SDFusion ist eine multimodale generative KI für 3D-Assets
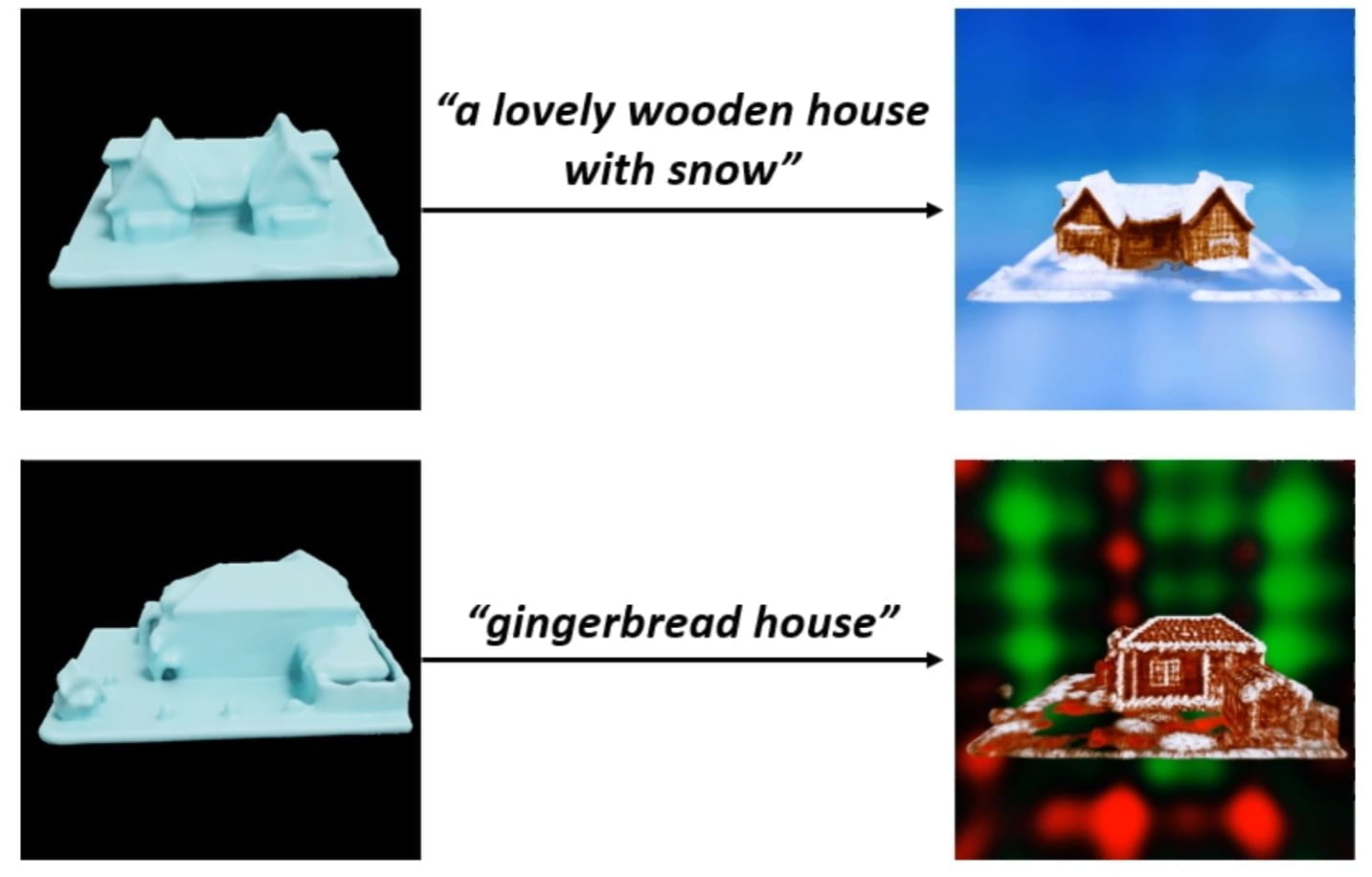
SDFusion ist ein KI-Framework für die Generierung von 3D-Assets, das Bilder, Text oder Formen als Input verarbeiten kann.
Generative KI-Modelle für 3D-Assets könnten Arbeitsabläufe in der Industrie verändern oder Design- und Programmier-Laien helfen, eigene virtuelle Objekte und Welten zu erstellen. Nvidia-CEO Jensen Huang etwa sieht diesen KI-gestützten Kreativprozess als zentral für die Metaverse-Zukunft an.
Aktuelle KI-Systeme verwenden neurale Rendermethoden wie NeRFs, die 3D-Objekte anhand verschiedener Kameraperspektiven lernen, oder diese, wie Googles Dreamfusion, per Text-Eingabe generieren. Andere Methoden wie CLIP-Mesh erstellen per Diffusionsmodellen Meshs aus Text-Eingaben.
Forschende der University of Illinois Urbana Champagin und Snap Research zeigen jetzt SDFusion, ein multimodales KI-Framework für 3D-Assets.
SDFusion verarbeitet Text, Bild und Formen
Bisherige 3D-KI-Modelle hätten zwar überzeugende Ergebnisse erzielt, das Training sei jedoch oft sehr zeitaufwendig und vernachlässige verfügbare 3D-Daten.
Das Team schlägt daher ein kollaboratives Paradigma für generative Modelle vor: Modelle, die auf 3D-Daten trainiert wurden, liefern eine detaillierte und genaue Geometrie. Modelle, die auf 2D-Daten trainiert wurden, liefern verschiedene Erscheinungsbilder.
Anknüpfend an diesem Paradigma entwickelte das Team SDFusion, ein Diffusions-basiertes generatives Modell für 3D-Assets, das zudem multimodalen Input wie Text, Bild oder 3D-Formen verarbeiteten kann. Die 3D-Objekte können durch das Zusammenspiel von generativen 3D- und 2D-KI-Modellen zusätzlich texturiert werden.
Video: Bild: Cheng et al.
SDFusion ermögliche es Nutzenden so, 3D-Assets mit unvollständigen Formen, Bildern und Textbeschreibungen gleichzeitig zu erstellen. Das erlaubt eine präzisere Steuerung des generativen Prozesses. Beispielsweise kann das Foto eines Stuhls mit einem einzelnen Standbein mit vier 3D-Asset-Stuhlbeinen zu einem Stuhl mit drei Beinen vermischt werden. Die Sitzschale aus dem Foto wird dabei übernommen.
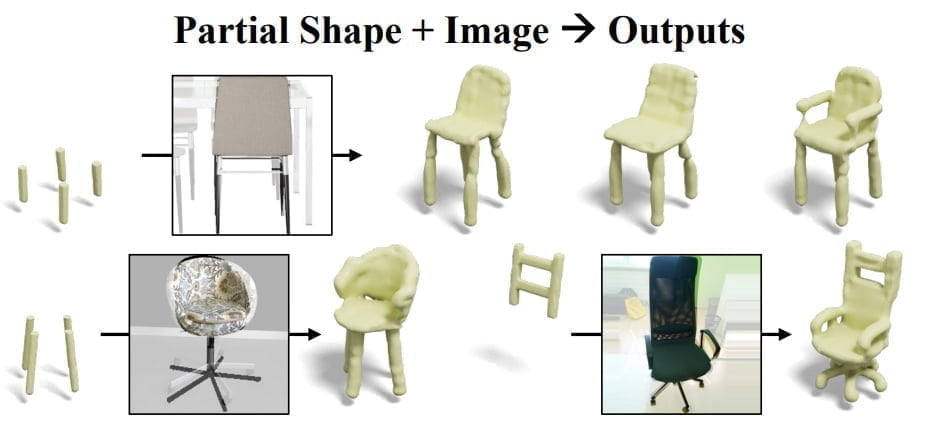
SDFusion lernt multimodal
Während des Trainings lernt SDFusions Diffusionsmodell von 3D-Modellen und über Encoder, die Text und Bilder verarbeiten können. Nach dem Training kann das Team zudem die Relevanz einzelner Inputs wie Textbeschreibung, Bild oder 3D-Form regulieren und so unterschiedliche 3D-Assets generieren.
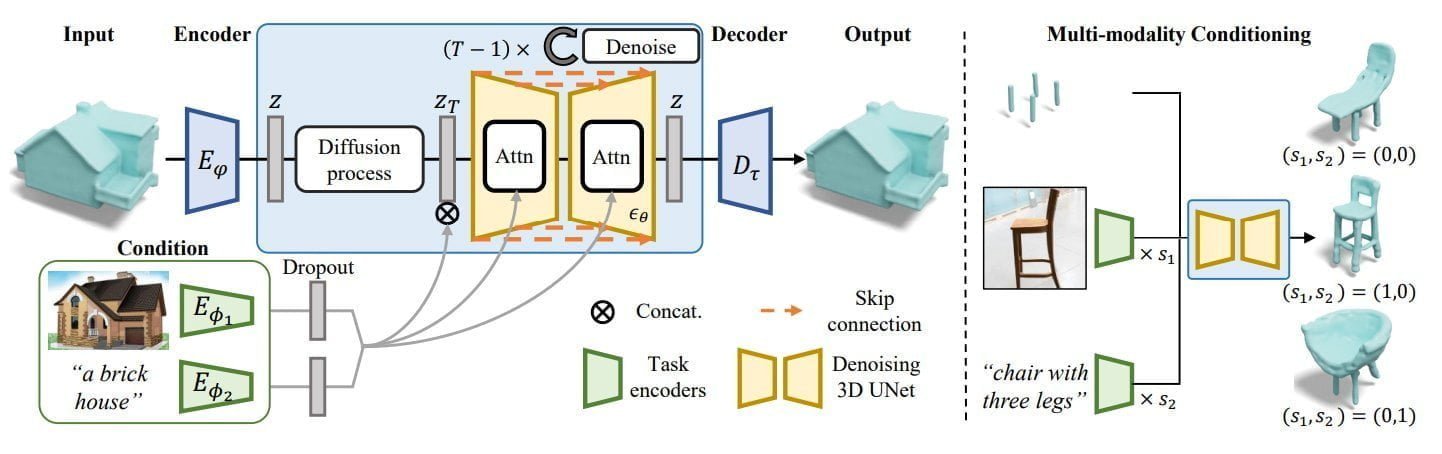
In Tests kann SDFusion vom Team getestete Alternativen abhängen: "SDFusion erzeugt Formen von besserer Qualität und Vielfalt, die gleichzeitig mit den eingegebenen Teilformen konsistent sind." Das gilt für die Vervollständigung von vorgegebenen Formen, der Single-View 3D-Rekonstruktion, der Text-geleiteten Generation und der Multi-konditionalen Generierung.
Trotz der guten Ergebnisse gäbe es jedoch noch viel zu verbessern, schreibt das Team. So sei ein Modell wünschenswert, das mit zahlreichen verschiedenen 3D-Darstellungen arbeiten könne. SDFusion arbeitet ausschließlich mit hochwertigen SDFs, ähnlich wie Nvidias 3D MoMa. Ein weiteres Forschungsfeld wäre zudem der Einsatz von SDFusion abseits einzelner 3D-Assets in anspruchsvolleren Szenarien wie der Generierung ganzer 3D-Szenen.
Mehr Informationen und Beispiele gibt es auf der Projektseite von SDFusion.
Wer mehr über die Zukunft der KI-Grafik lernen möchte, kann sich unseren DEEP MINDS Podcast mit Thomas Müller, KI-Forscher bei Nvidia, anhören.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.