Das "Lost in the Middle"-Phänomen von LLMs gilt auch für viele Bilder

Forscher der UC Berkeley haben einen Benchmark entwickelt, der die Fähigkeit von KI-Modellen testet, relevante Informationen aus einer großen Menge von Bildern zu extrahieren. Die Ergebnisse zeigen die Schwächen aktueller Systeme auf.
Das Forschungsteam von Berkeley Artificial Intelligence Research (BAIR) hat mit "Visual Haystacks" (VHS) einen neuen Benchmark vorgestellt, der die Fähigkeiten von KI-Modellen zur Verarbeitung großer Bildmengen auf die Probe stellt. Der Test umfasst etwa 1.000 binäre Frage-Antwort-Paare, wobei jedes Set zwischen einem und 10.000 Bilder enthält.
Der Benchmark besteht aus zwei Aufgaben: In der "Single-Needle"-Aufgabe ist nur ein relevantes "Nadel"-Bild im "Heuhaufen" der Bilder versteckt. Bei "Multi-Needle" sind es zwei bis fünf Bilder. Die Fragen lauten entsprechend, ob das gesuchte Objekt in dem einen beziehungsweise in allen oder einem der relevanten Bilder vorhanden ist.
Die Forscher testeten verschiedene Open Source und proprietäre Modelle wie LLaVA-v1.5, GPT-4o, Claude 3 Opus und Gemini-v1.5-pro. Zusätzlich wurde ein Baseline-Modell verwendet, das zunächst Bildunterschriften mit LLaVA generiert und dann die Frage anhand des Textinhalts mit Llama 3 beantwortet.
Die Evaluierung zeigt, dass die Modelle Schwierigkeiten haben, irrelevante visuelle Informationen herauszufiltern. Ihre Leistung nimmt bei der "Single-Needle"-Aufgabe deutlich ab, je mehr Bilder der Datensatz enthält.
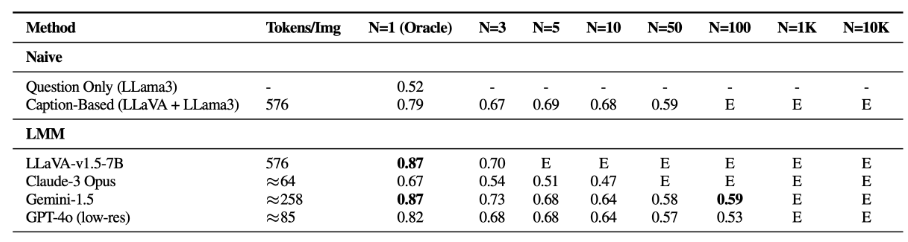
Einfache zweistufige Ansätze, bei denen zunächst Bildunterschriften generiert und dann per Sprachmodell ausgewertet werden, übertreffen bei "Multi-Needle" alle getesteten LMMs (Large Multimodal Model). Das deute auf eine unzureichende Fähigkeit der LMMs hin, Informationen aus mehreren Bildern zu verarbeiten, was wiederum den aktuellen Nutzen großer Kontextfenster relativiert.

Außerdem reagieren die Modelle sehr empfindlich auf die Position des zu suchenden Bildes in der Sequenz: Befindet sich das relevante Bild in der Mitte der Sequenz, ist die Leistung deutlich schlechter, als wenn es sich am Anfang oder Ende befindet.
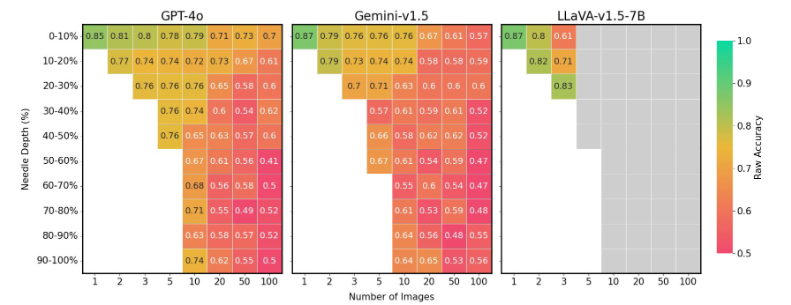
Die Forschenden ziehen hier einen Vergleich mit dem "Lost in the Middle"-Phänomen in der Sprachverarbeitung, bei dem Sprachmodelle besonders den Anfang und das Ende eines Dokuments berücksichtigen und den Inhalt in der Mitte des Dokuments eher ignorieren. Zudem haben LLMs auch bei Text ein Problem damit, aus großen Textmengen sinnvolle Schlüsse zu ziehen.
Bilder-RAG verbessert Antworten
Das Forschungsteam hat ein für die Bildverarbeitung optimiertes RAG-System namens MIRAGE (Multi-Image Retrieval Augmented Generation) entwickelt. Es komprimiert visuelle Token, verwendet einen gemeinsam trainierten Retriever, um irrelevante Bilder herauszufiltern, und wird mit Multi-Image-Reasoning-Daten trainiert. Auf diese Weise erreicht es eine bessere Leistung sowohl bei VHs als auch bei komplexeren Aufgaben zur Beantwortung visueller Fragen.
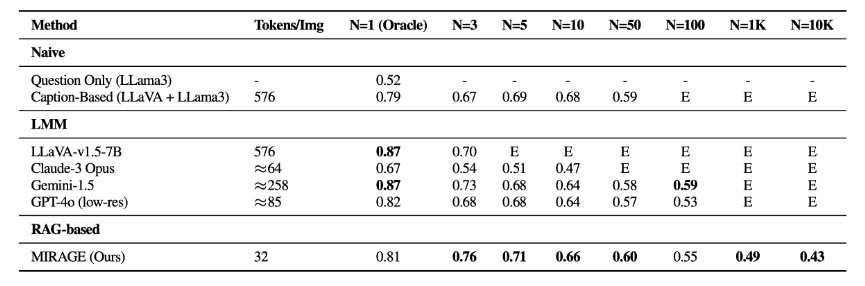
Die Forscher empfehlen, dass künftige LMM-Projekte ihre Modelle mit dem Visual Haystacks Framework testen, um potenzielle Schwächen vor dem Einsatz zu identifizieren und zu beheben. Den Benchmark stellen sie bei Github zur Verfügung. Multi-Image Question Answering sei zudem ein wichtiger Schritt auf dem Weg zur Artificial General Intelligence (AGI).
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.