-Anpassung: Konversationsinhalte machen weniger als 2,7 Prozent der Webdaten aus, obwohl Chat die primäre Anwendung von LLMs ist. Das Erhöhen des Anteils konversationaler Daten verbessert die Leistung, die Verbesserungen sättigen jedoch schnell.
Kleine Modelle als effektive Umformulierer
Die Studie ergab, dass kleine LLMs effektive Umformulierer sein können. Die Qualität synthetischer Daten steigt beim Übergang von 1B auf 3B Parameter um 1,5 Prozentpunkte, sättigt dann aber bei 8B. Dies könnte hochwertige synthetische Datengenerierung auch für Organisationen mit begrenzten Ressourcen zugänglich machen.
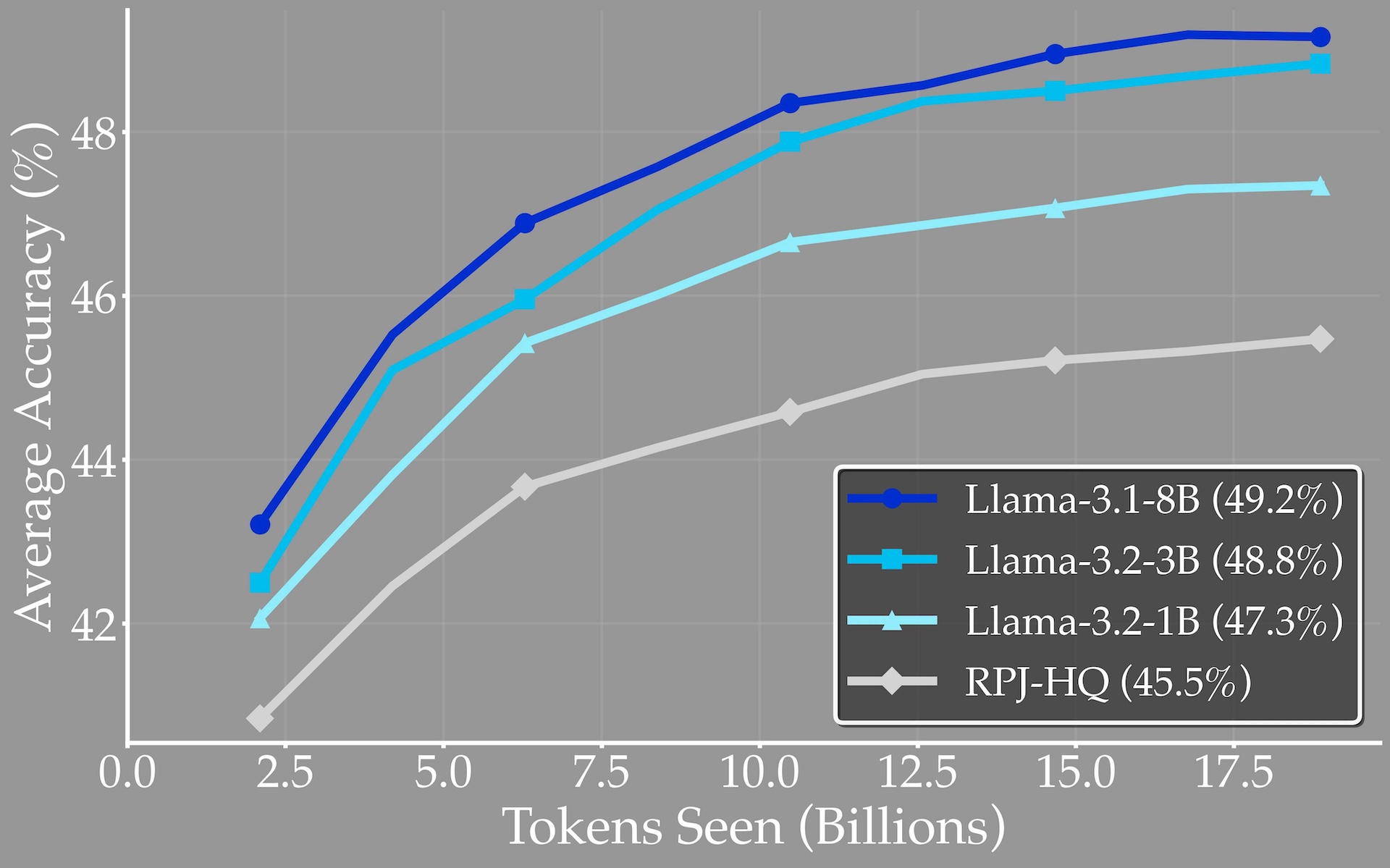
Die Forschenden testeten verschiedene Umformulierer-Modellfamilien und fanden heraus, dass alle ähnlich hochwertige synthetische Daten produzieren. Die allgemeine Benchmark-Leistung eines Modells sage demzufolge nicht die Qualität der von ihm erzeugten synthetischen Daten voraus.
Einsatz in der Praxis
Das BeyondWeb-Framework wurde bereits für das 4,5B-Parameter-Modell AFM von ArceeAI eingesetzt. Für die praktische Umsetzung entwickelten die Wissenschaftler:innen eine skalierbare Pipeline, die Billionen von Token verarbeiten kann.
Die Autor:innen betonen, dass die Generierung hochwertiger synthetischer Daten komplex ist und verschiedene Faktoren optimiert werden müssen. Eine freie Veröffentlichung von BeyondWeb für Forschungszwecke kündigt das Start-up nicht an.
Microsoft demonstrierte mit Phi-4 im Dezember 2024, wie synthetische Daten die KI-Leistung steigern können. Das Modell wurde gezielt mit 400 Milliarden Token synthetischer "lehrbuchartiger" Daten trainiert und nutzt spezielle "pivotal tokens" für bessere Lernergebnisse. In Benchmarks erzielen die Phi-4-Modelle gute Ergebnisse.
Ein halbes Jahr zuvor stellte Nvidia mit Nemotron-4 340B eine komplette Open-Source-Pipeline zur Generierung synthetischer Daten vor, wobei 98 Prozent der Trainingsdaten für das Instruct-Modell synthetisch erstellt wurden. Gleichzeitig konnten Forscher die weit verbreitete These vom "Modellzusammenbruch" widerlegen und zeigen, dass synthetische Daten bei richtigem Einsatz durchaus die KI-Entwicklung vorantreiben können.
Auch OpenAI erklärte bei der Vorstellung von GPT-5, dass das Modell mit synthetischen Daten trainiert wurde, die wohl vom hauseigenen o3‑Modell erzeugt wurden. Während andere Unternehmen synthetische Daten vor allem nutzen, um günstige Trainingsdatensätze zu erstellen, betonte OpenAI im Livestream, dass die eigenen Daten gezielt so aufbereitet seien, dass sie echtes Lernen ermöglichen – nicht bloß, um Lücken zu füllen. Vorgestellt wurde dieses Prinzip von Sébastien Bubeck, der zuvor die Entwicklung der Phi-Modelle bei Microsoft leitete.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.