Meta verwendet Instagram- und Facebook-Daten von EU-Nutzern fürs KI-Training, so lehnt ihr ab
Meta will nun auch europäische Nutzerdaten für das KI-Training nutzen. Ein Widerspruch ist möglich.
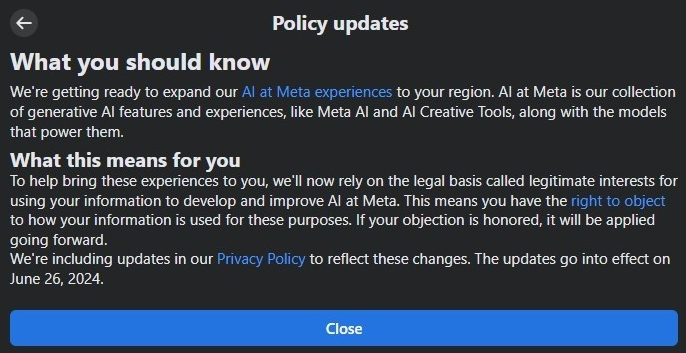
Über In-App-Benachrichtigungen informierte Meta Facebook- und Instagram-Nutzer in Europa über Änderungen der Datenschutzrichtlinien ab dem 26. Juni. Demnach nimmt das Unternehmen für sich ein "berechtigtes Interesse" in Anspruch, Nutzerdaten wie Posts, Kommentare, Audio und Nachrichten an Unternehmen für das Training der eigenen KI-Modelle zu nutzen.
Private Nachrichten an Freunde und Familie seien davon ausgenommen, nicht aber die Erwähnung des eigenen Namens oder Bilder von anderen Nutzern, auf denen man zu sehen ist.
Ein Widerspruch ist möglich (Facebook, Instagram), für den man allerdings verpflichtend begründen muss, wie einen Metas Datennutzung persönlich betrifft. Ein Verweis auf die DSGVO dürfte hier jedoch genügen. Meta gibt an, die Datennutzung nach einer positiven Prüfung der Anfrage einzustellen.
Neu ist Metas Vorgehen, Nutzerdaten für das KI-Training zu verwenden, nicht. Der KI-Assistent Meta AI wurde neben Daten aus dem Internet auch mit öffentlich zugänglichen Texten und Bildern von Facebook und Instagram trainiert wurden.
Die Texte flossen in das Sprachmodell Llama, die Bilder in den KI-Bildgenerator Emu. Darüber hinaus sei zu erwarten, dass die in Meta AI eingegebenen Daten auch für das KI-Training genutzt würden, sagte Meta-Cheflobbyist Nick Clegg.
Ob hier wirklich ein "berechtigtes Interesse" vorliegt und ob das Opt-out-Verfahren angemessen ausgestaltet ist, dürfte die EU-Behörden bald beschäftigen.
Ein soeben veröffentlichter Zwischenbericht der EU-Datenschützer zeigt, dass das ChatGPT von OpenAI weiterhin kritisch bewertet wird, hier insbesondere die Eingabe personenbezogener Daten in die Prompts und die Löschung personenbezogener Daten aus den Modellen. Für beides seien die Betreiber verantwortlich und technische Unlösbarkeit sei keine Entschuldigung für einen Datenschutzverstoß.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.