Nvidia veröffentlicht kostenlose Sprachmodelle optimiert für die Datengenerierung

Nvidia stellt mit Nemotron-4 340B eine Open-Source-Pipeline für die Generierung synthetischer Daten zur Verfügung. Das Sprachmodell soll Entwicklern helfen, qualitativ hochwertige Datensätze für das Training und Fine-Tuning großer Sprachmodelle (LLMs) für kommerzielle Anwendungen zu erstellen.
Die Nemotron-4 340B-Familie besteht aus einem Basismodell, einem Instruktions- und einem Belohnungsmodell, die zusammen eine Pipeline zur Erzeugung synthetischer Daten bilden. Diese Daten können für das Training und die Verfeinerung von LLMs verwendet werden. Das Basismodell von Nemotron wurde mit 9 Billionen Token trainiert.
Synthetische Daten zeichnen sich dadurch aus, dass sie die Eigenschaften realer Daten imitieren und somit die Datenqualität und -quantität verbessern können. Das ist besonders wichtig, wenn der Zugang zu großen, vielfältigen und annotierten Datensätzen begrenzt ist.
Laut Nvidia erzeugt das Nemotron-4 340B Instruct-Modell vielfältige synthetische Daten, die die Leistung und Robustheit maßgeschneiderter LLMs in verschiedenen Anwendungsbereichen wie Gesundheitswesen, Finanzwesen, Fertigung und Einzelhandel verbessern können.
Mit dem Nemotron-4 340B Reward-Modell kann die Qualität der von der KI generierten Daten weiter verbessert werden, indem qualitativ hochwertige Antworten herausgefiltert werden.
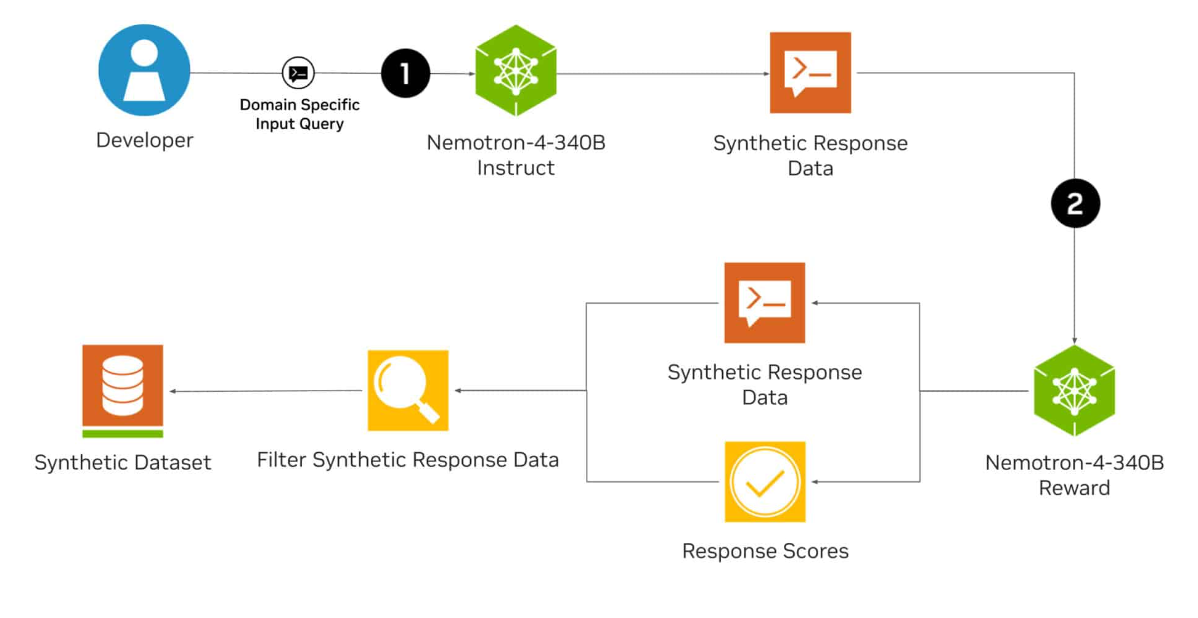
98 Prozent der für die Feinabstimmung der für das Instruct-Modell verwendeten Trainingsdaten sind synthetisch und wurden mit der Pipeline von Nvidia erstellt.
In Benchmarks wie MT-Bench, MMLU, GSM8K, HumanEval und IFEval schneidet das Instruct-Modell in der Regel besser ab als andere Open-Source-Modelle wie Llama-3-70B-Instruct, Mixtral-8x22B-Instruct-v0.1 und Qwen-2-72B-Instruct und in einigen Tests sogar besser als GPT-4o.
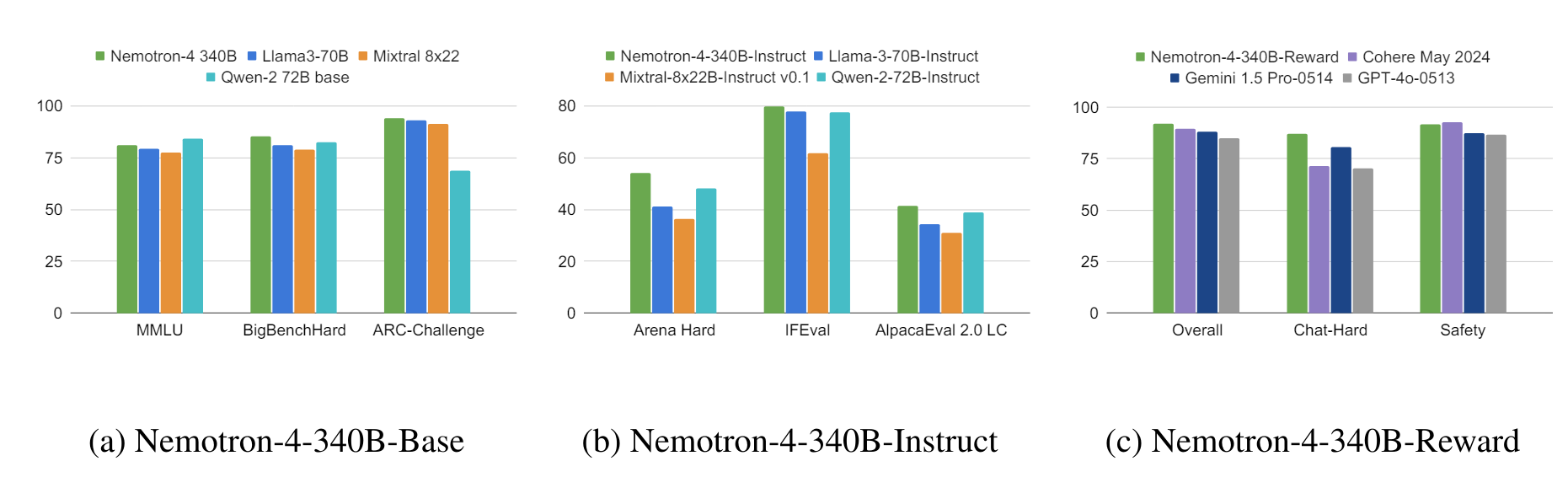
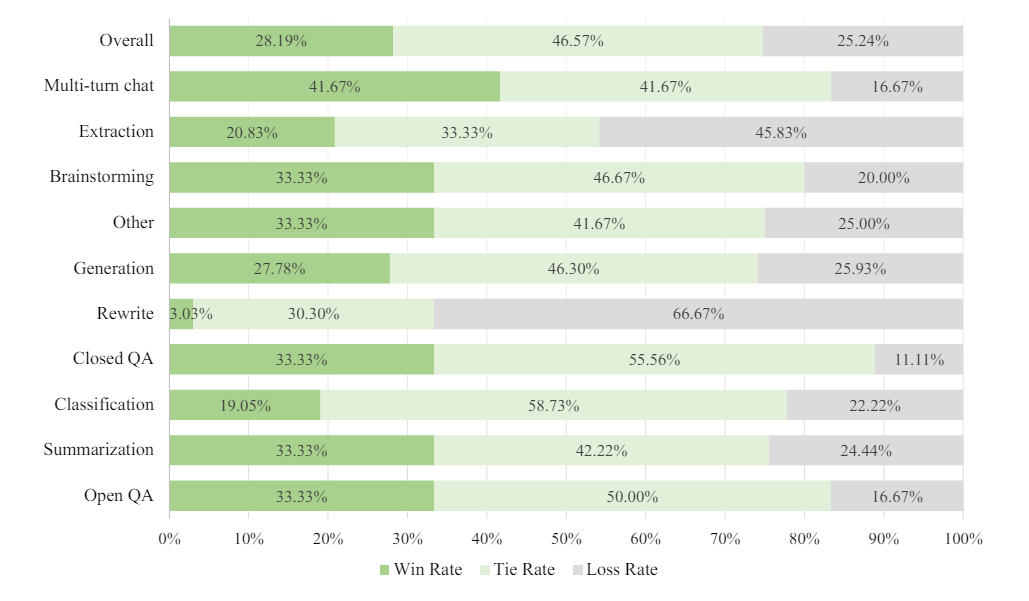
Es ist auch vergleichbar oder besser als GPT-4-1106 von OpenAI bei der menschlichen Bewertung für verschiedene Textaufgaben wie Zusammenfassungen und Brainstormings. Detaillierte Benchmarks sind im technischen Report verfügbar.
Die Modelle sind für die Inferenz mit dem Open-Source-Framework NVIDIA NeMo und der NVIDIA TensorRT-LLM-Bibliothek optimiert. Nvidia stellt sie unter der Open-Model-Lizenz zur Verfügung, die auch den kommerziellen Einsatz freigibt. Alle Daten sind bei Huggingface verfügbar.
Interessant ist der strategische Ansatz von Nvidia: Anstatt Nemotron als Konkurrenz zu Llama 3 oder gar GPT-4 zu positionieren, bietet man die Modellfamilie als Datengenerator an, damit andere Entwickler bessere oder mehr Modelle in verschiedenen Domänen trainieren können. Mehr Training und mehr Modelle auf dem Markt bedeuten eine höhere Nachfrage nach GPUs.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.