LinkedIn gibt Einblick in Herausforderungen bei der Implementierung von LLMs
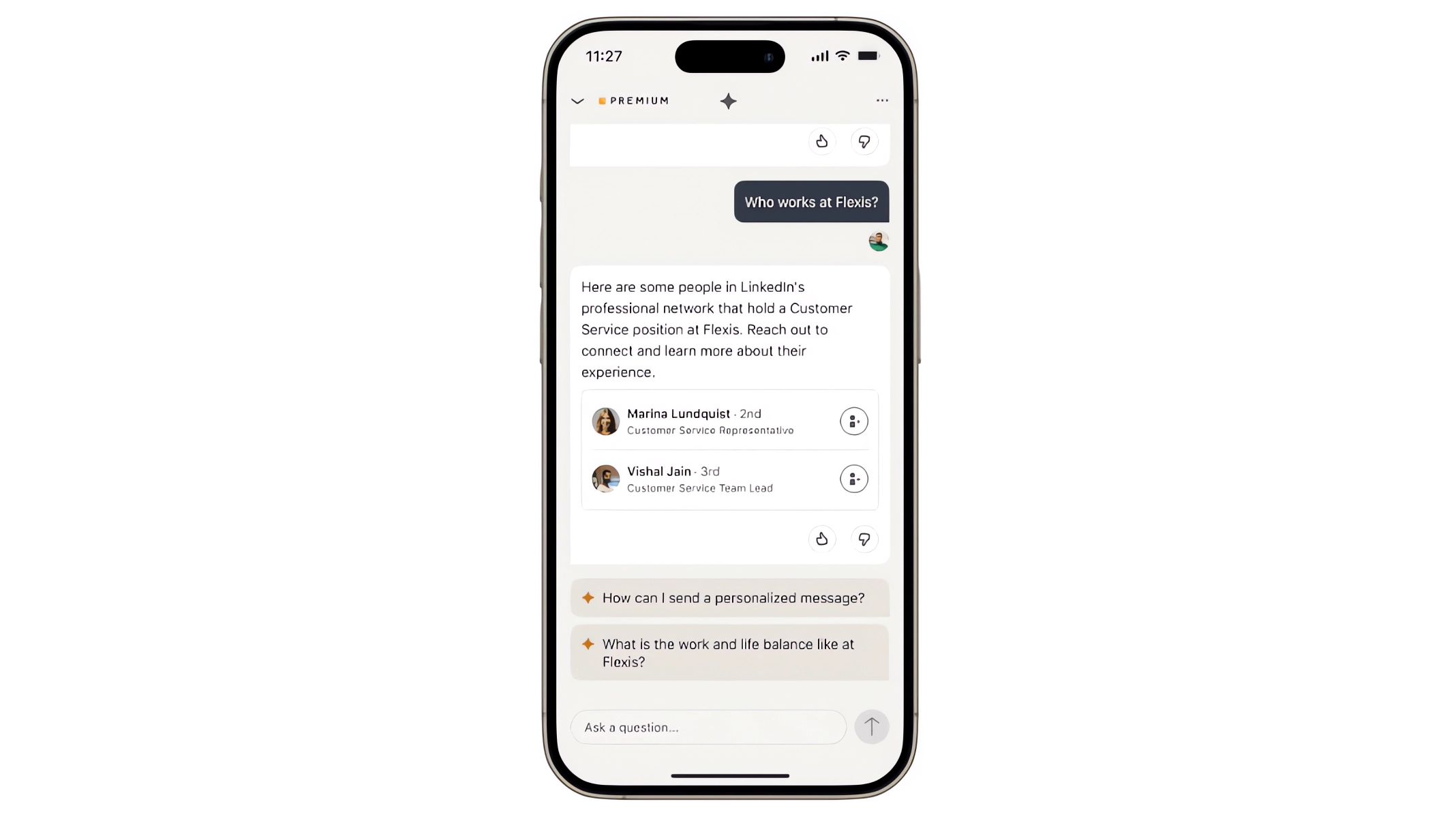
LinkedIn hat in den letzten sechs Monaten an neuen GenAI-Funktionen für die Suche nach Jobs und Inhalten gearbeitet. Das Team beschreibt die Hindernisse, auf die es gestoßen ist, und die Lösungen, die es gefunden hat.
Ein Team bei LinkedIn hat in den letzten sechs Monaten an einem neuen LLM-basierten Produkt gearbeitet. Ziel war es, die Art und Weise, wie Mitglieder nach Jobs suchen und berufsbezogene Inhalte durchsuchen, grundlegend umzugestalten.
Die Entwickler wollten jeden Feed und jedes Stellenangebot zu einem Ausgangspunkt machen, um schneller auf Informationen zuzugreifen, Zusammenhänge herzustellen und Ratschläge zu erhalten, etwa zur Verbesserung des Profils oder zur Vorbereitung auf ein Vorstellungsgespräch.
Der Aufbau einer einfachen Pipeline mit einem Routing-Schritt zur Auswahl des richtigen KI-Agenten, einem Retrieval-Schritt zum Abrufen relevanter Informationen (RAG) und einem Generierungsschritt zur Erstellung der Antwort war nach Aussage des Teams einfach.
Die Aufteilung in unabhängige Agenten-Teams, die von verschiedenen Personen entwickelt wurden, führte ebenfalls zu einer hohen Entwicklungsgeschwindigkeit, allerdings musste dafür die Fragmentierung z. B. der UX gelöst werden. Hilfreich waren hier unter anderem geteilte Prompt-Templates.

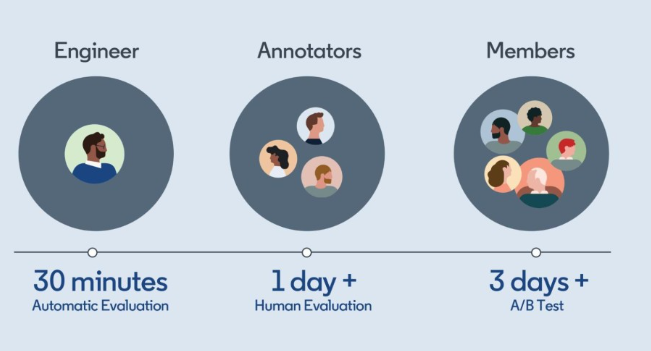
Schwierig wurde es bei der Beurteilung der Qualität der KI-Antworten durch Menschen. Hierfür benötigte das Team konsistente Richtlinien und ein skalierbares Bewertungssystem. Die automatische Bewertung ist noch nicht gut genug und wird daher nur unterstützend bei der ersten groben Bewertung durch einen Entwickler eingesetzt.
Eine weitere Herausforderung bestand darin, dass LinkedIns eigene APIs nicht für die Verarbeitung durch einen LLM konzipiert waren. LinkedIn löste das Problem, indem es um die APIs herum LLM-"Skills" aufbaute, wie eine für LLMs verständliche Beschreibung der API-Funktion und ihrer Verwendung. Die gleiche Technik wird auch für das Aufrufen von nicht-LinkedIn-APIs wie Bing-Suche und Nachrichten verwendet.
Zusätzlich schrieb das Team teils manuell Code, um wiederkehrende LLM-Fehler zu korrigieren. Laut des Teams ist das günstiger, als Prompts zu schreiben, mit denen sich das LLM selbst korrigiert. Durch die manuelle Korrektur des Codes konnte die Fehlerrate bei der Ausgabeformatierung auf 0,01 Prozent gesenkt werden.
Der lange Weg zur optimalen LLM-Leistung
Ein weiteres Problem bestand darin, die gleichbleibende Qualität der Ausgabe zu gewährleisten. Der anfänglich schnelle Fortschritt - 80 Prozent des Produkts funktionierten im ersten Monat - verlangsamte sich, als man sich den 100 Prozent näherte.
Jedes zusätzliche Prozent wurde zu einer Herausforderung, so das Team. Schließlich mussten Aspekte wie Kapazität, Latenz und Kosten unter einen Hut gebracht werden.
Beispiel: Komplexe Prompting-Methoden wie Chain of Thought verbessern zwar zuverlässig das Ergebnis, erhöhen aber Latenz und Kosten. Es dauerte weitere vier Monate, bis 95 Prozent erreicht waren.
"Wenn von Ihrem Produkt erwartet wird, dass mehr als 99 % der Antworten gut sind, dann erfordert selbst die Verwendung der fortschrittlichsten Modelle viel Arbeit und Kreativität für jedes zusätzliche Prozent", schreibt das Team.
Insgesamt zeigt der Bericht, dass der Einsatz von generativer KI zwar verlockend einfach erscheint, aber auch viele Herausforderungen mit sich bringt, wenn es um den produktiven Einsatz geht. Das LinkedIn-Team arbeitet noch an der Optimierung des Produkts, das in Kürze auf den Markt kommen soll.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.