Forscher entdecken überraschend einfachen Mechanismus in LLMs

Wissenschaftler des MIT und anderer Institutionen haben herausgefunden, dass große Sprachmodelle oft eine einfache lineare Funktion verwenden, um gespeichertes Wissen abzurufen. Diese Erkenntnis könnte helfen, fehlerhafte Informationen in Modellen zu finden und zu korrigieren.
Lineare Funktionen sind Gleichungen mit nur zwei Variablen und ohne Exponenten. Sie beschreiben den linearen Zusammenhang zwischen zwei Variablen.
Indem sie solche relativ einfachen linearen Funktionen identifizierten, um bestimmte Fakten abzurufen, konnten die Wissenschaftler das Wissen eines Sprachmodells zu bestimmten Themen überprüfen und herausfinden, wo dieses Wissen im Modell gespeichert ist. Die Forscher stellten außerdem fest, dass das Modell dieselbe Dekodierungsfunktion verwendet, um ähnliche Arten von Fakten abzurufen.
"Obwohl diese Modelle sehr komplizierte, nichtlineare Funktionen sind, die mit vielen Daten trainiert werden und sehr schwer zu verstehen sind, gibt es manchmal sehr einfache Mechanismen, die in ihnen funktionieren. Dies ist ein Beispiel dafür", sagt Evan Hernandez, Doktorand in Elektrotechnik und Informatik (EECS) und Mitautor der Studie.
60 Prozent Erfolg bei der Informationsabfrage durch einfache Funktionen
Die Forscher entwickelten zunächst eine Methode zur Schätzung der Funktionen, und berechneten dann 47 konkrete Funktionen für verschiedene textuelle Beziehungen, etwa "Hauptstadt eines Landes". Beim Oberthema Deutschland sollte die Information Berlin abgerufen werden.
Sie testeten jede Funktion, indem sie das Hauptthema änderten (Deutschland, Norwegen, England, …), um zu sehen, ob sie die richtigen Informationen abrufen konnte, was in etwa 60 Prozent der Fälle zutraf.
Hernandez räumt jedoch ein: "Aber nicht alles ist linear kodiert. Für einige Fakten, selbst wenn das Modell sie kennt und Text vorhersagt, der mit diesen Fakten übereinstimmt, können wir keine linearen Funktionen dafür finden. Das deutet darauf hin, dass das Modell etwas Komplizierteres tut, um diese Information zu speichern." Was dieses "Kompliziertere" sein könnte, wäre eine Aufgabe für zukünftige Forschung.
Visualisierung von gespeichertem Wissen durch "Attributlinsen"
Die Forscher nutzten diese Funktionen auch, um herauszufinden, was ein Modell zu verschiedenen Themen für wahr hält. In einem Experiment erzeugten sie mit dieser Methode eine "Attributlinse", die visualisiert, wo in den vielen Schichten des Transformators spezifische Informationen über eine bestimmte Beziehung gespeichert sind.
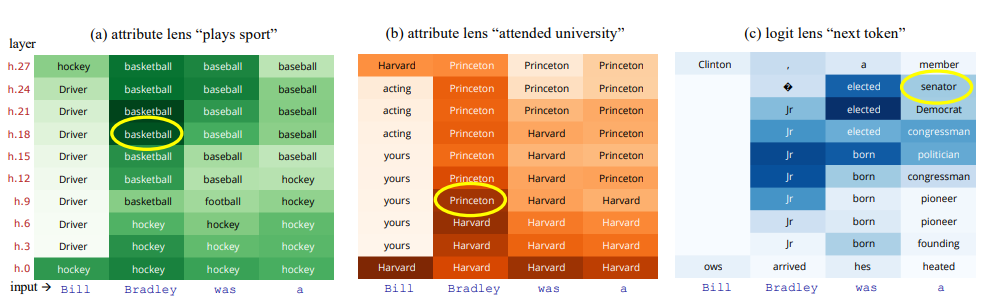
Dieses Visualisierungstool könnte Wissenschaftlern und Entwicklern helfen, gespeichertes Wissen zu korrigieren und zu verhindern, dass ein KI-Chatbot falsche Informationen wiedergibt.
"Wir können zeigen, dass das Modell, auch wenn es sich bei der Textproduktion auf andere Informationen konzentrieren mag, alle abgefragten Informationen kodiert", erklärt Hernandez.
Für ihr Experiment verwendeten die Forschenden die Sprachmodelle GPT-J, Llama 13B und GPT-2-XL, also eher kompakte LLMs. Ob sich die Ergebnisse auch bei deutlich größeren Modellen zeigen, wäre die nächste Forschungsaufgabe.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.