OpenAI hat eine neue Methode entwickelt, um die internen Repräsentationen von GPT-4 in 16 Millionen "häufig interpretierbare" Muster zu zerlegen. Die Ergebnisse sollen helfen, die Sicherheit und Robustheit von KI-Modellen besser zu verstehen.
Trotz vieler Fortschritte in Forschung und Entwicklung sind große KI-Modelle immer noch sogenannte "Black Boxes" - sie funktionieren, aber wie genau, weiß man bisher nicht.
OpenAI stellt nun eine Methode vor, um eine große Anzahl von "Features" zu finden - Aktivitätsmuster in künstlichen neuronalen Netzen, die im Idealfall von Menschen interpretiert werden können.
OpenAI verwendet dazu sogenannte Sparse Autoencoder. Ein Autoencoder ist selbst ein neuronales Netz, das lernt, seinen Input so genau wie möglich zu rekonstruieren. OpenAI verwendet die internen Aktivierungen von GPT-4 als Input für den Autoencoder.
Der Autoencoder muss dann lernen, die komplexen Aktivierungsmuster in kompaktere, interpretierbare Merkmale zu zerlegen. Eine "spärliche" Darstellung, bei der die meisten Merkmale inaktiv und nur wenige aktiv sind, soll die Interpretierbarkeit erleichtern. Dafür muss der Autoencoder die wichtigsten Merkmale herausfiltern und kompakt codieren.
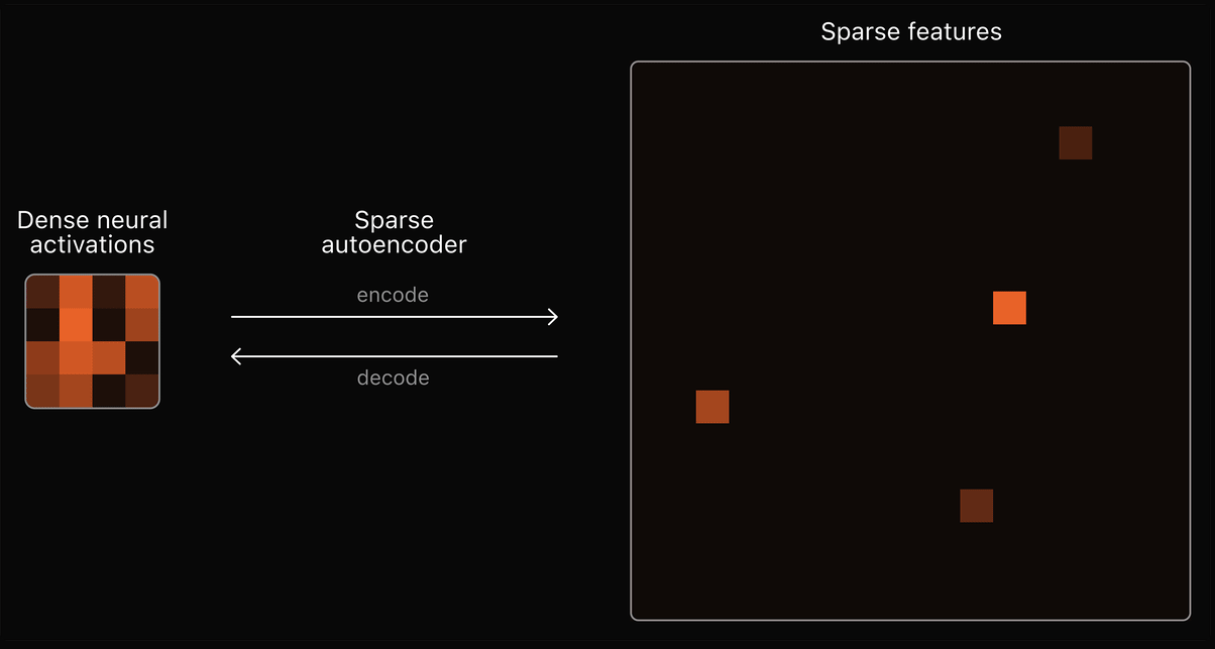
Jedes im Autoencoder gelernte Merkmal entspricht dann im Idealfall einem für Menschen verständlichen Konzept, das GPT-4 intern verwendet, z.B. bestimmte grammatikalische Strukturen, Weltwissen oder logische Schlussfolgerungen.
Die Analyse der gelernten Merkmale erlaubt dann Rückschlüsse darauf, wie GPT-4 "denkt", so die Theorie.
OpenAI skaliert das Analysewerkzeug
Die große Herausforderung besteht darin, dass GPT-4 wahrscheinlich Millionen oder sogar Milliarden solcher Konzepte verwendet. Frühere Autoencoder waren zu klein, um diese große Anzahl von Merkmalen zu verarbeiten.
OpenAI hat nun eine Methode entwickelt, mit der diese Autoencoder auf Millionen von Merkmalen skaliert werden können. Konkret wurde ein Autoencoder mit 16 Millionen Merkmalen für GPT-4 trainiert.
Das Unternehmen hat in der Tat spezifische Merkmale in GPT-4 entdeckt, wie menschliche Unzulänglichkeiten, Preiserhöhungen, ML-Trainingsprotokolle oder algebraische Ringe. Viele dieser Merkmale seien jedoch schwer zu interpretieren oder zeigten für das repräsentierte Konzept irrelevante Aktivierungen.
Außerdem bildet der Sparse Autoencoder nicht das gesamte Verhalten des Originalmodells ab. Um alle Konzepte vollständig abzubilden, müsste er auf Milliarden oder Billionen von Merkmalen skaliert werden.
OpenAI hat das Paper veröffentlicht, den Quellcode bei Github freigegeben und einen interaktiven Visualizer für die gelernten Merkmale des Autoencoders zur Verfügung gestellt.
Ähnliche Untersuchungen zur Interpretierbarkeit eines Sprachmodells wurden kürzlich vom OpenAI-Wettbewerber Anthropic vorgestellt, der unter anderem zeigen konnte, dass Claudes LLMs Konzepte für die Golden Gate Bridge enthalten. Wenn diese verstärkt werden, beantwortet das Modell alle Fragen aus der Perspektive der Brücke.
Das zeigt, wie ein besseres Verständnis der Modelle direkte Auswirkungen auf deren Funktion haben kann. Es geht also nicht allein um Sicherheit und Ethik. Wie OpenAI kam auch Anthropic zu dem Schluss, dass die Skalierung der Analysemethode die größte Herausforderung darstellt. Die benötigte Rechenleistung würde den Rechenaufwand für das Modelltraining um ein Vielfaches übersteigen.