
3D-LLM integriert das Verständnis von 3D-Umgebungen in große Sprachmodelle und bringt so Chatbots aus der zwei- in die dreidimensionale Welt.
Große Sprachmodelle und multimodale Sprachmodelle können mit Sprache und 2D-Bildern umgehen, Beispiele sind etwa ChatGPT, GPT-4 oder Flamingo. Diesen Modellen fehlt jedoch ein echtes Verständnis von 3D-Umgebungen und physischen Räumen. Forschende haben jetzt einen neuen Ansatz namens 3D-LLMs vorgeschlagen, der dieses Problem lösen soll.
3D-LLMs sollen der KI eine Vorstellung von 3D-Räumen vermitteln, indem sie 3D-Daten wie Punktwolken als Eingabe verwenden. Auf diese Weise sollen multimodale Sprachmodelle Konzepte wie räumliche Beziehungen, physikalische Gegebenheiten und Affordanzen verstehen, die mit 2D-Bildern allein nur schwer zu erfassen sind. 3D-LLMs könnten somit KI-Assistenten in die Lage versetzen, besser in 3D-Welten zu navigieren, zu planen und zu handeln, beispielsweise in der Robotik und im Bereich der verkörperten KI.
Die Beziehung von 3D-Welt und Sprache
Um die Modelle zu trainieren, musste das Team eine ausreichende Anzahl von 3D- und natürlichsprachlichen Datenpaaren sammeln - solche Datensätze sind im Vergleich zu Bild-Text-Paaren im Internet begrenzt. Das Team entwickelte daher Prompting-Techniken für ChatGPT, um verschiedene 3D-Beschreibungen und Dialoge zu generieren.
Das Ergebnis ist ein Datensatz mit über 300.000 3D-Textbeispielen, die Aufgaben wie 3D-Beschriftungen, visuelle Antworten auf Fragen, Aufgabenzerlegung und Navigation abdecken. Beispielsweise wurde ChatGPT gebeten, eine 3D-Schlafzimmerszene zu beschreiben, indem Fragen zu den aus verschiedenen Blickwinkeln sichtbaren Objekten gestellt wurden.

Team verbindet Textbeschreibungen mit Punkten im 3D-Raum
Das Team entwickelte anschließend 3D-Feature-Extraktoren, um 3D-Daten in ein Format umzuwandeln, das mit vortrainierten 2D-Vision-Language-Modellen wie BLIP-2 und Flamingo kompatibel ist.
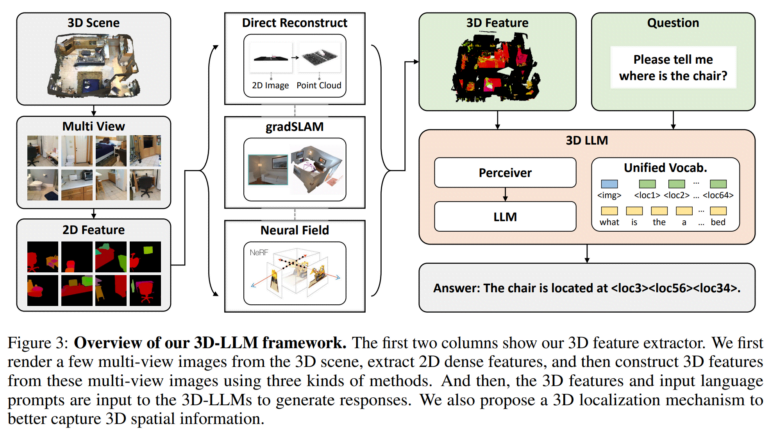
Zusätzlich verwenden die Forscher einen 3D-Lokalisierungsmechanismus, mit dem die Modelle räumliche Informationen erfassen können, indem sie Textbeschreibungen mit 3D-Koordinaten verknüpfen. Auch das vereinfacht die Nutzung von Modellen wie BLIP-2, um die 3D-LLMs effizient für das Verstehen von 3D-Szenen zu trainieren.
Tests mit 3D-Sprachmodell zeigen vielversprechende Ergebnisse
Experimente zeigten, dass die 3D-Sprachmodelle in der Lage sind, natürlichsprachliche Beschreibungen von 3D-Szenen zu generieren, 3D-bewusste Dialoge zu führen, komplexe Aufgaben in 3D-Aktionen zu zerlegen und Sprache auf räumliche Orte zu beziehen. Das zeige das Potenzial von KI, durch die Einbeziehung räumlicher Denkfähigkeiten eine menschenähnlichere Wahrnehmung von 3D-Umgebungen zu entwickeln.
Video: Hong et al.

Die Forscher planen, die Modelle um weitere Datenmodalitäten wie Ton zu erweitern und für weitere Aufgaben zu trainieren. Ziel sei es zudem, diese Fortschritte in verkörperten KI-Assistenten anzuwenden, die intelligent mit 3D-Umgebungen interagieren können.
Wer mehr über das Potenzial von Sprachmodellen für die Robotik erfahren möchte, kann sich unseren DEEP MINDS Podcast #15 mit dem Robotik-Experten Prof. Dr. Jan Peters anhören.




