LLM-Vergleich zwischen GPT-4, Claude 2 und Llama 2 - wer halluziniert, wer relativiert?

Der auf LLM-Benchmarking spezialisierte Dienst "Arthur" hat die Leistung großer Sprachmodelle wie GPT-4 für zwei Schlüsselthemen verglichen.
Arthur analysierte die Halluzinationen und Antwortrelativierungen der Sprachmodelle GPT-3.5 (~175 Milliarden Parameter) und GPT-4 (~1.76 Billionen Parameter) von OpenAI, Claude 2 von Anthropic (Parameter unbekannt), Llama 2 (70 Milliarden Parameter) von Meta und des Command Modells von Cohere (~50 Milliarden Parameter).
Um die Halluzinationen zu vergleichen, stellte Arthur Fragen zur Kombinatorik und Wahrscheinlichkeitsrechnung, zu US-Präsidenten und zu politischen Führern in Marokko. Die Fragen wurden mehrmals gestellt, da die Sprachmodelle manchmal die richtige, manchmal eine leicht falsche oder eine völlig falsche Antwort auf dieselbe Frage gaben.

Claude 2 hatte bei den Fragen zu den US-Präsidenten die wenigsten Halluzinationen bei mehr richtigen Antworten, schnitt also besser ab als GPT-4 und deutlich besser als GPT-3.5 Turbo, das ständig versagte. Letzteres ist insofern kritisch, als das kostenlose ChatGPT auf GPT-3.5 basiert und wahrscheinlich am häufigsten von Studierenden und in Schulen verwendet wird.

Bei den marokkanischen Politikern verweigerten Llama 2 und Claude 2 besonders häufig die Antwort, wahrscheinlich als Gegenmaßnahme gegen zu starke Halluzinationen. Hier war GPT-4 das einzige Modell mit mehr richtigen Antworten als Halluzinationen.
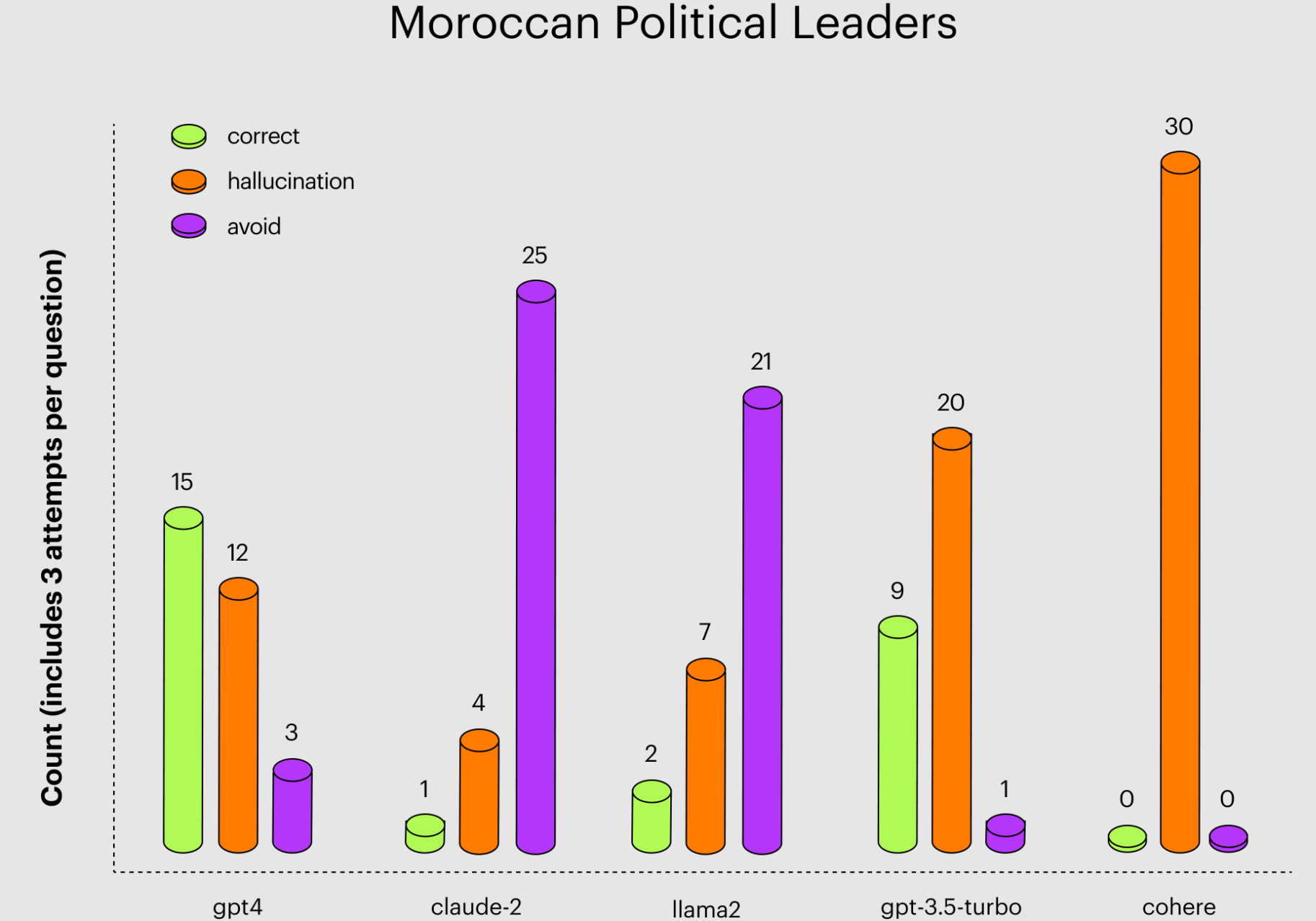
GPT-4 ist vorsichtiger als andere Modelle
In einem zweiten Test untersuchte die Benchmarking-Plattform, inwieweit die Modelle ihre Antworten absichern, also eine Warnung vor die Antwort setzen wie "Als großes Sprachmodell kann ich nicht ...". Dieses "Hedging" von Antworten kann die Benutzerinnen und Benutzer frustrieren. Außerdem findet man dieses "Hedging" manchmal in KI-generierten Texten von unvorsichtigen "Autoren".
Für den Hedging-Test verwendete die Plattform einen Datensatz mit generischen Fragen, die Benutzerinnen und Benutzer an LLMs stellen könnten. Die beiden GPT-4-Modelle beantworteten diese Fragen in 3,3 bzw. 2,9 Prozent der Fälle. GPT-3.5 turbo und Claude-2 taten dies nur in etwa zwei Prozent der Fälle, während Cohere diesen Mechanismus nicht verwendet.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.