Unified-IO 2 zeigt, wie GPT-5 aussehen könnte

Der KI-Forschungsverband Allen Institute for AI hat ein neues, fortschrittliches KI-Modell namens Unified-IO 2 vorgestellt.
Es ist das erste Modell, das Text, Bild, Audio, Video und Handlungssequenzen verarbeiten und produzieren kann. Das 7 Milliarden Parameter große Modelle wurde von Grund auf neu auf einer breiten Palette multimodaler Daten trainiert und kann per Prompts gesteuert werden.
Multimodales Unified-IO 2 wurde mit Milliarden Datenpunkten trainiert
Unified-IO 2 wurde mit 1 Milliarde Bild-Text-Paare, 1 Billion Text-Token, 180 Millionen Videoclips, 130 Millionen Bildern mit Text, 3 Millionen 3D-Assets und 1 Million Bewegungsabläufen von Robotikagenten trainiert. Insgesamt kombinierte das Team mehr als 120 Datensätze in einem 600 Terabyte großen Paket, das 220 visuelle, sprachliche, auditive und handlungsbezogene Aufgaben abdecken.
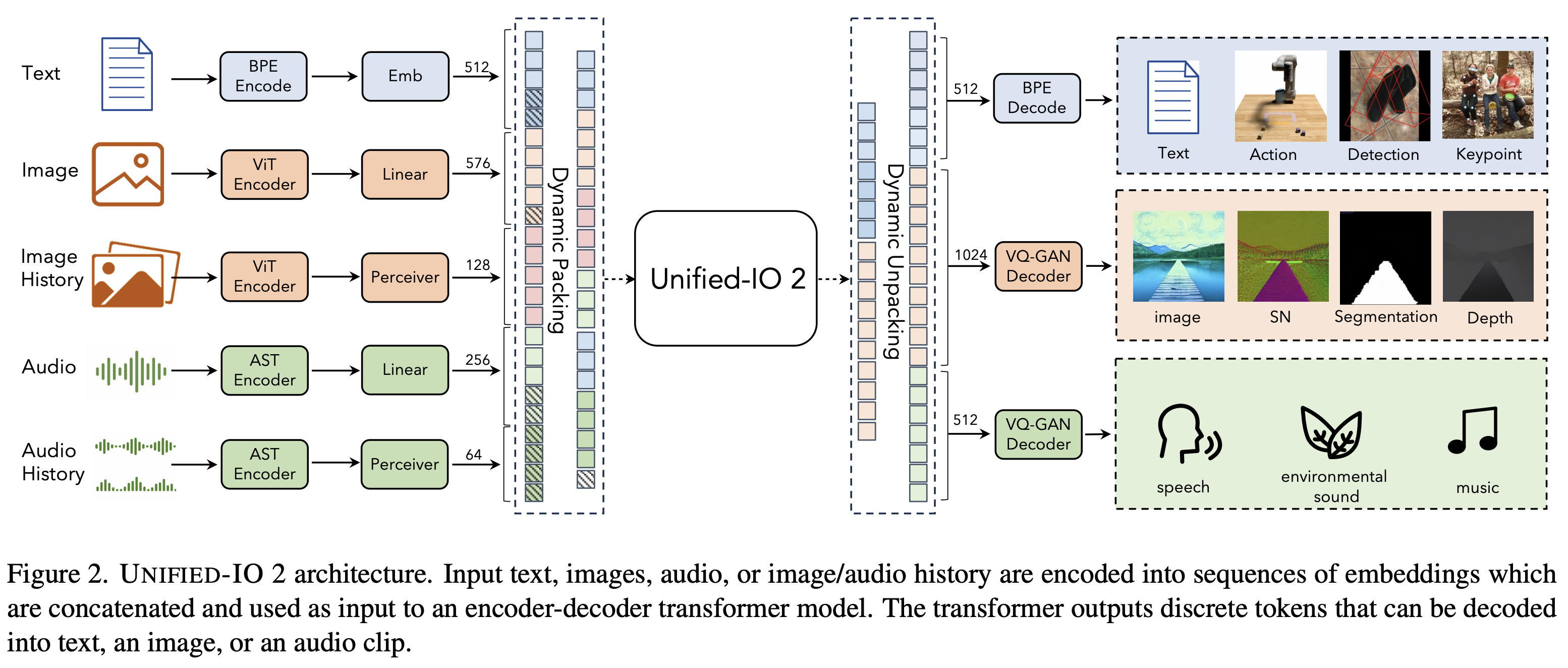
Das Encoder-Decoder-Modell verwendet verschiedene architektonische Änderungen, um das Training zu stabilisieren und die multimodalen Signale effektiv zu nutzen und ebnet so den Weg für größere und leistungsfähigere Modelle mit vielen Modalitäten.
Unified-IO 2 ist bisher einzigartig
Das Training ermöglicht es Unified-IO 2, Text zu verarbeiten, zu verstehen und zu produzieren. Das Sprachmodell kann z.B. Fragen beantworten, Texte auf der Grundlage von Anweisungen verfassen und Textinhalte analysieren. Das Modell kann auch Bildinhalte erkennen, Bildbeschreibungen liefern, Bildbearbeitungsaufgaben ausführen und neue Bilder auf der Grundlage von Textbeschreibungen erstellen.
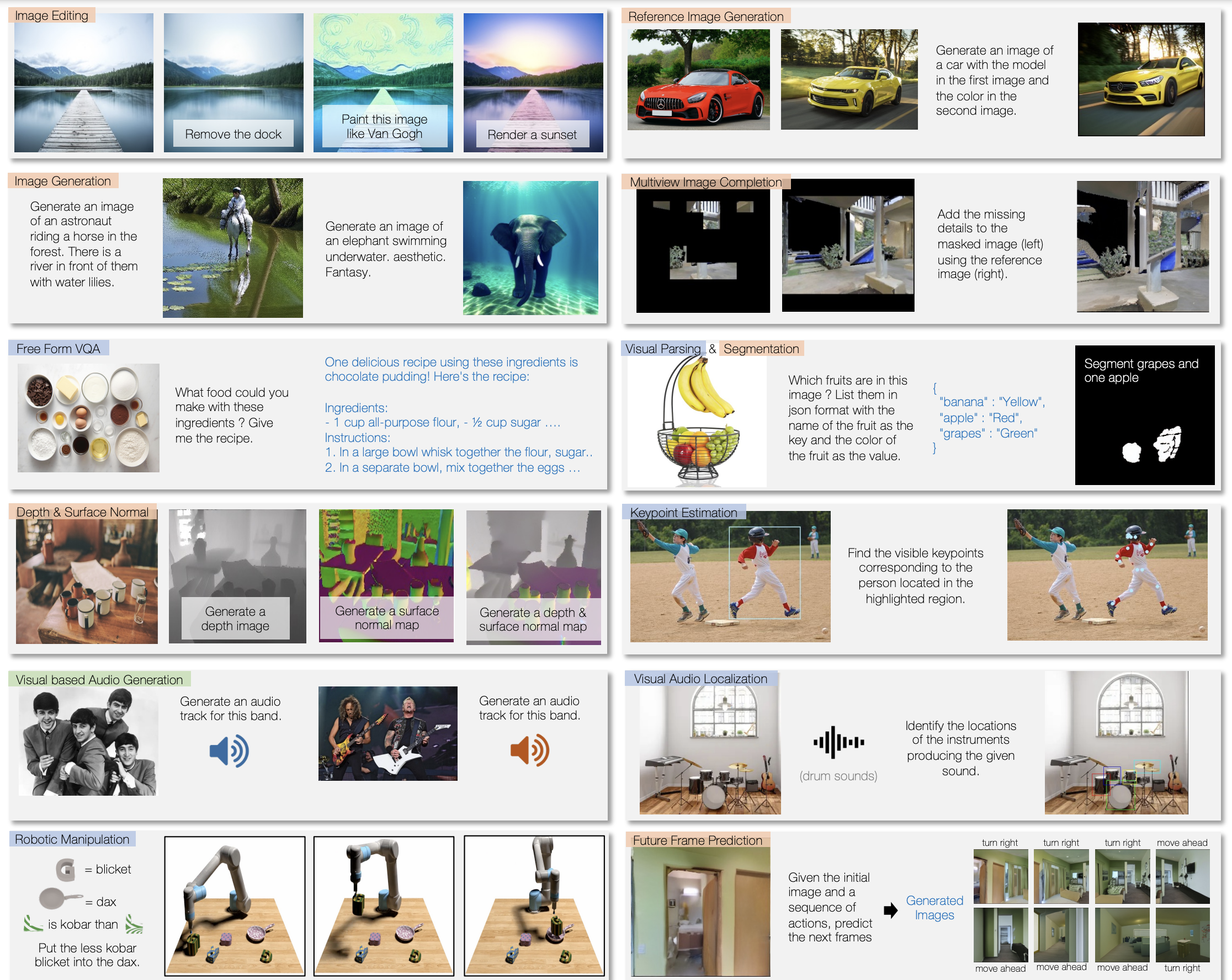
Darüber hinaus kann es beispielsweise Musik oder Geräusche auf der Grundlage von Beschreibungen oder Anweisungen erzeugen sowie Videos analysieren und beispielsweise Fragen zum Video beantworten. Durch Training mit Roboterdaten kann Unified-IO 2 auch Aktionen für Robotersysteme generieren und so z.B. Anweisungen in Handlungssequenzen für Roboter umwandeln. Durch das multimodale Training kann es auch die verschiedenen Modalitäten verarbeiten und etwa auf einem Bild die Instrumente einer Tonspur markieren.
In über 35 Benchmarks zeigt das Modell gute Ergebnisse, darunter Bilderzeugung und -verstehen, Verstehen natürlicher Sprache, Video- und Audioverstehen und Robotermanipulation. Es erreicht vergleichbare oder bessere Leistungen als spezialisierte Modelle in den meisten Aufgaben. Zudem stellt es einen neuen Bestwert im GRIT-Benchmark für Bildaufgaben auf, der testet, wie Modelle mit Bildstörungen und anderen Problemen umgehen.
Unified-IO kam vor GPT-4, Unified-IO 2 vor GPT-5?
Der Vorgänger, Unified-IO, wurde im Juni 2022 vorgestellt und war eines der ersten multimodalen Modelle, das Bilder und Sprache verarbeiten konnte. Etwa zur gleichen Zeit testete OpenAI intern GPT-4, bevor das Unternehmen im März 2023 das große Sprachmodell mit GPT-4-Vision vorstellte.
Unified-IO war somit ein früher Einblick in die Zukunft der großen KI-Modelle, die mittlerweile mit OpenAIs Modellen und dem multimodal trainierten Gemini von Google alltäglich geworden sind. Unified-IO 2 zeigt nun, was wir 2024 erwarten können: Neue KI-Modelle, die noch mehr Modalitäten verarbeiten, durch umfangreiches Lernen viele Aufgaben nativ übernehmen können – und ein rudimentäres Verstehen von Interaktionen mit Objekten und Robotern haben. Letzteres könnte ihre Leistung auch in anderen Bereichen positiv beeinflussen.
Das Team plant nun, Unified-IO 2 weiter zu skalieren, die Datenqualität zu verbessern und das Encoder-Decoder-Modell in eine branchenübliche Decoder-Modell-Architektur umzuwandeln.
Mehr Informationen und den Code gibt es auf der Projektseite von Unified-IO 2.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.