BloombergGPT ist ein Sprachmodell für die Finanzwelt auf GPT-3-Niveau

Bloomberg hat ein Sprachmodell speziell für den Finanzsektor entwickelt. Für das KI-Training verwendete das Unternehmen seine eigenen Finanzdaten und mischte sie mit Online-Textdaten. Das Beispiel zeigt, wie Unternehmen domänenspezifische Sprachmodelle entwickeln können, die für ihre Branche nützlicher sind als generische Modelle.
Die KI-Teams von Bloomberg stellten zunächst einen Datensatz englischsprachiger Finanzdokumente zusammen: 363 Milliarden finanzspezifische Token stammen aus dem eigenen Bestand und weitere 345 Milliarden generische Token aus den Online-Datensätzen The Pile, C4 und Wikipedia.
Mit 569 Milliarden Tokens aus diesem Datensatz trainierte das Team das domänenspezifische "BloombergGPT", ein 50 Milliarden arameter großes Decoder-only Sprachmodell, das für Finanzthemen optimiert ist. Als Basisarchitektur verwendete das Bloomberg-Team das Open-Source-Sprachmodell Bloom.
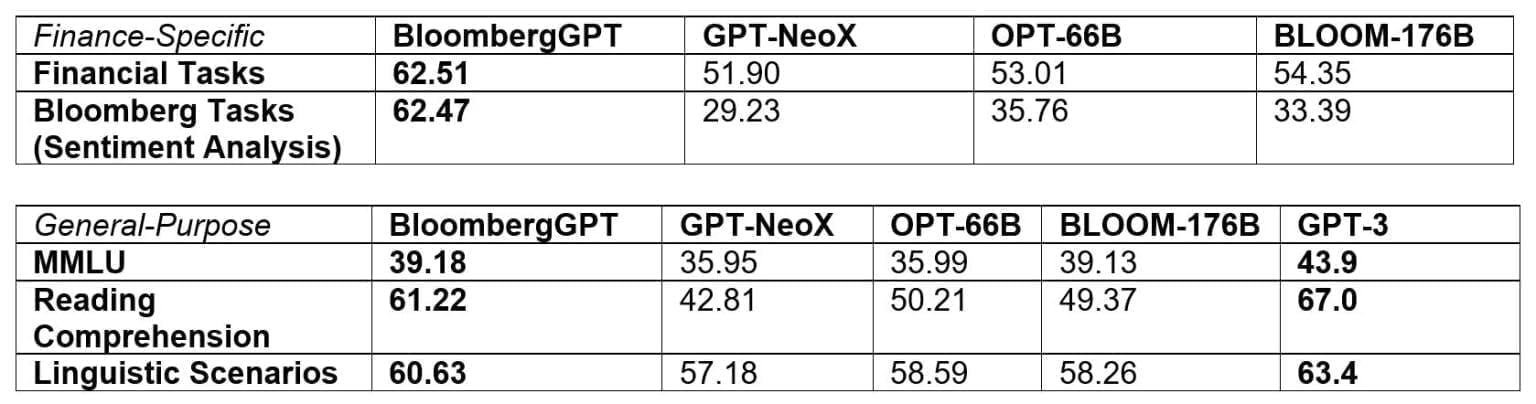
In finanzspezifischen Aufgaben übertrifft BloombergGPT gängige Open-Source-Sprachmodelle wie GPT-NeoX, OPT und Bloom. Aber auch bei generischen Sprachaufgaben wie Zusammenfassungen ist es diesen Modellen zum Teil deutlich überlegen und liegt nach den Benchmarks von Bloomberg fast auf dem Niveau von GPT-3.
"Die Qualität von maschinellem Lernen und NLP-Modellen hängt von den Daten ab, die man in sie einspeist", erklärt Gideon Mann, Leiter des ML-Produkt- und Forschungsteams von Bloomberg.
BloombergGPT als Beispiel für die Leistungsfähigkeit domänenspezifischer Sprachmodelle
Laut Bloomberg können Sprachmodelle in vielen Bereichen der Finanztechnologie eingesetzt werden, von der Stimmungsanalyse in Artikeln, etwa in Bezug auf einzelne Unternehmen, über die automatische Entitätenerkennung bis hin zur Beantwortung von Finanzfragen. Die Nachrichtenabteilung von Bloomberg kann das Modell beispielsweise nutzen, um automatisch Überschriften für Newsletter zu generieren.

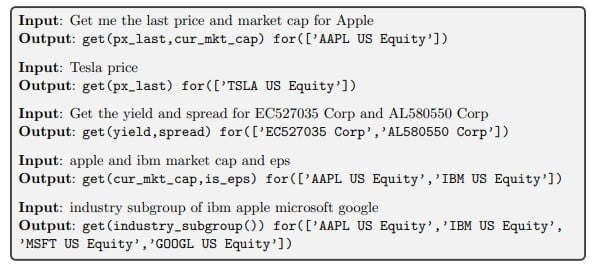
Darüber hinaus hat das Modell anhand einiger Beispiele gelernt, Anfragen in natürlicher Sprache in Bloombergs eigener Programmiersprache (BQL, Bloomberg Query Language) zu formulieren, um die gewünschten Daten aus einer Datenbank zu extrahieren.
"Aus all den Gründen, aus denen generative LLMs attraktiv sind - Lernen mit wenigen Beispielen, Textgenerierung, dialogfähige Systeme und so weiter - sehen wir einen enormen Wert in der Entwicklung des ersten LLM, der sich auf den Finanzbereich konzentriert", sagt Shawn Edwards, Chief Technology Officer von Bloomberg.
Das domänenspezifische Sprachmodell ermögliche es Bloomberg, viele neue Arten von Anwendungen zu entwickeln und eine wesentlich höhere Leistung zu erzielen als mit kundenspezifischen Modellen für jede einzelne Anwendung - und das alles bei einer kürzeren Markteinführungszeit.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.