GigaGAN: Altbewährte KI-Architektur zeigt neue Tricks

GigaGAN zeigt, dass Generative Adversarial Networks noch lange nicht ausgedient haben und in Zukunft eine schnellere Alternative zu Stable Diffusion bieten könnten.
Die aktuellen generativen KI-Modelle für Bilder sind Diffusionsmodelle, die mit großen Datensätzen trainiert werden und Bilder auf der Grundlage von Textbeschreibungen erzeugen. Sie haben die früher weit verbreiteten GANs (Generative Adversarial Network) abgelöst, da diese 2021 erstmals in der Qualität der erzeugten Bilder übertroffen wurden.
GANs sind jedoch wesentlich schneller in der Synthese und lassen sich aufgrund ihrer Struktur besser steuern. Modelle wie StyleGAN waren vor dem Durchbruch der Diffusionsmodelle praktisch Standard.
Mit GigaGAN zeigen Forschende von POSTECH, der Carnegie Mellon University und Adobe Research nun ein GAN-Modell mit einer Milliarde Parametern, das wie Stable Diffusion, DALL-E 2 oder Midjourney mit einem großen Datensatz trainiert wurde und Text-zu-Bild-Synthese beherrscht.
GigaGAN ist deutlich schneller als Stable Diffusion
GigaGAN ist damit sechsmal größer als das bisher größte GAN und wurde vom Team mit dem LAION-2B-Datensatz mit über 2 Milliarden Bild-Text-Paaren und COYO-700M trainiert. Ein auf GigaGAN basierender Upscaler wurde mit Adobe Stockfotos trainiert.
Dem Papier zufolge ist diese Skalierung nur durch Anpassungen der Architektur möglich, von denen einige von Diffusionsmodellen inspiriert sind.
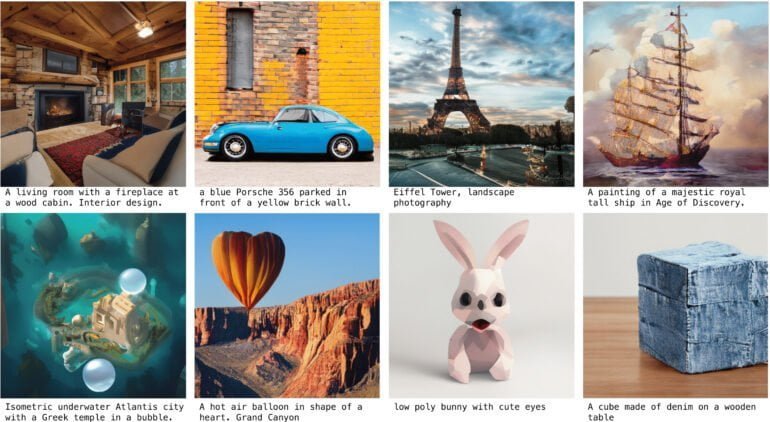
Nach dem Training ist GigaGAN in der Lage, Bilder mit einer Größe von 512 x 512 Pixeln aus Textbeschreibungen zu generieren. Die Inhalte sind klar erkennbar - erreichen aber in den mitgelieferten Beispielen noch nicht die Qualität hochwertiger Diffusionsmodelle. Dafür ist GigaGAN zwischen 10- und 20-mal schneller als vergleichbare Diffusionsmodelle: Auf einer Nvidia A100 generiert GAN ein Bild in 0,13 Sekunden, Muse-3B benötigt 1,3 Sekunden und Stable Diffusion (v.1.5) 2,9 Sekunden.
Eine Skalierung auf größere Modelle verspricht zudem Qualitätsgewinne, sodass in Zukunft noch deutlich größere - und bessere - GANs zu erwarten sind.
Weitere Skalierung könnte GigaGAN auf das Niveau der besten generativen KI-Modelle heben
"Unsere GigaGAN-Architektur eröffnet einen völlig neuen Gestaltungsspielraum für große generative Modelle und bringt wichtige Bearbeitungsmöglichkeiten zurück, die mit dem Übergang zu autoregressiven und Diffusionsmodellen schwierig wurden. Wir erwarten, dass sich unsere Leistung bei größeren Modellen verbessern wird.

Die GAN-Architektur erlaubt es auch, die Bilder leicht zu verändern, z.B. das Material der Objekte auszutauschen oder die Tageszeit zu ändern. Ähnliche Möglichkeiten bieten auch Diffusionsmodelle, die jedoch auf externe Methoden, Tricks oder Handarbeit zurückgreifen müssen.
Besonders beeindruckend ist die Upscaling-Variante von GigaGAN: Das Modell wandelt ein 128-Pixel-Bild in 3,66 Sekunden in ein hochauflösendes 4K-Bild um. Die Details, die das Modell in den gezeigten Beispielen hinzufügt, sind fotorealistisch.

Bisher scheint es keine Pläne zu geben, die Modelle zu veröffentlichen. Eine Variante des Upscalers könnte z.B. in Adobe Firefly oder Photoshop integriert werden.
Mehr Beispiele und Informationen gibt es auf der GigaGAN-Projektseite.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.