GPT-4 vernichtet andere LLMs laut neuer Benchmark-Suite

Benchmarks sind ein zentrales Element der KI-Entwicklung und ein Motor für kontinuierlichen Fortschritt. Sie bergen aber auch viele Fallstricke. Die neue Benchmarking-Suite GPT-Fathom will sie reduzieren.
Mit Benchmark-Tests messen KI-Teams die Leistung ihrer Modelle bei verschiedenen Aufgaben. Bei Sprachmodellen zum Beispiel beim Beantworten von Wissensfragen oder beim Lösen von Logikaufgaben. Je nach Leistung erhält das Modell eine Bewertung, die dann mit den Ergebnissen anderer Modelle verglichen werden kann.
Diese Benchmarking-Ergebnisse bilden die Grundlage für weitere Forschungsentscheidungen und damit letztlich für Investitionen. Sie geben auch Aufschluss über die Stärken und Schwächen der einzelnen Verfahren.
Obwohl viele LLM-Benchmarks und Leaderboards verfügbar sind, mangelt es ihnen oft an konsistenten Parametern und Anforderungen, beispielsweise bei den Prompting-Methoden oder der mangelnden Berücksichtigung der Modellsensitivität für Prompts.
Dieser Mangel an Konsistenz erschwert den Vergleich der Ergebnisse verschiedener Studien oder die Reproduzierbarkeit der berichteten Ergebnisse.
GPT-Fathom will Struktur ins LLM-Benchmarking bringen
Hier setzt GPT-Fathom an, ein Open Source Evaluation Kit für LLMs, das die oben genannten Herausforderungen adressiert. Es wurde von Forschern von ByteDance und der University of Illinois at Urbana-Champaign auf Basis des bestehenden OpenAI LLM Benchmarking Frameworks Evals entwickelt.
GPT-Fathom zielt darauf ab, Schlüsselprobleme bei der Bewertung von LLMs zu adressieren, darunter inkonsistente Einstellungen - wie die Anzahl von Beispiel-"Shots" im Prompt, unvollständige Sammlungen von Modellen und Benchmarks und die unzureichende Berücksichtigung der Sensitivität von Modellen auf verschiedene Prompting-Methoden.
In einer erste Anwendung bewertete das Team mit der eigenen Systematik als zehn führenden LLMs anhand von mehr als 20 sorgfältig kuratierten Benchmarks in sieben Fähigkeitskategorien wie Wissen, Logik oder Programmierung unter einheitlichen Einstellungen.
GPT-4 liegt deutlich vorne
Wer regelmäßig mit verschiedenen LLMs arbeitet, wird von dem grundsätzlichen Ergebnis nicht überrascht sein: GPT-4, das Modell hinter der kostenpflichtigen Version von ChatGPT, "vernichtet" die Konkurrenz in den meisten Benchmarks, schreibt das Forschungsteam. Auch in einem kürzlich veröffentlichten Benchmark zu Halluzinationen ging GPT-4 als Gewinnermodell hervor.
Gegenüber den eigenen Modellen der GPT-3.5-Familie liegt GPT-4 deutlich vorn, aber auch gegenüber dem derzeit wohl stärksten Konkurrenten Claude 2 messen die Forschenden in den meisten Benchmarks einen signifikanten Leistungsunterschied. Claude 2 sei aber das leistungsfähigste Nicht-OpenAI-Modell. Das GPT-4-Modell "Advanced Data Analysis" übertrifft die Konkurrenz auch im Coding deutlich.
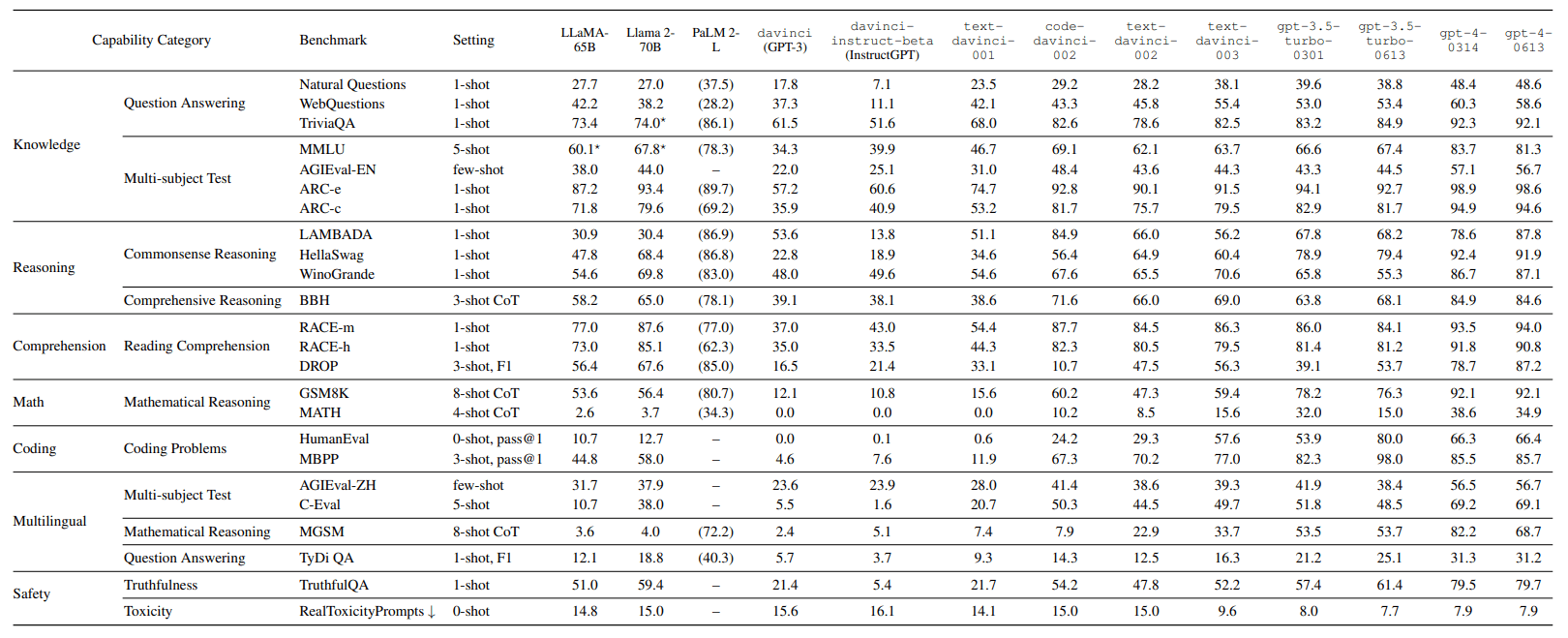

Das derzeit leistungsstärkste Open-Source-Modell Llama 2 übertrifft seinen Vorgänger Llama-65B in den meisten Benchmarks, insbesondere in den Aufgaben "Argumentieren" und "Verstehen". Im Vergleich zu gpt-3.5-turbo-0613 zeigt Llama 2-70B eine vergleichbare Leistung im Bereich "Sicherheit" und übertrifft es sogar im Bereich "Verstehen".
Llama 2-70B schneidet jedoch in anderen Bereichen schlechter ab, insbesondere in "Mathematik", "Codierung" und "Mehrsprachigkeit". Dies sind bekannte Schwächen des Open-Source-Modells von Meta.
Bei den Modellen LLaMA-65B und Llama 2-70B will das Forschungsteam zudem eine besondere Prompt-Sensitivität gemessen haben. Bei Llama 2-70B führte bereits eine geringfügige Änderung des Prompts zu einem Rückgang des Ergebnisses im Benchmark "TriviaQA" von 74,0 auf 55,5 Punkte. Der Test prüft das Leseverständnis der LLMs und ihre Fähigkeit, Fragen zu beantworten.
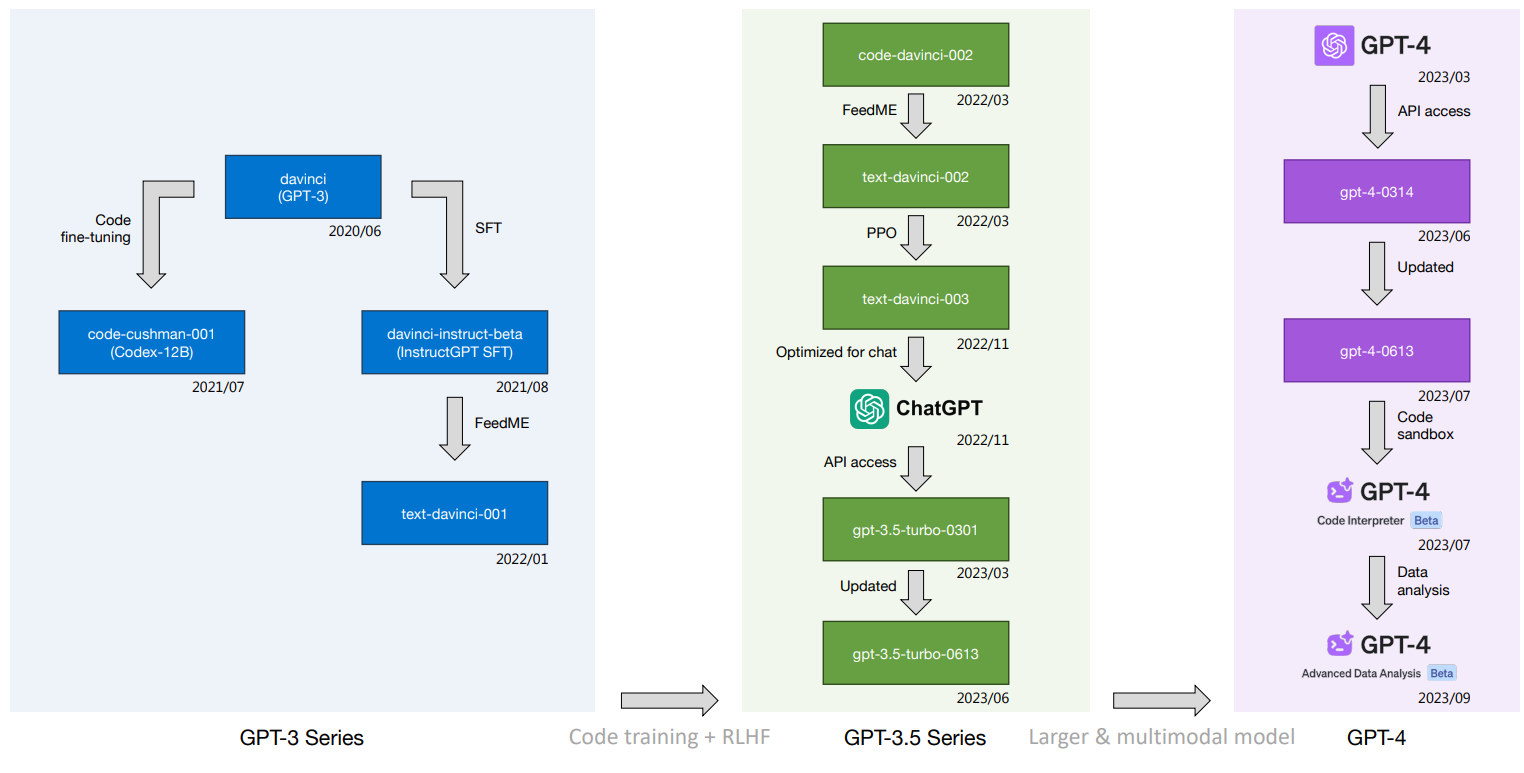
Das Forschungsteam verglich auch die Entwicklung der OpenAI-Modelle von den ersten Anfängen des GPT-3 bis zum GPT-4. Das Ergebnis zeigt den riesigen Sprung vom GPT-3 zu den Nachfolgemodellen. Entscheidend für die Auswirkungen großer Sprachmodelle primär auf den Arbeitsmarkt dürfte sein, ob zukünftige Modelle ähnlich große Sprünge machen können.

Der "Wippe"-Effekt erhöht die Komplexität der LLM-Entwicklung
In dem Papier beschreibt das Team zudem den "Trade-off"- oder "Wippe"-Effekt. Eine deutliche Verbesserung der Modellleistung in einem Bereich kann zu einer unbeabsichtigten Verschlechterung der Leistung in einem anderen Bereich führen.
So hat etwa "gpt-3.5-turbo-0613" nach den Messungen des Teams im Vergleich zu seinem Vorgänger "gpt-3.5-turbo-0301" seine Leistung in Coding-Benchmarks deutlich verbessert. Allerdings ist gleichzeitig ein signifikanter Rückgang der MATH-Punktzahl von 32,0 auf 15,0 zu verzeichnen.
Ein ähnliches Bild zeigt sich bei GPT-4: Der Modellsprung von gpt-4-0314 zu gpt-4-0613 führte zu einer starken Leistungssteigerung im Textverständnis-Benchmark DROP (Discrete Reasoning Over Paragraphs).
Gleichzeitig sank jedoch die Punktzahl im Benchmark MGSM (Mathematical Geometry Simple Math) deutlich von 82,2 auf 68,7. Der Benchmark misst einfache Rechenaufgaben, die ein grundlegendes Verständnis von Zahlentheorie, Arithmetik und Geometrie erfordern.
Diese Muster unterstreichen nach Ansicht des Forschungsteams die Komplexität des Trainings und der Optimierung von LLMs. Weitere Forschung ist notwendig, um diese Effekte besser zu verstehen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.