Metas LLaMA Sprachmodell zeigt, dass Parameter nicht alles sind

Meta stellt die LLaMA-Sprachmodelle vor, die mit relativ wenigen Parametern wesentlich größere Sprachmodelle wie GPT-3 übertreffen können.
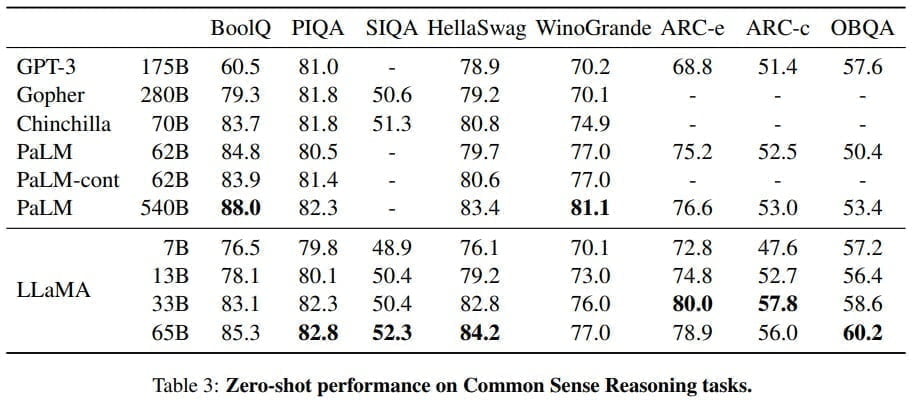
Metas KI-Forschungsabteilung veröffentlicht vier Foundation-Modelle zwischen 7 und 65 Milliarden Parametern. Bereits das 13-Milliarden-Modell "LLaMA" (Large Language Model Meta AI) soll bei "den meisten" Sprachaufgaben das Open-Source-Modell OPT von Meta sowie GPT-3 mit 175 Milliarden Parametern übertreffen.
Mehr Daten für bessere Ergebnisse
Das größte LLaMA-Modell mit 65 Milliarden Parametern soll sogar mit Googles riesigem 540-Milliarden-Modell Palm mithalten können und auf Augenhöhe mit Deepminds Chinchilla agieren.
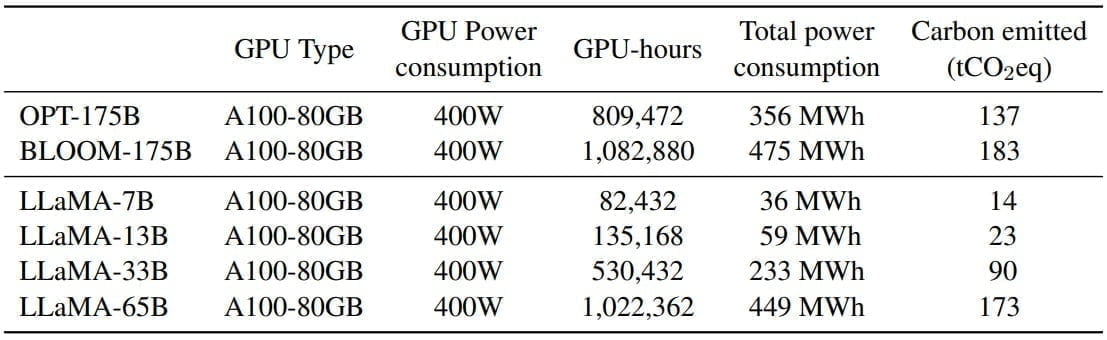
Der Trainingsaufwand und damit der CO₂-Verbrauch des LLaMA-Modells soll auf dem Niveau von 175-Milliarden-Modellen wie OPT und Bloom liegen. Der spätere Betrieb ist jedoch günstiger (siehe unten).
Der Vergleich mit Chinchilla ist insofern interessant, als Deepmind damals wie Meta heute bei LLaMA einen neuen Trainingsansatz gewählt hat, der auf einer größeren Anzahl von Trainingsdaten (Tokens) basiert als üblich. LLaMA ist sozusagen Metas Chinchilla, die Forschenden nennen das Modell explizit als Inspiration.
All our models were trained on at least 1T tokens, much more than what is typically used at this scale.
Interestingly, even after 1T tokens the 7B model was still improving.
3/n pic.twitter.com/qiXieIAKC6— Guillaume Lample (@GuillaumeLample) February 24, 2023
Die Tatsache, dass sich das Training mit mehr Daten in der Leistung widerspiegelt, zeigt, dass kleinere Modelle mit mehr Daten eine höhere Leistung erbringen können. Das Training ist zwar aufwendiger und teurer, aber der spätere Betrieb ist günstiger.
Das Ziel der Skalierungsgesetze von Hoffmann et al. (2022) ist es, die beste Skalierung des Datensatzes und der Modellgrößen für ein gegebenes Trainingsdatenbudget zu bestimmen. Dieses Ziel berücksichtigt jedoch nicht das Inferenzbudget, das bei der Skalierung eines Sprachmodells kritisch wird. Obwohl es billiger sein kann, ein großes Modell zu trainieren, um ein bestimmtes Leistungsniveau zu erreichen, wird ein kleineres Modell, das länger trainiert wird, leistungsfähiger sein.
Aus dem Paper
Das 13-Milliarden-Modell von LLaMA, das auf dem Niveau von GPT-3 operiert, läuft nach Angaben des Meta-Forschungsteams auf einer einzigen Nvidia Tesla V100-Grafikkarte. Es könnte dazu beitragen, den Zugang zu und die Forschung an großen Sprachmodellen zu demokratisieren.
Zudem zeigen die LLaMA-Sprachmodelle, dass größere Modelle noch erhebliche Leistungsreserven haben könnten, wenn ein Unternehmen Geld in die Hand nimmt und große Modelle mit großen Datenmengen kombiniert. Das Forschungsteam von Meta will dies in Zukunft tun, ebenso wie das Feintuning der Modelle mit Instruktionen.
Wir planen für die Zukunft die Veröffentlichung größerer Modelle, die mit größeren Pretraining-Korpora trainiert wurden, da wir bei der Skalierung eine konstante Leistungsverbesserung festgestellt haben.
Aus dem Paper
Öffentliche Daten fürs KI-Training
LLaMA unterscheidet sich nach Angaben des Meta-Forschungsteams durch die Trainingsdaten von Deepminds Chinchilla und anderen Konzern-Sprachmodellen. LLaMA verwendet demnach ausschließlich öffentlich verfügbare Daten. Andere Modelle nutzten undokumentierte oder nicht öffentlich verfügbare Datensätze für das Training, so die Forscherinnen und Forscher.
Ein Großteil (67%) der LLaMA-Daten stammt aus einer bereinigten Version des weit verbreiteten "English Common Crawl"-Datensatzes. Weitere Datenquellen sind unter anderem Public GitHub und Wikipedia. Die LLaMA-Modelle seien daher "Open Source kompatibel", schreibt das Team.
Dies ist zumindest insofern fraglich, als die gängigen Open-Source-Lizenzen die Nutzung für das KI-Training bislang nicht vorsehen. Typischerweise geben die Modelle z.B. keine Quellen im Output an. Eine wirksame Einwilligung in die Nutzung der Daten für das KI-Training lässt sich allein aus der öffentlichen Verfügbarkeit der Daten im Internet wohl nicht ableiten, auch wenn die großen Konzerne dies derzeit so handhaben. Hier können nur Gerichte Klarheit schaffen.
Meta gibt die Sprachmodelle unter der nicht kommerziellen Lizenz GPL v3 an ausgewählte Partner aus Wissenschaft, Behörden und Industrie weiter. Interessenten können sich hier bewerben. Zugriff auf die Modellkarte und eine Anleitung zur Nutzung gibt es auf Github.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.