
Vision-Robotics Bridge lernt den Angebotscharakter von Umgebungen und soll so das Lernen von Robotern beschleunigen.
Mehrere Forschungsprojekte untersuchen, wie Roboter aus Videos lernen können, da es nicht genügend Roboter-Trainingsdaten gibt - ein Grund, warum beispielsweise OpenAI seine eigene Roboterforschung eingestellt hat.
Für umfangreiche Robotertrainingsdaten müsste es viele Roboter geben, die Aktionen in der realen Welt ausführen, aber diese müssten vorher darauf trainiert werden - ein Henne-Ei-Problem. Videotraining wird als eine mögliche Lösung angesehen, da KI-Modelle anhand von Videodaten lernen könnten, wie Menschen mit ihrer Umwelt interagieren, und diese Fähigkeiten dann auf Roboter übertragen könnten.
Vision-Robotics Bridge entwickelt ein Affordanzmodell für Roboter
Vision-Robotics Bridge verwendet Videos menschlichen Verhaltens, um ein Modell der visuellen Affordanz zu trainieren. Der Begriff Affordanz wurde von dem amerikanischen Psychologen James J. Gibson geprägt und beschreibt, was eine Umgebung einem Individuum anbietet. Im Deutschen spricht man daher auch vom Angebotscharakter. Dahinter steht die Vorstellung, dass Lebewesen beispielsweise einen Fluss nicht einfach als fließendes Wasser wahrnehmen, sondern als Möglichkeit zu trinken.
Das Team der Carnegie Mellon University und Meta AI orientiert sich an diesem Konzept und definiert Affordanz im Kontext der Robotik als die Summe aus Kontaktpunkt und Bewegungsrichtung nach dem Kontakt. Das KI-Modell lernt also aus Videos, Objekte möglicher Handlungen sowie mögliche Bewegungsmuster nach dem Ergreifen eines Objekts zu identifizieren.
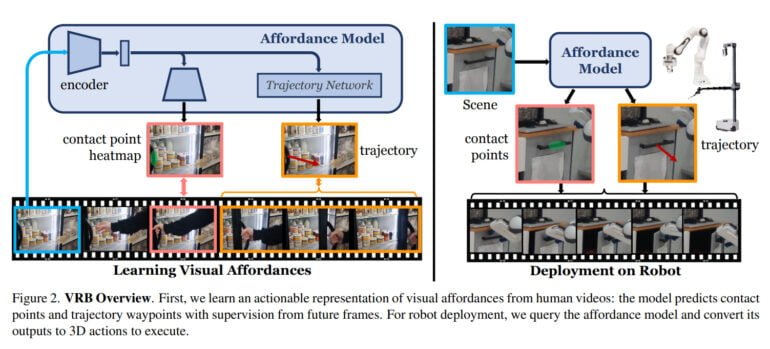
So lernt es beispielsweise, dass ein Kühlschrank am Griff geöffnet wird und in welche Richtung eine Person daran zieht. Bei einer Schublade erkennt es den Griff und lernt die einzig richtige Bewegungsrichtung, um die Schublade zu öffnen.
Video: CMU / Meta
Video: CMU / Meta
VRB bewährt sich in 200 Stunden Tests in der echten Welt
In der Robotik zielt VRB darauf ab, einem Roboter eine kontextualisierte Wahrnehmung zu geben, die ihm hilft, seine Aufgaben schneller zu erlernen. Das Team zeigt, dass VRB mit vier verschiedenen Lernparadigmen kompatibel ist, beschreibt diese und setzt VRB in vier realen Umgebungen in mehr als zehn verschiedenen Aufgaben mit zwei verschiedenen Roboterplattformen ein.

In umfangreichen Experimenten, die sich über mehr als 200 Stunden erstreckten, zeigte das Team, dass VRB bisherigen Ansätzen weit überlegen ist. In Zukunft wollen die Forschenden ihre Methode auf komplexere, mehrstufige Aufgaben anwenden, physische Konzepte wie Kraft und taktile Informationen einbeziehen und die von VRB gelernten visuellen Repräsentationen untersuchen.
Mehr Informationen gibt es auf der VRB-Projektseite. Dort sollen bald auch der Code und Datensatz verfügbar sein.





