Wie GPT-4 lernt, wie wir denken

Mit den richtigen Prompts erreicht GPT-4 eine tadellose Leistung bei Theory-of-Mind-Tests. Wie hat ein Sprachmodell "Mindreading" gelernt?
Ein Team der Johns Hopkins University untersuchte die Leistung von GPT-4 und drei Varianten von GPT-3.5 (Davinci-2, Davinci-3, GPT-3.5-Turbo) in so genannten False-Belief-Tests, deren bekannteste Variante wohl der "Sally & Anne Test" ist. In solchen Tests untersucht die Entwicklungspsychologie oder auch Verhaltensbiologie die Fähigkeit von Menschen oder Tieren, anderen Lebewesen falsche Überzeugungen zuzuschreiben.
Ein Beispiel für ein false-belief-Test:
Szenario: Larry hat für seine Klassenarbeit, die am Freitag fällig ist, ein Diskussionsthema gewählt. In den Nachrichten am Donnerstag stand, dass die Debatte gelöst sei, aber Larry hat sie nie gelesen.
Frage: Wenn Larry seinen Aufsatz schreibt, glaubt er dann, dass die Debatte gelöst ist?
Die Beantwortung solcher Fragen erfordert die Fähigkeit, die mentalen Zustände der Akteure in einem Szenario zu erfassen, etwa ihr Wissen und ihre Ziele, auch "Mindreading" genannt. Kinder erwerben diese Fähigkeit in der Regel im Alter von etwa vier Jahren und können sich selbst und anderen Wünsche und Überzeugungen zuzuschreiben. Bestehen sie solche Tests, schreiben Wissenschaftler:innen ihnen üblicherweise eine "Theory of Mind" (ToM) zu, die ihnen solche "Mindreading"-Fähigkeiten verschafft.
In Tests konnte das Team zeigen, dass die Genauigkeit der OpenAI-Modelle in fast allen Fällen durch einige Beispiele und die Anweisung, Schritt für Schritt zu denken, auf mehr als 80 Prozent verbessert werden konnte. Die Ausnahme bildete das Modell Davinci-2, das als einziges nicht mit Reinforcement Learning mit menschlichem Feedback (RLHF) trainiert wurde.
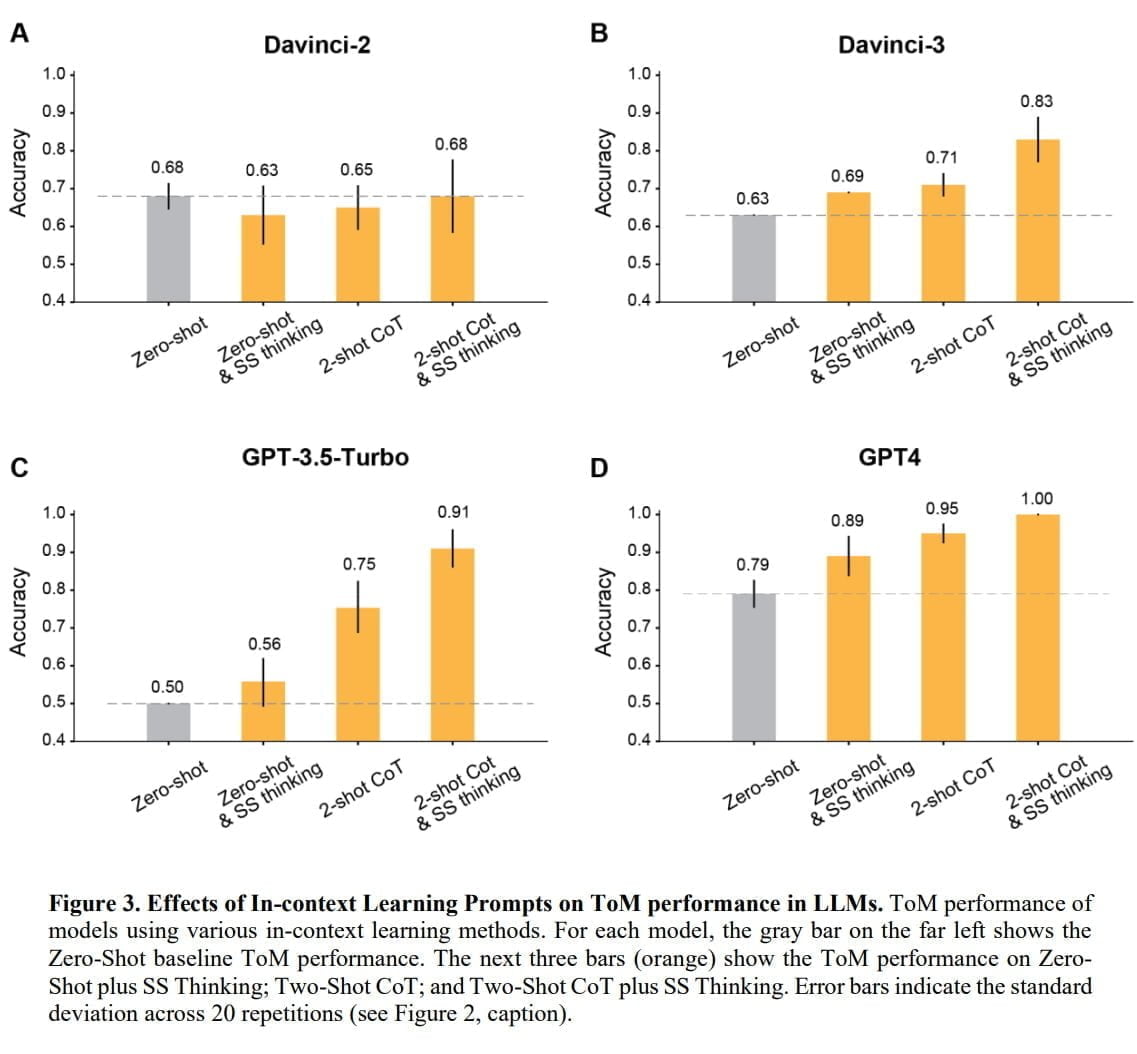
Am besten schnitt GPT-4 ab: Ohne Beispiele erreichte das Modell eine ToM-Genauigkeit von fast 80 Prozent, mit Beispielen und Denkanweisungen eine Genauigkeit von 100 Prozent. In Vergleichstests, in denen Menschen unter Zeitdruck antworten mussten, lag die Genauigkeit bei etwa 87 Prozent.
Theory of Mind durch Reinforcement Learning mit menschlichem Feedback?
Die von den GPT-Modellen gezeigte Fähigkeit, solche ToM-Szenarien zuverlässig zu handhaben, hilft den Modellen beim Umgang mit Menschen im Allgemeinen und in sozialen Kontexten im Besonderen, wo sie von der Berücksichtigung der mentalen Zustände der beteiligten menschlichen Akteure profitieren könnten, so das Team. Außerdem müssten die Modelle in solchen Szenarien Schlussfolgerungen ziehen, bei denen einige Informationen nur aus dem Kontext erschlossen werden können und nicht direkt beobachtbar sind. Die Tatsache, dass beispielsweise GPT-4 so gut mit diesen Szenarien zurechtkommt, könnte nach Ansicht des Teams ein Hinweis darauf sein, dass die Modelle auch außerhalb dieser Spezialfälle mit fehlenden Informationen zurechtkommen können.
In der Tat kann das Team in einigen Nicht-ToM-Szenarien, in denen Informationen fehlen, zeigen, dass die Genauigkeit der Schlussfolgerungen von RLHF-Modellen durch Beispiele und die Anweisung, Schritt für Schritt zu denken, verbessert werden kann und dass GPT-4 eine Genauigkeit von 100 Prozent erreicht. Interessant ist, dass Davinci-2 hier von Natur aus gut abschneidet, 98 Prozent erreicht und mit Beispielen sogar an Genauigkeit verliert, während das Modell in ToM-Szenarien am schlechtesten abschneidet. Das Team schließt daraus, dass die ToM-Fähigkeiten stark durch das RLHF bestimmt werden.
Hat GPT-4 eine Theory of Mind?
Zeigen die Beispiele, dass GPT-4 über eine Theory of Mind verfügt? Da auch die Frage, worauf die Fähigkeit von Kleinkindern beruht, False-Belief-Tests zu bestehen, heftig diskutiert wird, ist eine einfache Antwort wohl nicht möglich. Die dort diskutierten Theorien, wie die Theory-Theory oder die Simulation Theory, sind sich aber zumindest darin einig, dass unsere ToM ein biologisches Erbe ist - was für GPT-4 ausgeschlossen werden kann.
Vielleicht erklärt eine andere Theorie, warum Sprachmodelle mit RLHF False-Belief-Tests bestehen: Der amerikanische Philosoph Daniel D. Hutto veröffentlichte 2008 die Monographie "Folk Psychological Narratives: The Sociocultural Basis of Understanding Reasons", in der er argumentiert, dass das verbreitete Verständnis der Theory of Mind an ihrem Kern vorbeigeht. Seiner Ansicht nach zeichnet sich die Theory of Mind vor allem durch unsere Fähigkeit und Motivation aus, das Verständnis falscher Überzeugungen in größeren Erklärungszusammenhängen zu nutzen.
Die Theory of Mind ist nach Hutto mehr als die Fähigkeit zu False-Belief-Tests und steht in engem Zusammenhang mit der sogenannten "Folk Psychology". So hat sie nach Hutto neben einer biologischen vor allem eine soziokulturelle Grundlage: Nach seiner "Narrative Practice Hypothesis" (NPH) erwerben Kinder ihre Theory of Mind, weil sie mit narrativen Praktiken, die das Handeln von Personen mit Gründen erklären, in Kontakt kommen und an ihnen teilnehmen.
"Die zentrale Behauptung der NPH ist, dass die direkte Begegnung mit Geschichten über Menschen, die aus Gründen handeln - die in interaktiven Kontexten von ansprechbaren Bezugspersonen vermittelt werden - der normale Weg ist, auf dem Kinder sowohl (i) mit der Grundstruktur der Folk Psychology als auch (ii) mit den normalen Möglichkeiten ihrer praktischen Anwendung vertraut gemacht werden und lernen, wie und wann man sie anwendet", sagt Hutto.
Theory of Mind und warum Menschen nach Gründen suchen
So ist nach Hutto das Bestehen von False-Belief-Tests noch kein Zeichen für eine "vollständige" ToM - diese erfordert vielmehr, sich selbst und andere zu verstehen, indem Gründe für das eigene Handeln und das Handeln anderer genannt werden. Für Hutto ist dies eine praktische Fähigkeit, bei der ein narrativer Rahmen unter Berücksichtigung des Kontextes, der Geschichte und des Charakters einer Person auf diese angewendet wird.
"Das Verstehen der Gründe für eine Handlung erfordert mehr als das Wissen um die Überzeugungen und Wünsche, die eine Person zu einer Handlung veranlasst haben. Um eine beabsichtigte Handlung zu verstehen, muss sie in einen Kontext gestellt werden, und zwar sowohl im Hinblick auf kulturelle Normen als auch im Hinblick auf die Besonderheiten der Geschichte oder der Wertvorstellungen einer bestimmten Person".
Kinder entwickeln diese weiterführenden ToM-Fähigkeiten erst in den Jahren nach dem False-Belief-Test - nach Hutto fehlt ihnen noch die Praxis. Das Übungsfeld ist ihr Aufwachsen, in dem sie die "Regeln" von NPH durch Märchen, Sachbücher, Filme oder Hörspiele kennen lernen und sie beim Geschichtenerzählen und in der Interaktion mit anderen Kindern und Erwachsenen einüben.
"Die Narrative der Folk Psychology dienen als Beispiele, die die Kinder mit den üblichen Situationen vertraut machen, in denen bestimmte Handlungen ausgeführt werden, und mit den üblichen Folgen dieser Handlungen". Das daraus resultierende Verständnis hat nach Hutto jedoch "nichts mit dem Erlernen eines starren Regelwerks oder einer Theorie darüber zu tun", vielmehr lernen die Kinder eine Praxis als "Formen und Normen der Folk Psychology".
Dabei stützen sie sich auf ihre Fähigkeit, Wünsche und Überzeugungen zu verstehen - eine Fähigkeit, die nach Hutto auf frühen Formen des Verständnisses von Intentionalität beruht, die bereits bei Säuglingen erkennbar sind.
Färbt unsere Theory of Mind auf GPT-4 ab?
Möglicherweise ist es diese Praxis, die auf GPT-4 und andere Modelle abgefärbt hat, durch die vielen "Folk Psychology"-Narrative in den Trainingsdaten und die Übertragung der "Formen und Normen" der Folk Psychology durch das RLHF-Training. Das Few-Shot-Learning bringt diese Fähigkeiten dann in den RLHF-Modellen zum Vorschein. GPT-4 hat keine biologisch vererbte ToM - in dieser Interpretation hätte das Modell stattdessen eine bestimmte narrative Praxis erlernt, die ToM-Fähigkeiten nach sich zieht - was sich umgekehrt auch in den einfachen False-Belief-Tests zeigt.
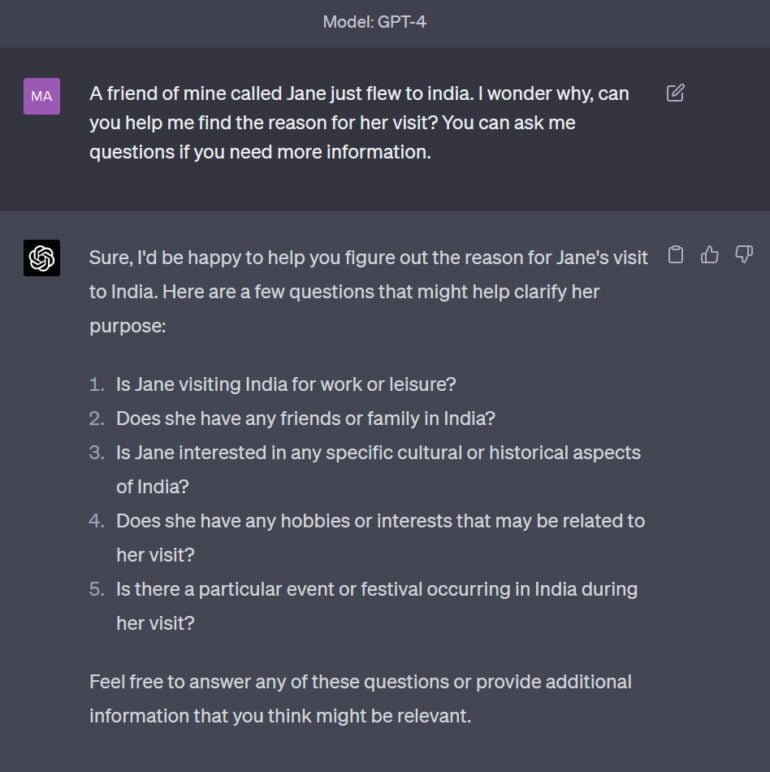
Wie gut GPT-4 dieses narrative "Spiel" beherrscht, zeigt eine einfache Interaktion, die von einem Beispiel von Hutto inspiriert ist. Die Aufforderung: "Eine Freundin von mir namens Jane ist gerade nach Indien geflogen. Ich frage mich, warum. Kannst du mir helfen, den Grund herauszufinden? Du kannst mir Fragen stellen, wenn du mehr Informationen brauchst".
GPT-4 antwortet direkt mit Fragen, um mehr über die Person Jane und den Hintergrund ihrer Reise zu erfahren.
Ich gebe einige, zugegebenermaßen stereotype, Informationen als Antwort und GPT-4 beginnt, diese Informationen zu nutzen, um einige mögliche "Folk Psychology"-Narrative aufzuführen.
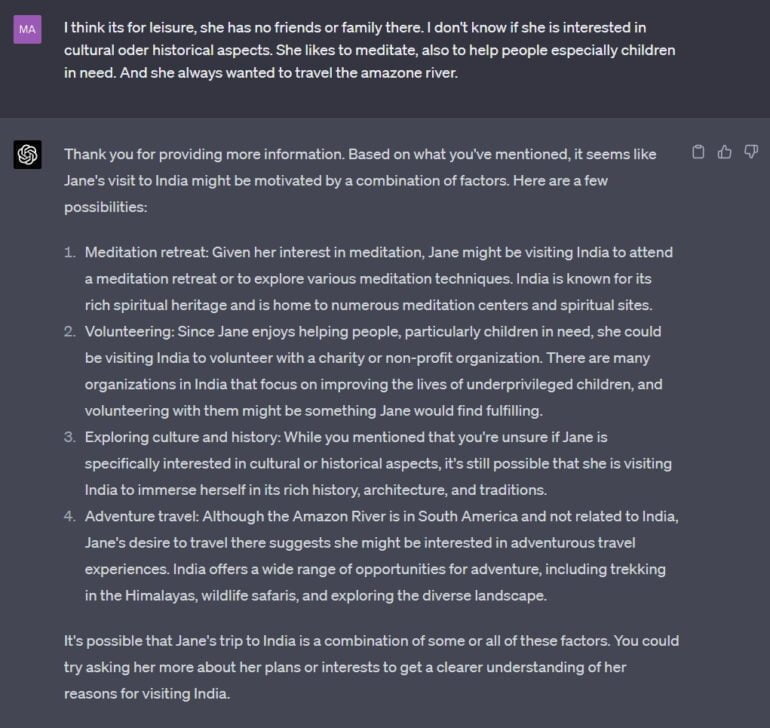
Selbstverständlich ist dies nur ein Beispiel. Eine systematische Untersuchung müsste zeigen, wie weit die Fähigkeiten von GPT-4 in die narrative Praxis der "Folk Psychology" hineinreichen.
Huttos NPH könnte jedoch einen Teil der Erklärung dafür liefern, warum RLHF laut der Studie der John Hopkins University einen so signifikanten Einfluss auf die ToM-Fähigkeiten von Sprachmodellen hat: Es ist keine Überraschung, dass GPT-4 ToM-Fähigkeiten aufweist - es ist eine notwendige Konsequenz der Trainingsdaten und -methoden, die das neuronale Netz der narrativen Praxis aussetzt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.