LeoLM ist ein für Deutsch optimiertes großes Open-Source-Sprachmodell

Update vom 02.12.2023:
Laion veröffentlicht die 70-Milliarden-Version von LeoLM, die mit 65 Milliarden Token trainiert wurde. Als Basis dient Llama-2-70b.
"Mit diesem Release hoffen wir, der deutschen Open Source und kommerziellen LLM-Forschung eine neue Welle von Möglichkeiten zu bringen und die Akzeptanz zu beschleunigen", schreibt das Team.
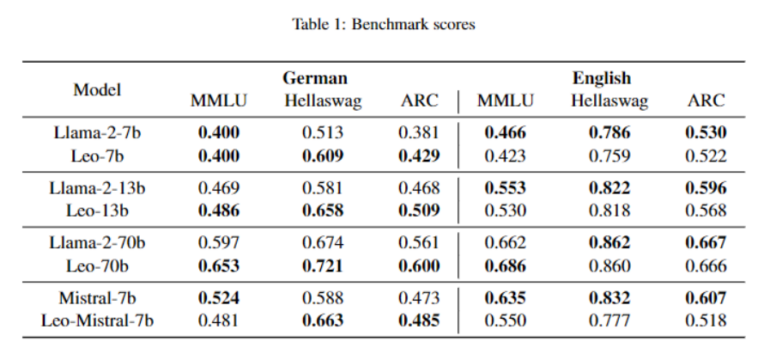
Laut LAION übertrifft LeoLM in Few-Shot-Anwendungen die Übersetzungsleistung von gpt-3.5.turbo-instruct und erzielt bessere Benchmark-Ergebnisse als das Llama-2-Basismodell - auch in Englisch. Eine Chat-Variante von LeoLM ist hier verfügbar.
Originalartikel vom 29. September 2023:
LAION und Hessian.AI stellen das deutsche Sprachmodell LeoLM (Linguistically Enhanced Open Language Model) vor.
LAION und Hessian.AI haben gemeinsam LeoLM entwickelt, das erste kommerziell nutzbare quelloffene "German Foundation Language Model". Es basiert auf Metas Llama 2 und wurde auf dem Hessian.AI Supercomputer 42 mit einem umfangreichen Korpus deutscher und landesspezifischer qualitativ hochwertiger Texte trainiert.
Mit den jetzt veröffentlichten Modellen LeoLM/leo-hessianai-7b und LeoLM/leo-hessianai-13b sowie dem in Kürze erscheinenden LeoLM-70B soll die deutsche LLM-Landschaft für Open Source und für kommerzielle Anwendungen vorangebracht werden.
Alle Modelle haben ein 8K-Kontextfenster. Das leistungsfähigste Modell ist leo-hessianai-13b-chat, das bei der Aufgabe "humanities" im GPT-4-basierten KI-Test "MT-Bench" fast die Leistung von GPT-3.5 erreichte.

Sprachbarrieren überwinden
LeoLM diene als Machbarkeitsstudie für den Spracherwerb mit vortrainierten Modellen, schreibt das Team. Um die Deutschkenntnisse von Llama-2 zu verbessern, durchlief LeoLM ein Level-2-Vortraining, bei dem die Modelle mit Llama-2-Gewichten initialisiert und auf einem umfangreichen deutschen Textkorpus mit 65 Milliarden Token trainiert wurden. Dabei sollten die bisherigen Fähigkeiten des Modells so weit wie möglich erhalten bleiben.
Das Projektteam übersetzte mit Hilfe von GPT-3.5 mehrere qualitativ hochwertige Instruktionsdatensätze aus dem Englischen ins Deutsche. Darüber hinaus verwendete es bereits vorhandene Datensätze mit deutschen Texten und erstellte zwei Datensätze mit Schwerpunkt auf kreativem Schreiben und Reimen, um die bei den ersten Tests festgestellten Schwächen zu beheben.
Für die Evaluierung übersetzte das Team eine Reihe englischer Benchmarks ins Deutsche, um den Vergleich der Modelle zu standardisieren und einen umfassenden Evaluierungsansatz für die Basis- und Chat-Modelle zu bieten ("GermanBench"). Die Ergebnisse zeigen, dass das Training die Benchmark-Ergebnisse für die deutsche Sprache verbessert hat, während die Ergebnisse für die englische Sprache leicht zurückgegangen sind.

Der durchschnittliche Anstieg der Benchmark-Ergebnisse für Deutsch übersteigt jedoch den durchschnittlichen Rückgang der Benchmark-Ergebnisse für Englisch. Das Team sieht darin den Nachweis, dass ein LLM eine neue Sprache lernen kann, ohne bereits vorhandene Kenntnisse zu vergessen.
Alle LeoLM-Modelle und die für das Training verwendeten Datensätze sind auf HuggingFace verfügbar. Für den produktiven Einsatz eines Sprachmodells für deutschsprachige Aufgaben dürfte insbesondere das angekündigte 70-Milliarden-Parameter-Modell interessant werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.