Chameleon: Meta stellt den Vorläufer seiner GPT-4o Alternative vor

Mit Chameleon stellt Meta ein neues multimodales Modell vor, das Text und Bilder nahtlos in einem einheitlichen Tokenraum verarbeitet - und damit einen Vorläufer für eine GPT-4o-Alternative.
Meta AI stellt mit Chameleon einen neuen Ansatz vor, um multimodale Foundation Models zu trainieren, die sowohl Texte als auch Bilder als diskrete Token verarbeiten. Im Gegensatz zu bisherigen Verfahren verwendet Chameleon eine einheitliche Transformer-Architektur und verzichtet auf separate Encoder oder Decoder für verschiedene Modalitäten, wie sie etwa Unified-IO 2 einsetzt.
Metas Modell wird von Grund auf mit einer Mischung aus Texten, Bildern und Code trainiert. Dabei werden die Bilder zunächst in diskrete Token quantisiert, die analog zu den Wörtern in Texten verarbeitet werden können.
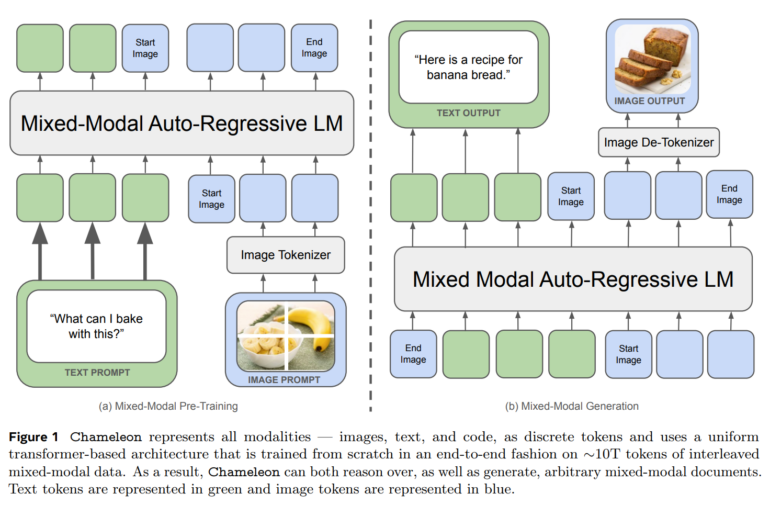
Durch diesen "Early-Fusion"-Ansatz, bei dem alle Modalitäten von Beginn an in einen gemeinsamen Darstellungsraum projiziert werden, kann Chameleon nahtlos über Modalitäten hinweg schlussfolgern und generieren. Das stellt die Forscher jedoch vor erhebliche technische Herausforderungen, insbesondere in Bezug auf die Stabilität und Skalierbarkeit des Trainings.
Um diese Herausforderungen zu meistern, führt das Team eine Reihe von architektonischen Innovationen und Trainingstechniken ein. Zudem zeigen die Forscher, wie sich die Methoden zum überwachten Finetuning, die für reine Sprachmodelle verwendet werden, auf den gemischt-modalen Fall übertragen lassen.
Chameleon zeigt durchgängig starke Leistung in allen Modalitäten
Mit diesen Techniken gelang es dem Team, das 34 Milliarden Parameter umfassende Chameleon-Modell mit 10 Billionen multimodalen Token zu trainieren. Das sind fünfmal so viele wie beim reinen Textmodell Llama-2. Das Sprachmodell Llama-3 wurde dagegen mit 15 Billionen Text-Token trainiert - zukünftige Varianten von Chameleon werden also wahrscheinlich mit deutlich mehr Token trainiert werden.
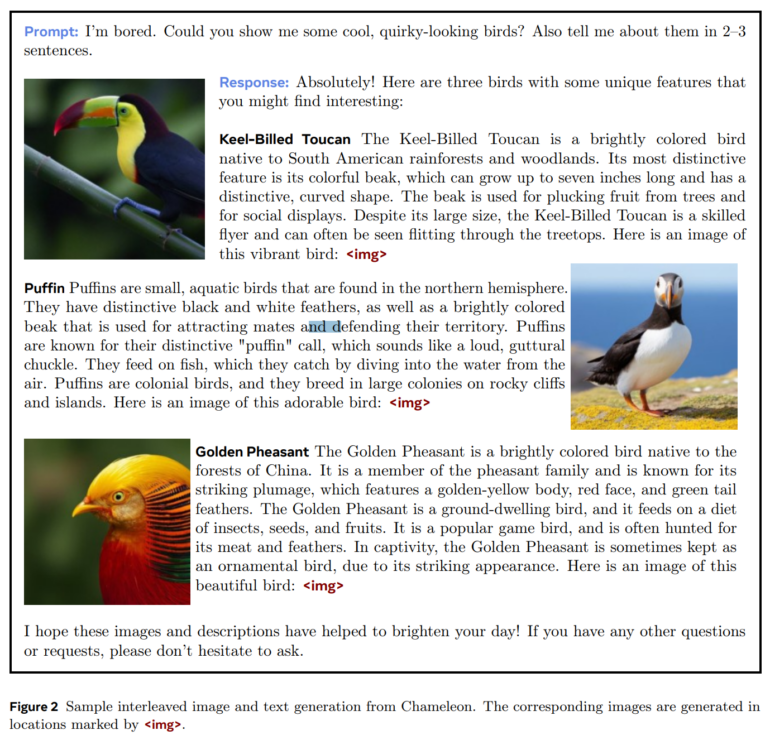
Umfangreiche Auswertungen zeigen, dass Chameleon ein breit aufgestelltes Modell für eine Vielzahl von Aufgaben ist. Bei Visual Question Answering und Image Captioning erzielt das 34-Milliarden-Modell Spitzenleistungen und übertrifft Modelle wie Flamingo, IDEFICS und Llava-1.5 und nähert sich GPT-4V an. Gleichzeitig bleibt es bei reinen Textaufgaben wettbewerbsfähig und erreicht ähnliche Leistungen wie Mixtral 8x7B und Gemini-Pro bei Tests zum gesunden Menschenverstand und zum Leseverständnis.
Am interessantesten sind jedoch die völlig neuen Fähigkeiten, die Chameleon im Bereich der gemischt-modalen Inferenz und Generierung bietet. In einem Test zeigt Meta, dass menschliche Beurteiler das 34-Milliarden-Modell Gemini-Pro und GPT-4V bevorzugen, wenn es um die Qualität gemischtmodaler Antworten auf offene Fragen geht, d.h. Fragen, die Bilder und Text mischen. Es kann auch Fragen beantworten, die Text und generierte Bilder enthalten.

Meta könnte bald eine Antwort auf GPT-4 Omni zeigen
Auch wenn über die konkrete Architektur des kürzlich vorgestellten GPT-4 omni (GPT-4o) von OpenAI wenig bekannt ist, dürfte das Unternehmen einen ähnlichen Ansatz verfolgen. Im Gegensatz zu Chameleon bezieht das Modell von OpenAI jedoch auch Audio direkt mit ein, ist vermutlich deutlich größer und generell mit deutlich mehr Daten trainiert.
Laut Armen Aghajanyan, beteiligter KI-Forscher bei Meta, ist Chameleon jedoch erst der Anfang von Metas Arbeit, das Wissen über "das nächste Paradigma des Scaling" weiterzugeben: "Early-Fusion" multimodale Modelle sind die Zukunft. Laut dem Forscher wurde das Modell zudem bereits vor fünf Monaten trainiert worden und das Team habe seitdem große Fortschritte gemacht. Die Integration weiterer Modalitäten könnte einer davon sein. Metas CEO Mark Zuckerberg hat bereits multimodale Modelle für die Zukunft angekündigt.
Chameleon ist bisher nicht verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.