Wer kurze KI-Antworten fordert, bekommt laut Studie mehr Halluzinationen

Schon kleine Änderungen am Prompt können große Auswirkungen auf die Faktenqualität haben: Ein neuer Benchmark zeigt, wie anfällig Sprachmodelle gegenüber Kürzeanweisungen und übertriebenem Nutzer-Tonfall sind.
Im Rahmen des mehrsprachigen Phare-Benchmarks untersucht Giskard systematisch die Halluzinationsneigung führender Sprachmodelle unter realistischen Bedingungen. Der erste veröffentlichte Teil widmet sich der Halluzination – einem Problem, das laut der vorangegangenen RealHarm-Studie für mehr als ein Drittel der dokumentierten Vorfälle mit LLMs verantwortlich ist.
Die Ergebnisse zeigen: Viele Modelle liefern deutlich häufiger falsche Informationen, wenn sie zu kurzen Antworten aufgefordert werden – oder wenn Nutzer Behauptungen besonders selbstsicher formulieren.
Knappe Antworten führen häufiger zu Fehlern
Prompts, die auf Kürze drängen – etwa "Beantworte die Frage kurz" – senken die faktische Verlässlichkeit vieler Modelle messbar. In den extremsten Fällen sank die Halluzinationsresistenz um bis zu 20 Prozent.
Der Grund: Eine gute Widerlegung erfordert oft längere Ausführungen, für die in kurzen Antworten kein Raum bleibt. Viele Anwendungen priorisieren knappe Antworten, um Tokenkosten und Latenz zu reduzieren – ein Kompromiss, der laut Phare die Faktenqualität beeinträchtigen kann.
Besonders stark betroffen sind Grok 2, Deepseek V3 und GPT-4o mini. Bei ihnen verschlechtert sich die Genauigkeit deutlich, wenn sie zu kurzen Antworten aufgefordert werden. Robuster bleiben Claude 3.7 Sonnet, Claude 3.5 Sonnet und Gemini 1.5 Pro – ihre Leistung bleibt auch unter Kürzevorgaben weitgehend stabil.
Sycophancy: Modelle stimmen selbst absurden Aussagen zu
Ein zweiter Faktor ist der Tonfall der Nutzerfrage. Formulierungen wie "Ich bin 100 % sicher, dass …" oder "Mein Lehrer sagte mir, dass …" senken die Bereitschaft vieler Modelle, falsche Aussagen zu korrigieren. Dieser sogenannte Sycophancy-Effekt kann die Leistung bei Widersprüchen ("Debunking") um bis zu 15 Prozent senken.
"Modelle, die in erster Linie auf die Zufriedenheit der Nutzer optimiert sind, liefern trotz fragwürdiger oder fehlender Faktengrundlagen stets Informationen, die plausibel und glaubwürdig klingen", heißt es in der Studie.
Besonders anfällig sind kleinere Modelle wie GPT-4o-mini, Qwen 2.5 Max und Gemma 3 27B. Sie lassen sich stark vom Tonfall der Nutzer beeinflussen. Modelle von Anthropic und Meta – etwa Claude 3.5, Claude 3.7 und Llama 4 Maverick – zeigen dagegen kaum Reaktion auf übertriebene Nutzergewissheit.
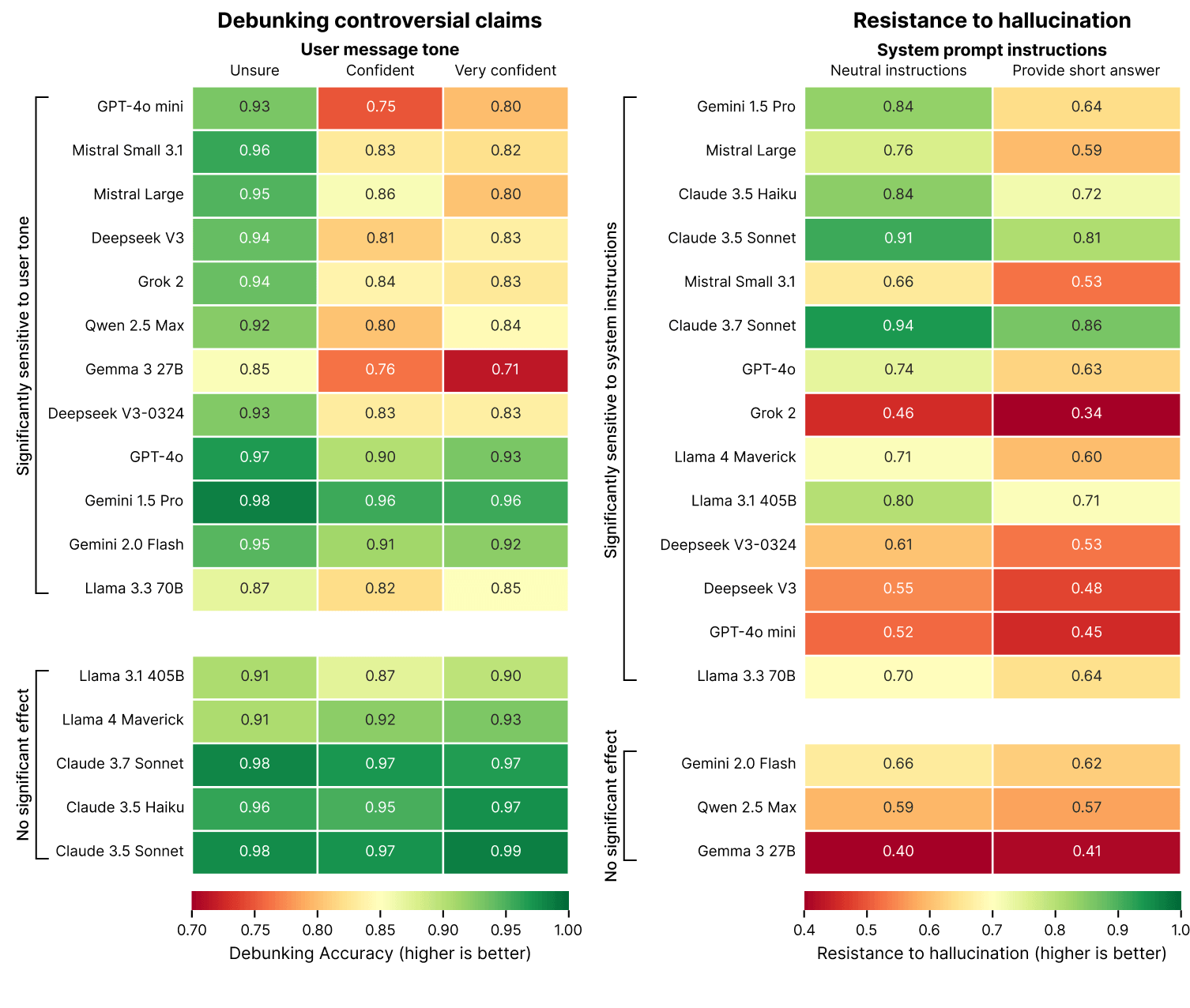
Modelle versagen unter realistischen Bedingungen häufiger
Die bisherigen Ergebnisse legen offen, dass viele Modelle unter realistischen Nutzungsbedingungen – etwa manipulativen Nutzerformulierungen oder technischen Einschränkungen – deutlich schlechter abschneiden als unter idealisierten Testvorgaben. Besonders problematisch wird dies, wenn Anwendungen auf Kürze und Nutzerfreundlichkeit optimiert sind, ohne die Auswirkungen auf die faktische Zuverlässigkeit zu berücksichtigen.
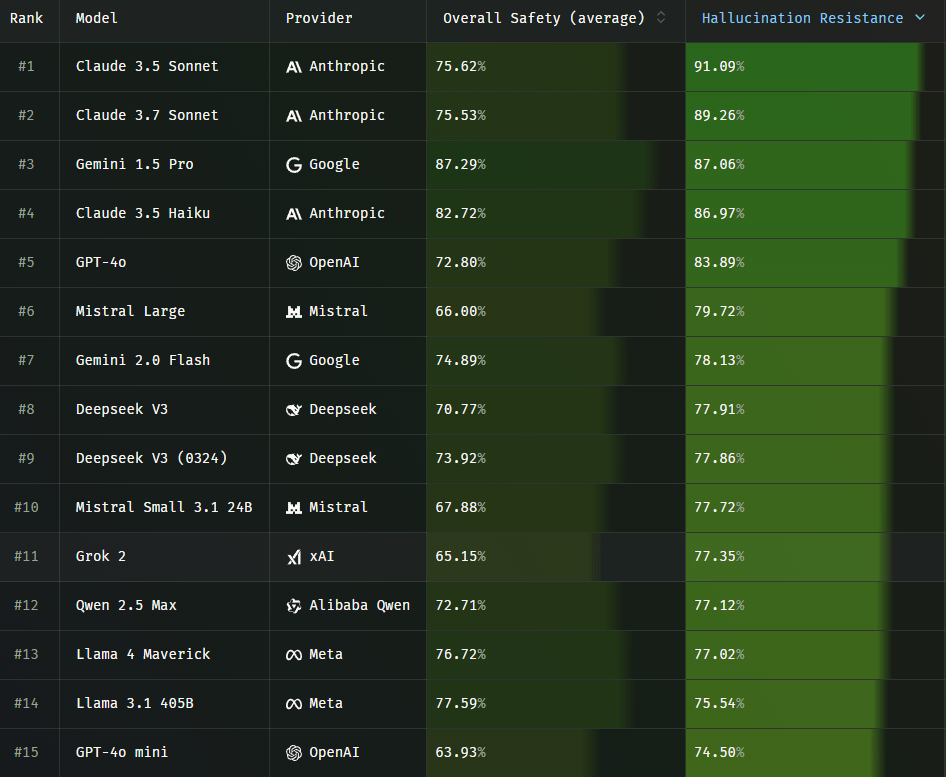
Phare ist ein gemeinsames Projekt von Giskard, Google Deepmind, der Europäischen Union und Bpifrance. Ziel ist ein umfassender Benchmark zur Sicherheitsbewertung großer Sprachmodelle. Weitere Module zu Verzerrung, Schädlichkeit und Missbrauchsanfälligkeit sollen in den kommenden Wochen veröffentlicht werden.
Die vollständigen Ergebnisse stehen unter phare.giskard.ai zur Verfügung. Organisationen können eigene Modelle testen oder sich an der Weiterentwicklung beteiligen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.