V-JEPA: Meta-KI lernt intuitive Physik allein durch Beobachten von Videos

Ein Forscherteam um Metas KI-Chef Yann LeCun zeigt, wie KI-Systeme allein durch das Betrachten von Videos ein grundlegendes Verständnis physikalischer Gesetze entwickeln können. Die Ergebnisse unterstützen LeCuns Vision einer Alternative zur generativen KI und untermauern seine Kritik an Modellen wie OpenAIs Sora.
Künstliche Intelligenz kann durch selbstüberwachtes Training an natürlichen Videos ein intuitives Verständnis physikalischer Gesetze entwickeln. Das zeigt eine neue Studie von Forschern von Metas FAIR, der Universität Gustave Eiffel und der EHESS. Die Ergebnisse stützen laut dem Team die These, dass KI-Systeme auch ohne vorprogrammierte Regeln grundlegende Konzepte der physischen Welt erlernen können.
Das KI-Modelle des Teams wurde mit Videos trainiert, wobei es lernte, verdeckte oder fehlende Teile der Videos vorherzusagen. Anders als generative KI-Modelle wie OpenAIs Sora nutzen die Forscher dafür allerdings die sogenannte Video Joint Embedding Predictive Architecture (V-JEPA), die Vorhersagen nicht auf Pixelebene, sondern in einem abstrakten Repräsentationsraum trifft. Statt jedes Detail eines Videos vorherzusagen, lernt das System so übergeordnete Konzepte - in der Vision von LeCun eine Annäherung an die Funktionsweise des menschlichen Gehirns.
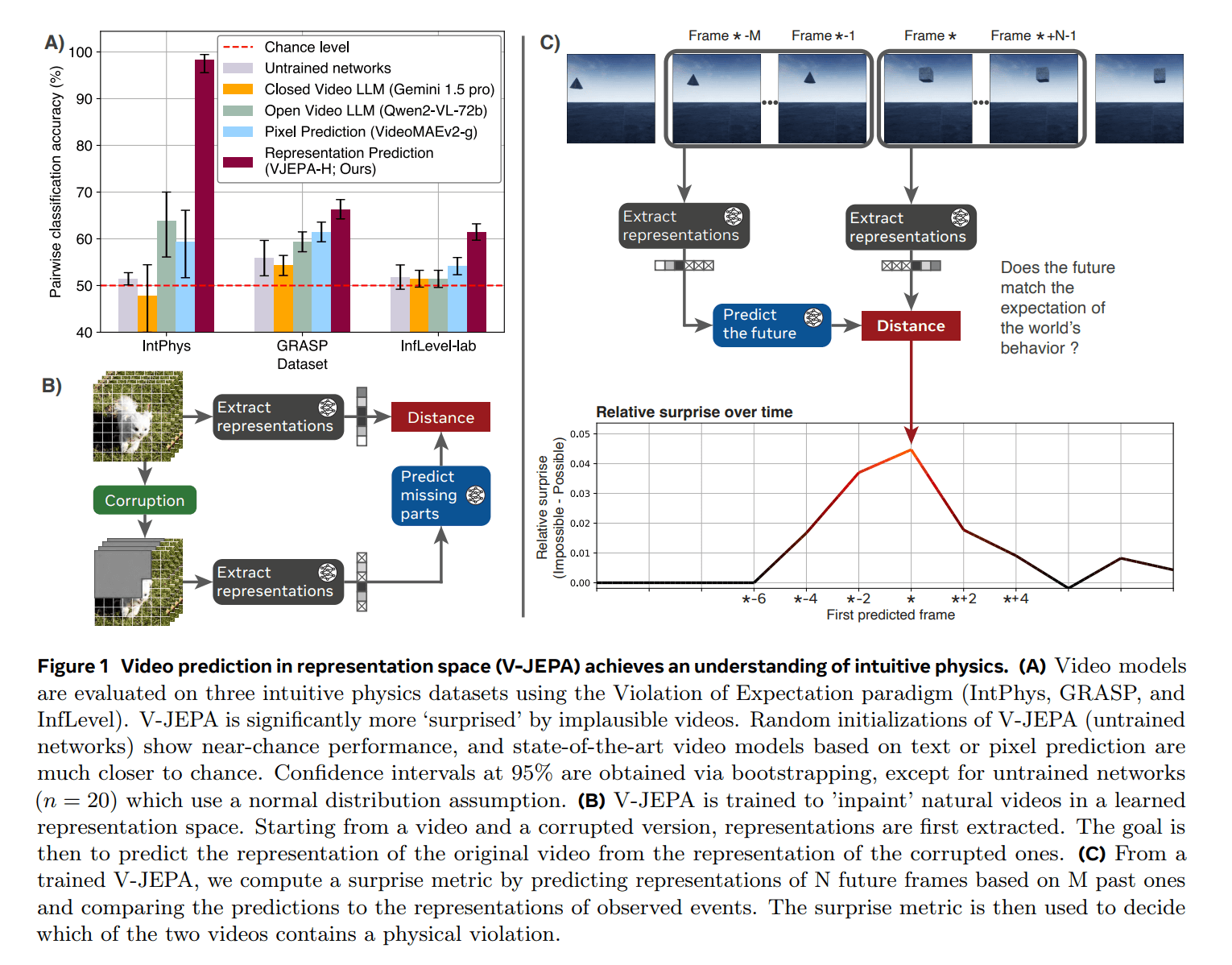
Eine weitere Besonderheit: Das Team nutzte für die Evaluierung der Modelle das "Violation-of-Expectation"-Paradigma - eine Methode, die ursprünglich aus der Entwicklungspsychologie stammt und das Physikverständnis von Säuglingen testet. Bei diesem Ansatz werden Probanden zwei ähnliche Szenen gezeigt, von denen eine physikalisch unmöglich ist - etwa ein Ball, der durch eine Wand rollt. Die Überraschungsreaktion auf solche Verstöße gegen Naturgesetze gibt Aufschluss darüber, ob grundlegende physikalische Konzepte verstanden wurden.
Besseres Physikverständnis als große Sprachmodelle
Die Forscher testeten das System mit drei verschiedenen Datensätzen: IntPhys für grundlegende Physikkonzepte, GRASP für komplexere Interaktionen und InfLevel für Tests in realistischen Umgebungen. V-JEPA zeigte dabei ein besonders gutes Verständnis für Objektpermanenz, räumliche Kontinuität und Formkonstanz. Große multimodale Sprachmodelle wie Gemini 1.5 Pro oder Qwen2-VL-72B lagen dagegen kaum über der Zufallsrate.
Bemerkenswert ist auch, dass V-JEPA diese Leistung bereits mit relativ wenig Trainingsmaterial erreichte. Schon 128 Stunden Videomaterial reichten aus, um grundlegende physikalische Konzepte zu erlernen. Auch kleinere Modelle mit nur 115 Millionen Parametern zeigten gute Ergebnisse.
Teil einer größeren Vision für die KI-Entwicklung
Die Ergebnisse stellen laut dem Forscherteam eine wichtige Annahme der KI-Forschung infrage: Bisher ging man davon aus, dass KI-Systeme ein vorprogrammiertes "Kernwissen" über physikalische Gesetze benötigen. V-JEPA demonstriert jedoch, dass dieses Wissen auch durch reines Beobachten erworben werden kann - ähnlich wie bei Säuglingen, Primaten oder sogar Küken, bei denen ein grundlegendes Physikverständnis ebenfalls früh nachweisbar ist.
Die Studie ist Teil von Metas breiter angelegter Forschung an der JEPA-Architektur. Diese soll eine Alternative zu generativen KI-Modellen wie GPT-4o oder Sora bieten. Meta-KI-Chef LeCun sieht in der pixel-genauen Generierung, wie sie etwa Sora betreibt, eine "Sackgasse" für die Entwicklung echter KI-Intelligenz.
Stattdessen setzt LeCun auf hierarchisch gestapelte JEPA-Module, die Vorhersagen auf verschiedenen Abstraktionsebenen treffen. Das Ziel sind umfassende Weltmodelle, die autonomen KI-Systemen ein tieferes Verständnis ihrer Umwelt ermöglichen sollen. Vor Videos hatte das Team um LeCun bereits erste Experimente mit einer Bildvariante namens I-JEPA durchgeführt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.