Stable Diffusion Start-up launcht überzeugenden KI-Audiogenerator Stable Audio

Das Londoner Startup Stability AI hat am Mittwoch ein neues Produkt namens Stable Audio vorgestellt, das mithilfe von KI eigene Musikstücke und Soundeffekte generieren kann.
Stable Audio nutzt ein Diffusion-basiertes KI-Modell, um aus einfachen Texteingaben innerhalb weniger Sekunden individuelle Audiodateien zu produzieren. Anwender:innen geben Genres, Instrumente, Stimmung und andere Merkmale vor. Das System komponiert daraufhin eigenständig passende Songs, Soundeffekte oder Instrumenten-Stems.
Bis zu 90 Sekunden mit 44,1 kHz
Getestet hat Stability AI das Tool beispielsweise mit Eingaben wie "Post-Rock, Guitars, Drum Kit, Bass, Strings, Euphoric, Up-Lifting, Moody, Flowing, Raw, Epic, Sentimental, 125 BPM". Das Ergebnis ist ein schneller, atmosphärischer Rock-Song mit 125 BPM. Laut Stability kann Stable Audio auf diese Weise Songs in verschiedenen Genres wie Ambient, Techno oder Trance erzeugen.
Im Gegensatz zu bisherigen KI-basierten Musikgeneratoren scheint Stable Audio in der Lage zu sein, über einen längeren Zeitraum von bis zu 90 Sekunden musikalisch kohärente Stücke in professioneller Audioqualität von 44,1 kHz zu produzieren.
Die veröffentlichten Kostproben klingen authentisch und lassen kaum vermuten, dass keine menschlichen Komponisten dahinterstecken. Auf einer Nvidia A100 GPU sollen 95 Sekunden Audio in weniger als einer Sekunde erzeugt werden.
Die folgenden Beispielsongs und Audioeffekte wurden allein anhand von Prompts wie "Leute unterhalten sich in einem vollen Restaurant" oder "Piano solo chord progression major key uplifting 90 BPM" generiert.
Weitere Beispielsongs, die mit Stable Audio generiert wurden, hat Stability AI in die Ankündigung eingebettet. Die Server sind derzeit leider überlastet.
Künstler:innen sollen an Stable-Audio-Einnahmen beteiligt werden
Um diese Qualität zu erreichen, wurde das System mit einer Musikbibliothek des Anbieters AudioSparx trainiert. AudioSparx ist eine Partnerschaft mit Stability AI eingegangen und hat dem Start-up für die Nutzung der rund 800.000 Songs, Audioeffekte und Instrumentenschnipsel eine Beteiligung an den Einnahmen von Stable Audio zugesichert. Die Urheber:innen der für das Training verwendeten Songs können wiederum über AudioSparx an den Gewinnen von Stable Audio beteiligt werden.
Sie sollen vor dem Training gefragt worden sein, ob sie ihre Songs zur Verfügung stellen wollen. Diese Entscheidung könnte eine Reaktion auf den massiven Widerstand sein, den Stability im Rahmen der Urheberrechtsdebatte um das Trainingsmaterial von Stable Diffusion erfahren hat.
Laut Stability AI können Anwender:innen die mit Stable Audio generierten Tracks privat kostenfrei verwenden. Für die kommerzielle Nutzung ist ein kostenpflichtiges Abo erforderlich. Damit zielt das Unternehmen vorwiegend auf Kreative wie Filmemacher:innen oder Spieleentwickler:innen ab, die schnell eine passende Musikuntermalung benötigen.
Quelloffenes Musikmodell auf anderen Daten trainiert
Stable Audio unterscheidet sich von Stable Diffusion dadurch, dass es im Gegensatz zu dem beliebten Bildmodell nicht quelloffen veröffentlicht wird. In den FAQ heißt es jedoch, dass bald ein Open-Source-Modell erscheinen soll, das auf anderen Daten trainiert ist.
Grundlage für die Entwicklung von Stable Audio stellt das Text-Musik-Modell Dance Diffusion dar, das Harmonai mit Stabilitys Unterstützung 2022 veröffentlicht hat. Stable Audio ist jedoch ein von Grund auf neu entwickeltes Modell von Stability AIs im April gegründeter Audiosparte.
Diffusionsmodelle für Musik einzusetzen, ist keine neue Idee. Die Stärke von Stable Audio liege jedoch darin, Stücke in unterschiedlicher Länge produzieren zu können. Dies sei beim Training berücksichtigt worden.
Stability AI erklärt die zugrundeliegende Technik so:
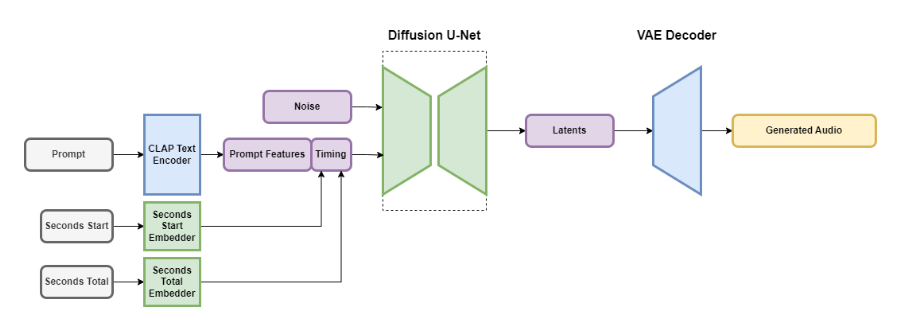
- Stable Audio ist ein latentes Diffusionsmodelle mit verschiedenen Teilen: einem Variational Autoencoder (VAE), einem Text-Encoder und einem U-Net-basierten Diffusionsmodell.
- Der VAE komprimiert Stereoaudio in eine verlustbehaftete, rauschresistente und invertierbare latente Kodierung, was schnellere Generierung und Training ermöglicht.
- Für die Text-Prompts wird ein gefrorener Text-Encoder eines neu trainierten CLAP-Modells verwendet.
- Timing-Einbettungen werden während des Trainings berechnet und dienen der Steuerung der Ausgabe-Audiolänge.
- Das Diffusionsmodell für Stable Audio ist ein U-Net mit 907 Millionen Parametern, das auf dem Moûsai-Modell basiert.
Ihr könnt Stable Audio ausschließlich über die jüngst gestartete Weboberfläche nutzen. 20 Songs im Monat mit bis zu 45 Sekunden sind für die private Nutzung kostenlos. Für 11,99 US-Dollar im Monat bekommt ihr 500 Songs mit bis zu 90 Sekunden Abspielzeit und kommerzieller Lizenz.
Kein Content-Filter - leichte Kopien?
Das Tool könnte auch für gefälschte Songs bekannter Künstler:innen zweckentfremdet werden. Obwohl die Labels bisher erfolgreich gegen derartige KI-Kreationen vorgehen konnten, ist die rechtliche Situation nicht eindeutig geklärt.
Stability AI selbst betont im Interview mit Techcrunch, verantwortungsvoll mit der Technologie umgehen zu wollen. Die Datenbank von AudioSparx enthält zwar keine Popsongs, doch viele, die als solche im Stile bekannter Künstler:innen gekennzeichnet sind. Im Gegensatz zu Googles MusicLM werden die Namen prominenter Interpret:innen zumindest bisher nicht blockiert.
Ob sich mit Stable Audio das bisher wahrscheinlich defizitäre Geschäftsmodell von Stability AI rechnet, bleibt abzuwarten. Die beeindruckende Qualität der KI-Kompositionen lässt jedenfalls aufhorchen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.