Neuer Ansatz verbessert KI-Agenten durch externes "Weltwissen"

Forschende geben KI-Agenten Zugriff auf ein "Weltwissens-Modell". So sollen sie effektiver Aufgaben lösen können, ohne ins Leere zu laufen oder Unsinn zu generieren.
Agenten, die auf großen Sprachmodellen wie GPT-4 basieren, zeigen immer wieder Potenzial bei der Planung und Lösung komplexer Aufgaben. Allerdings arbeiten sie oft nach dem Trial-and-Error-Prinzip und "halluzinieren" realitätsferne Aktionen. In einer neuen Arbeit untersuchen Forschende der Zhejiang Universität und von Alibaba, ob ein externes, gelerntes "World Knowledge Model" (WKM), das KI-Agenten mit zusätzlichem Wissen ausstattet, die Leistung der Modelle verbessern kann.
Ähnlich wie Menschen mentale Modelle der Welt aufbauen, sollen auch KI-Agenten ein solches Modell nutzen können.
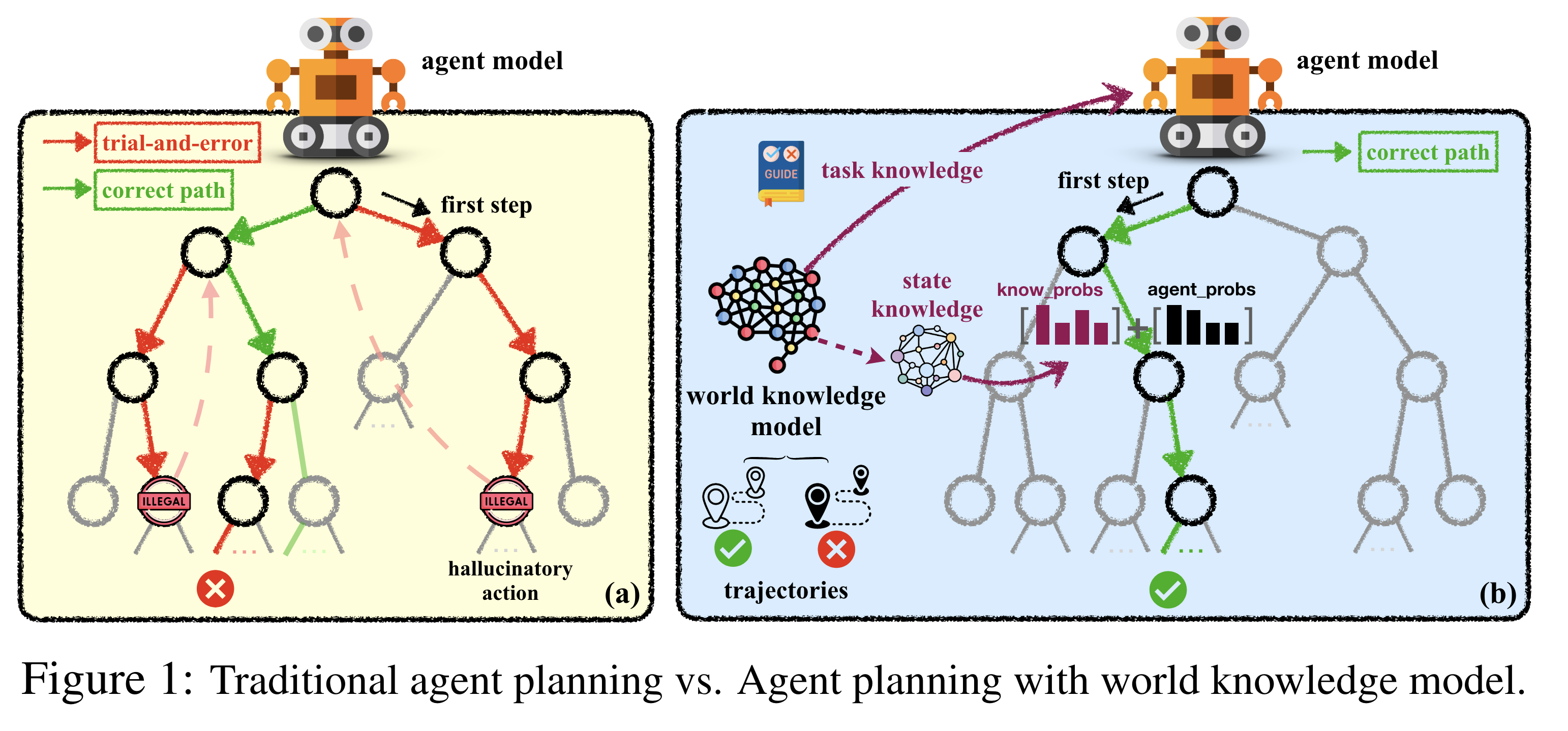
Dabei unterscheiden die Forscher zwischen globalem "Aufgabenwissen" und lokalem "Zustandswissen". Das Aufgabenwissen soll dem Agenten vorab einen Überblick über die notwendigen Schritte zur Lösung einer Aufgabe geben und Irrwege vermeiden. Das Zustandswissen hält fest, was der Agent in jedem Schritt über den aktuellen Zustand der Welt weiß. Dadurch sollen Widersprüche vermieden werden.
Um das externe Modell zu trainieren, lassen die Forscher den Agenten selbst Wissen aus erfolgreichen und erfolglosen Problemlösungsversuchen von Menschen und aus eigenen Versuchen extrahieren. Daraus generiert der Agent dann relevantes Aufgaben- und Zustandswissen.
Externes Modell für "Weltwissen" verbessert Leistung in neuen Aufgaben
In der Planungsphase gibt das WKM zunächst das Aufgabenwissen als Leitfaden vor. Für jeden Schritt generiert es dann eine Beschreibung des aktuellen Zustands. Dabei wird in einer Wissensbasis nach ähnlichen Zuständen und deren Folgeaktionen gesucht. Aus deren Wahrscheinlichkeiten und denen des Agentenmodells wird dann die nächste Aktion ausgewählt.
Experimente zeigen, dass KI-Agenten mit WKM deutlich besser abschneiden als solche ohne. Vor allem bei neuen, unbekannten Aufgaben zahlt sich das Weltwissen aus.
Konkret testete das Team die Agenten anhand von drei komplexen, realitätsnah simulierten Datensätzen: ALFWorld, WebShop und ScienceWorld.
In ALFWorld müssen die Agenten Aufgaben in einer virtuellen Haushaltssituation erfüllen, wie z.B. Gegenstände aufheben und mit Haushaltsgeräten interagieren. WebShop simuliert ein Einkaufserlebnis, bei dem die Agenten bestimmte Artikel in einem virtuellen Geschäft finden und kaufen müssen. In ScienceWorld müssen die Agenten wissenschaftliche Experimente in einer virtuellen Laborumgebung durchführen.
Das Team testete Open-Source-LLMs (Mistral-7B, Gemma-7B und Llama-3-8B) plus WKMs und verglich ihre Leistung mit der von GPT-4. Die Experimente zeigten, dass die entwickelten WKMs die Leistung der Agenten deutlich verbessern konnten und sie in einigen Aufgaben GPT-4 im Duell übertrafen. In einem separaten Experiment zeigte das Team auch, dass die kleineren Modelle plus WKM verwendet werden können, um GPT-4 zu trainieren und dessen Leistung deutlich zu verbessern.
Als Nächstes wollen die Forscher ein einheitliches Weltwissensmodell trainieren, das verschiedene Agenten bei unterschiedlichen Aufgaben unterstützen kann.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.