Anthropics Claude 2.1 bestes Feature hat das gleiche Problem wie GPT-4 Turbo
Ähnlich wie OpenAI mit GPT-4 Turbo wirbt Anthropic mit seinem neuen Chatbot Claude 2.1 damit, besonders viel Text gleichzeitig verarbeiten zu können. Doch wie bei Turbo funktioniert das mehr schlecht als recht.
Die großen Kontextfenster von OpenAIs GPT-4 Turbo und Anthropics neu vorgestelltem Modell Claude 2.1 können eine große Anzahl von Sätzen und Wörtern gleichzeitig verarbeiten und analysieren. GPT-4 Turbo kann bis zu 128.000 Tokens (circa100.000 Wörter) verarbeiten, Claude 2.1 bis zu 200.000 Tokens (circa 150.000 Wörter).
Beide Modelle leiden jedoch unter dem "lost in the middle"-Phänomen: Informationen in der Mitte und am oberen und unteren Rand eines Dokuments werden vom Modell häufig ignoriert.
Zuverlässige Informationsextraktion nur am Anfang und Ende des Kontextfensters
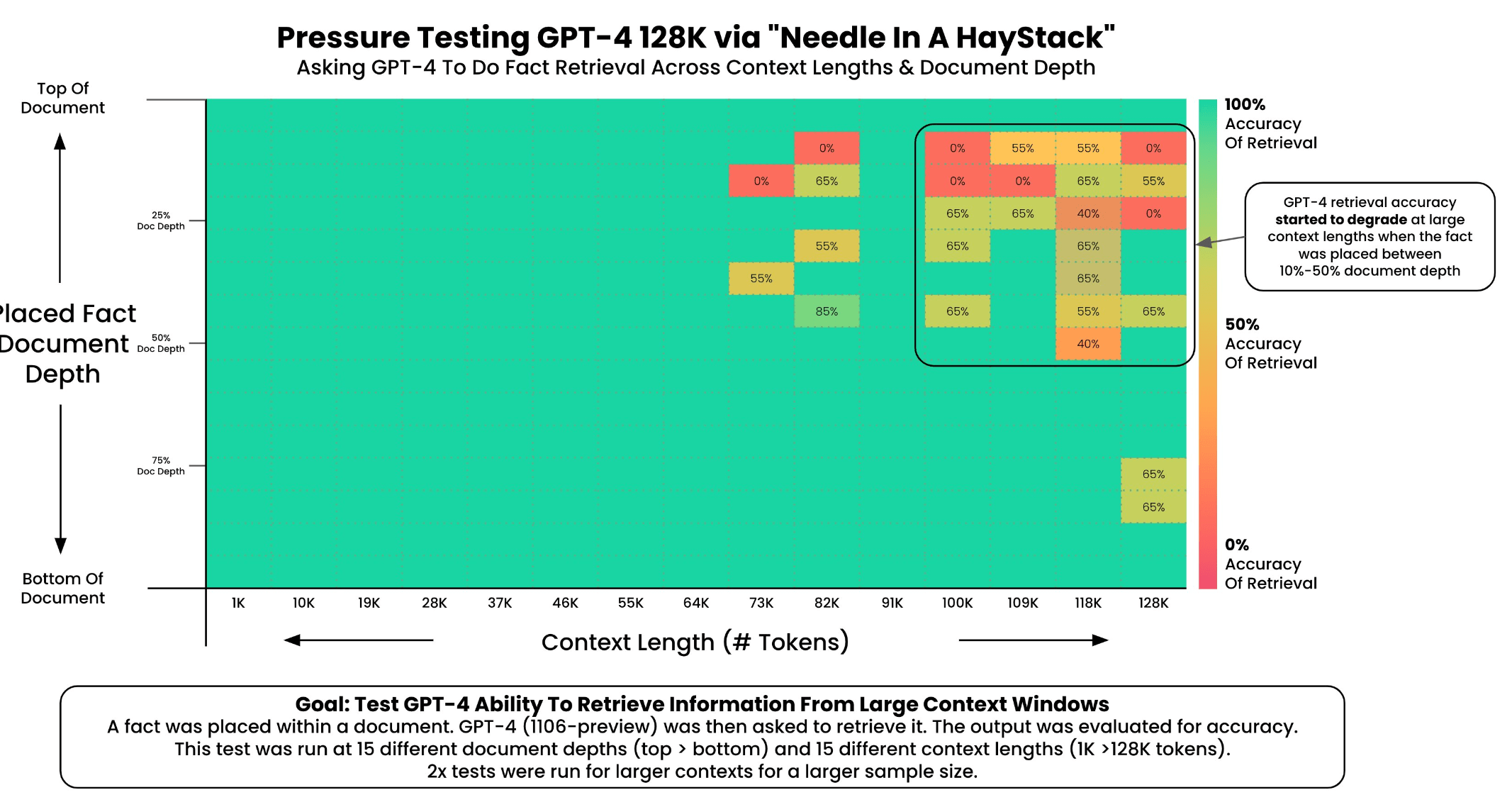
Greg Kamradt führte, wie zuvor mit GPT-4 Turbo, Tests mit Claude 2.1 Kontextfenster durch, indem er Aufsätze von Paul Graham in das System lud und Aussagen an verschiedenen Stellen im Dokument platzierte. Er versuchte dann, diese Aussagen zu extrahieren und bewertete die Leistung des Modells.
Die Ergebnisse zeigen, dass Claude 2.1 bei 35 Anfragen in der Lage war, Fakten am Anfang und am Ende eines Dokuments mit einer Genauigkeit von fast 100 Prozent zu extrahieren.
Die Leistung des Modells nimmt jedoch ab ca. 90.000 Tokens stark ab, insbesondere bei Informationen in der Mitte und am unteren Rand des Dokuments. In diesem Fall ist das Modell für größere Kontextfenster so unzuverlässig, dass es in allen Fällen, in denen Zuverlässigkeit wichtig ist, unbrauchbar ist. Der Leistungsabfall bei der Informationsextraktion beginnt sehr früh, bei etwa 24K von 200K Token.

Große Kontextfenster bei Sprachmodellen sind nicht ausgereift
Die Performance von Claude 2.1 ähnelt der von OpenAIs GPT-4 Turbo, die Kamradt und andere schon früher untersucht hatten. Allerdings schnitt GPT-4 Turbo im gleichen Testverfahren besser ab als Claude 2.1, hat aber auch ein kleineres Kontextfenster.
Das Fazit ist letztlich dasselbe: Fakten in großen Dokumenten sind in großen Kontextfenstern nicht garantiert auffindbar und die Position am Anfang oder Ende spielt eine große Rolle.
Große Kontextfenster sind daher kein Ersatz für kostengünstigere und genauere Vektordatenbanken, und die Verkleinerung des Kontextfensters erhöht die Genauigkeit.
Wenn möglich, und wenn die Genauigkeit wichtig ist, ist es daher besser, Informationen mit Sprachmodellen in kleineren Einheiten von 8k bis 16K zu verarbeiten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.