Anthropic bereitet Opus 4.7 und KI-Design-Tool vor, VCs bieten bis zu 800 Milliarden Dollar
Anthropic plant die Veröffentlichung eines neuen Modells und eines Design-Tools, das Adobe und Figma Konkurrenz machen soll. Gleichzeitig überbieten sich Risikokapitalgeber mit Bewertungsangeboten.
Microsoft erweitert Copilot in Word um neue Funktionen, die sich laut dem Unternehmen an Fachleute aus den Bereichen Recht, Finanzen und Compliance richten. Copilot kann nun Änderungen auf Wortebene nachverfolgen (Track Changes), sodass Bearbeitungen transparent und prüfbar bleiben. Außerdem lassen sich Kommentare direkt im Text verwalten, Inhaltsverzeichnisse einfügen und Kopf- sowie Fußzeilen mit dynamischen Feldern wie Seitenzahlen anlegen.
Bei mehrstufigen Bearbeitungen zeigt Copilot in Echtzeit an, woran es gerade arbeitet. Laut Microsoft basieren die Funktionen auf "Work IQ", einer Ebene, die Antworten an den jeweiligen Nutzer und dessen Organisation anpasst. Die Daten bleiben innerhalb der Microsoft-365-Sicherheitsgrenzen. Die neuen Funktionen sind zunächst nur auf dem Windows-Desktop über das Frontier-Programm im Office Insiders Beta-Channel verfügbar. Versionen für Web und Mac sollen folgen.
OpenAIs Stargate-Offensive in Europa schrumpft und Microsoft und Google übernehmen die Kapazitäten.
"Ich habe immer gesagt, dass wir Stargate gerne nach Europa bringen würden, wenn die Bedingungen stimmen, und wir glauben, dass wir das in Narvik gefunden haben", erklärte OpenAI-CEO Sam Altman im Juli 2025. Wenige Monate später ist von diesem Optimismus wenig übrig: OpenAI hat weder den Vertrag für das norwegische Rechenzentrum am Polarkreis abgeschlossen noch hält es an seinem britischen Stargate-Projekt fest. Beide Standorte wurden vom Neocloud-Anbieter Nscale entwickelt.
Microsoft springt ein und mietet 30.000 Nvidia-Vera-Rubin-Chips in Narvik, zusätzlich zu einem bestehenden 6,2-Milliarden-Dollar-Deal. Das Londoner Nscale-Rechenzentrum geht laut Bloomberg an Google. OpenAIs Infrastrukturversprechen von einst 1,4 Billionen Dollar schrumpft damit auf eine konkretere Prognose von 600 Milliarden Dollar bis 2030.
OpenAIs Modell GPT-5.4 Pro hat offenbar das offene Mathematikproblem Erdős #1196 gelöst. Das Modell soll die Lösung in etwa 80 Minuten gefunden und in weiteren 30 Minuten als LaTeX-Arbeit aufbereitet haben. Eine formale Verifikation sei in Arbeit.
Der Mathematiker Terence Tao kommentierte im Erdős-Problems-Forum, die Arbeit zeige eine bisher nicht explizit beschriebene Verbindung zwischen der Anatomie ganzer Zahlen und der Theorie von Markov-Prozessen. Er bezeichnete das als sinnvollen Beitrag, der über die Lösung des einzelnen Problems hinausgehe. Kevin Barreto, der laut eigenen Angaben bald dem AI-for-Science-Team bei OpenAI beitreten wird, merkte im selben Forum an, die verwendete Markov-Ketten-Technik sei ein kreativer Schritt, den menschliche Mathematiker trotz langer Beschäftigung mit dem Problem übersehen hätten.
Die Diskussion ist insofern relevant, als bei LLMs gerade in der Mathematik immer wieder über deren Fähigkeit diskutiert wird, kreative Ansätze jenseits der beim Training gelernten Datenpunkte zu entwickeln. Sie zeigt, dass auch innerhalb bekannter Datenpunkte neues, aber noch nicht beschriebenes Wissen schlummern kann.
OpenAI bringt spezielles Cyber-Sicherheitsmodell heraus und weitet Zugang für Verteidiger aus
OpenAI veröffentlicht mit GPT-5.4-Cyber ein Modell, das gezielt für defensive Cybersicherheit trainiert wurde. Der Zugang bleibt vorerst auf verifizierte Sicherheitsexperten beschränkt.
OpenAI-Präsident sieht radikalen Wandel durch KI und warnt vor disruptiven Folgen für Jobs
KI-Arbeit soll künftig nicht mehr bedeuten, sich an den Computer anzupassen. Der Computer passt sich an den Menschen an, sagt OpenAI-Präsident Greg Brockman. „Das ist disruptiv. Institutionen werden sich verändern.“
Google führt mit "Skills" eine neue Funktion in Chrome ein, mit der Nutzer häufig verwendete KI-Prompts speichern und per Klick wiederverwenden können. Bisher musste man denselben Prompt jedes Mal neu eingeben, etwa um Rezepte vegan umzuschreiben. Mit Skills lässt sich ein solcher Prompt direkt aus dem Chatverlauf speichern und über einen Schrägstrich ( / ) oder das Plus-Zeichen ( + ) in Gemini in Chrome aufrufen. Die Funktion arbeitet auch über mehrere Tabs hinweg. Google stellt zusätzlich eine Bibliothek mit fertigen Skills bereit, etwa für Produktvergleiche, Mahlzeitenplanung oder Geschenkauswahl. Nutzer können diese anpassen oder eigene erstellen.
Skills nutzen laut Google die bestehenden Sicherheits- und Datenschutzfunktionen von Chrome und fragen vor bestimmten Aktionen wie dem Versenden von E-Mails um Erlaubnis. Die Funktion ist ab sofort auf Mac, Windows und ChromeOS verfügbar, allerdings nur für Nutzer, deren Chrome-Sprache auf Englisch (US) eingestellt ist.
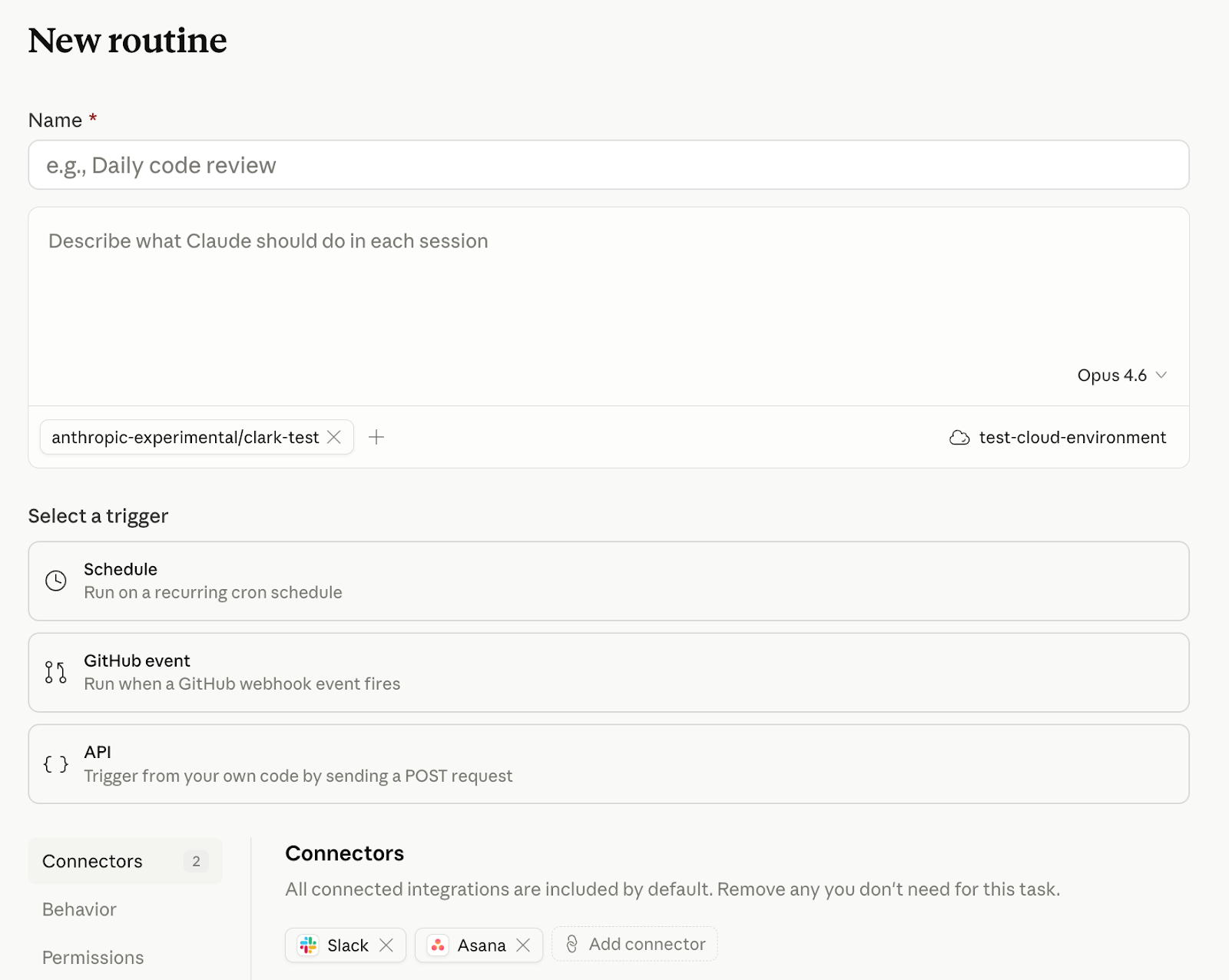
Anthropic hat für Claude Code sogenannte "Routines" vorgestellt, also automatisierte Abläufe, die eigenständig Fehler beheben, Pull Requests prüfen oder auf Ereignisse reagieren können. Routines werden einmal konfiguriert und laufen dann zeitgesteuert, per API-Aufruf oder als Reaktion auf GitHub-Ereignisse auf Anthropics Web-Infrastruktur, unabhängig vom eigenen Rechner.
Typische Anwendungen sind etwa das nächtliche Sortieren und Zuweisen neuer Fehlerberichte, automatische Code-Reviews nach teamspezifischen Checklisten, das Portieren von Änderungen zwischen Programmiersprachen oder das Prüfen von Deployments auf Fehler. Routines greifen auf bestehende Repository-Anbindungen und Konnektoren zu. Die Funktion ist als Forschungsvorschau für die Tarife Pro, Max, Team und Enterprise verfügbar, mit täglichen Limits von 5 bis 25 Ausführungen je nach Plan. Weitere Webhook-Quellen neben GitHub sollen folgen.
Nutzer vergeben einen Namen, beschreiben die Aufgabe, wählen einen Trigger (Zeitplan, GitHub-Event oder API) und verbinden externe Dienste wie Slack oder Asana.
Ukrainische Bodenroboter erobern erstmals feindliche Stellung ohne einen einzigen Soldaten
Präsident Zelenskyy verkündet einen historischen Meilenstein: Eine russische Position wurde ausschließlich von unbemannten Systemen eingenommen. Ein CSIS-Bericht zeigt, wie KI die ukrainische Kriegsführung bereits verändert und wo (noch) die Grenzen liegen.