Viele Website-Betreiber ahnungslos: Nur 3 % blockieren die aktivsten KI-Crawler

Eine Analyse von Cloudflare zeigt, dass Bytespider, Amazonbot und ClaudeBot zu den aktivsten KI-Crawlern im Internet gehören. Viele Unternehmen verbergen ihre KI-Crawler.
Cloudflare wertete über das letzte Jahr aus, welche KI-Crawler mit bekannten Nutzeragent-Strings das größte Anfragevolumen aufweisen. Die Bytedance-Tochter Bytespider führt die Liste der aktivsten KI-Webcrawler an, gefolgt von Amazonbot, ClaudeBot und GPTBot von OpenAI.
Bytespider könnte Trainingsdaten für den chinesischen ChatGPT-Konkurrenten Doubao sammeln, der Amazonbot soll hauptsächlich Alexa-Antworten indexieren. ClaudeBot sammelt Trainingsdaten für Anthropics Claude-Modelle.
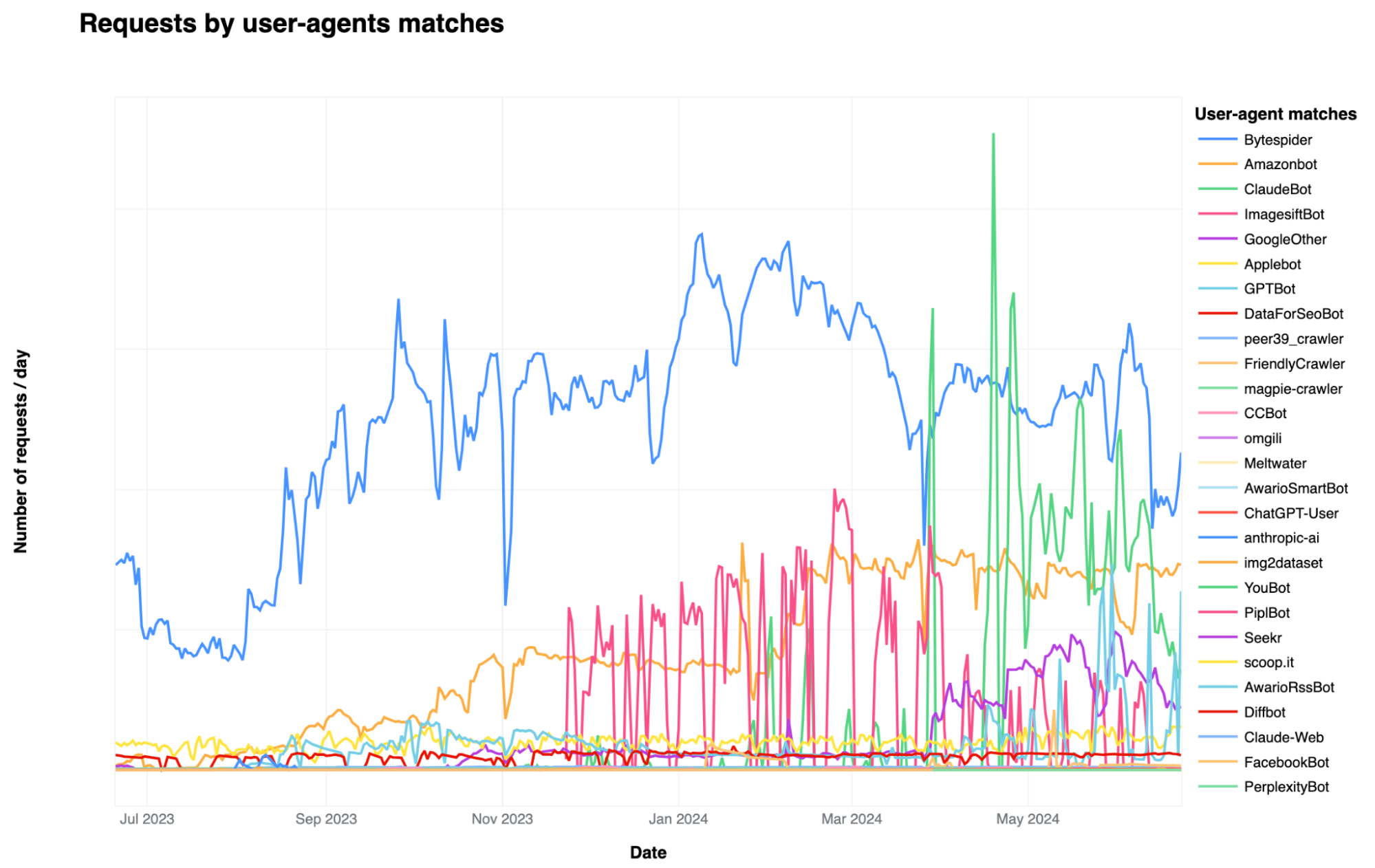
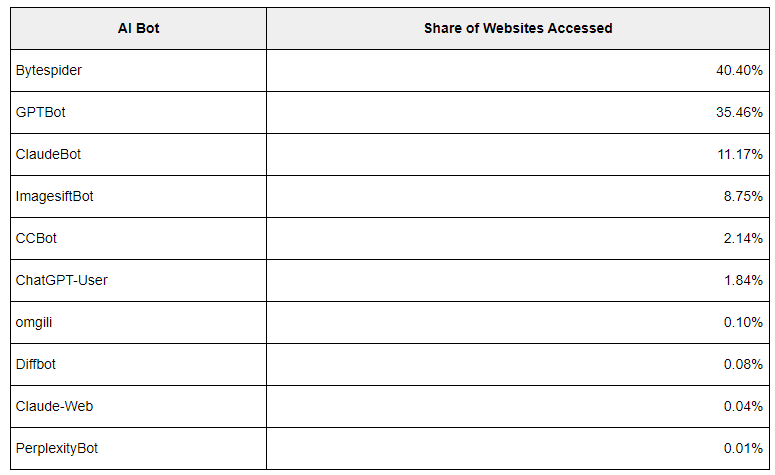
GPTBot von OpenAI, der Trainingsdaten für Produkte wie ChatGPT sammelt, ist der am zweithäufigsten blockierte KI-Bot und derjenige mit den zweitmeisten Webseitenaufrufen. Bytespider führt beide Ranglisten an.
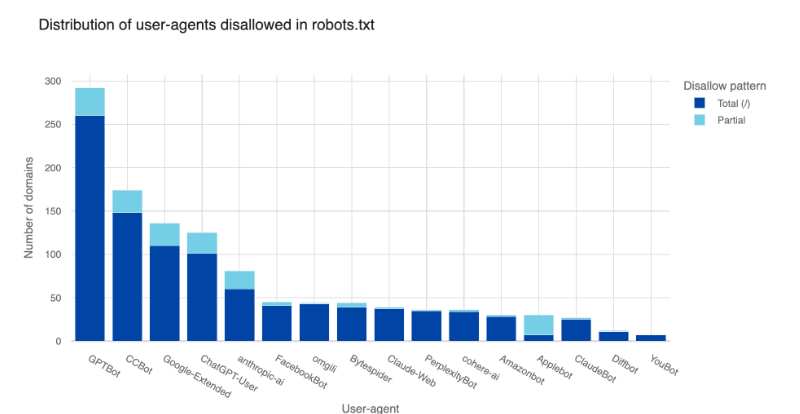
Die Cloudflare-Analyse zeigt jedoch auch, dass sich viele Website-Betreiber des Ausmaßes der KI-Crawler-Aktivitäten nicht bewusst sind. Nur wenige blockieren insgesamt betrachtet KI-Bots wie Bytespider und ClaudeBot aktiv in ihrer robots.txt-Datei.
Im Juni crawlten KI-Bots laut Cloudflare rund 39 Prozent der Top-1-Million-Domains. Nur 2,98 Prozent dieser Webseiten blockierten oder filterten die Anfragen. Je höher eine Seite gerankt ist, desto wahrscheinlicher ist sie Ziel von KI-Bots und blockiert diese auch, so Cloudflare.
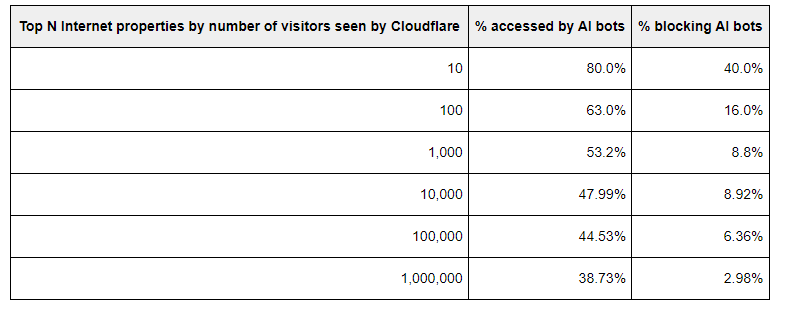
Diese Statistik ist insofern logisch, als bei besonders populären Websites die Inhalte wahrscheinlich das Kerngeschäft oder einen Teil des Kerngeschäfts des Website-Betreibers darstellen und dieser sich daher mehr um den Schutz der Inhalte kümmert. Außerdem verfügen sie über die Ressourcen zur Umsetzung technischer Maßnahmen.
Dass der OpenAI-Bot bei der Anzahl der besuchten Webseiten an zweiter Stelle steht, deutet darauf hin, dass OpenAI trotz der im Vergleich zu den Bots von Bytedance und Anthropic geringeren Crawling-Frequenz weiterhin viele Daten sammelt. Die geringere Crawling-Frequenz könnte darauf zurückzuführen sein, dass der GPT-Bot effizienter oder selektiver Trainingsdaten sammelt.
OpenAI-Chef Sam Altman sagte kürzlich, dass es in Zukunft darum gehen wird, mehr aus qualitativ hochwertigen Daten zu lernen, anstatt immer mehr Daten anzuhäufen. Zudem dürfte OpenAI bereits über eine große Menge an Daten aus früheren Crawling-Prozessen verfügen.
Dass der GPTBot von OpenAI relativ häufig geblockt wird, liegt vermutlich daran, dass OpenAI diese Möglichkeit transparent kommuniziert hat und ChatGPT die bekannteste KI-Plattform ist.
KI-Bots tarnen sich als Browser
Cloudflare beobachtet zudem, dass sich KI-Bots zunehmend als normale Browser tarnen, um Zugriff auf Inhalte zu erhalten. Zuletzt stand hier Perplexity in der Kritik.
Dazu ändern die Crawler ihren User-Agent-String. Die globalen Machine-Learning-Modelle von Cloudflare erkennen solche Crawler jedoch zuverlässig anhand von Mustern, ohne dass sie manuell trainiert werden müssen, so die Analyse des Unternehmens.
Um Website-Betreiber zu unterstützen, hat Cloudflare jetzt ein neues Feature für alle Kunden eingeführt, mit dem sich alle KI-Bots mit einem Klick im Dashboard blockieren lassen. Die Funktion soll laufend um neue Fingerabdrücke erweitert werden, wenn Cloudflare weitere Crawler identifiziert.
Zudem bietet Cloudflare ein Reporting-Tool, über das man KI-Crawler an das Unternehmen melden kann, damit sie analysiert und zukünftig automatisch geblockt werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.