Alibabas Mini-Open-Source-Modell Qwen2-VL analysiert mehr als 20 Minuten Videomaterial
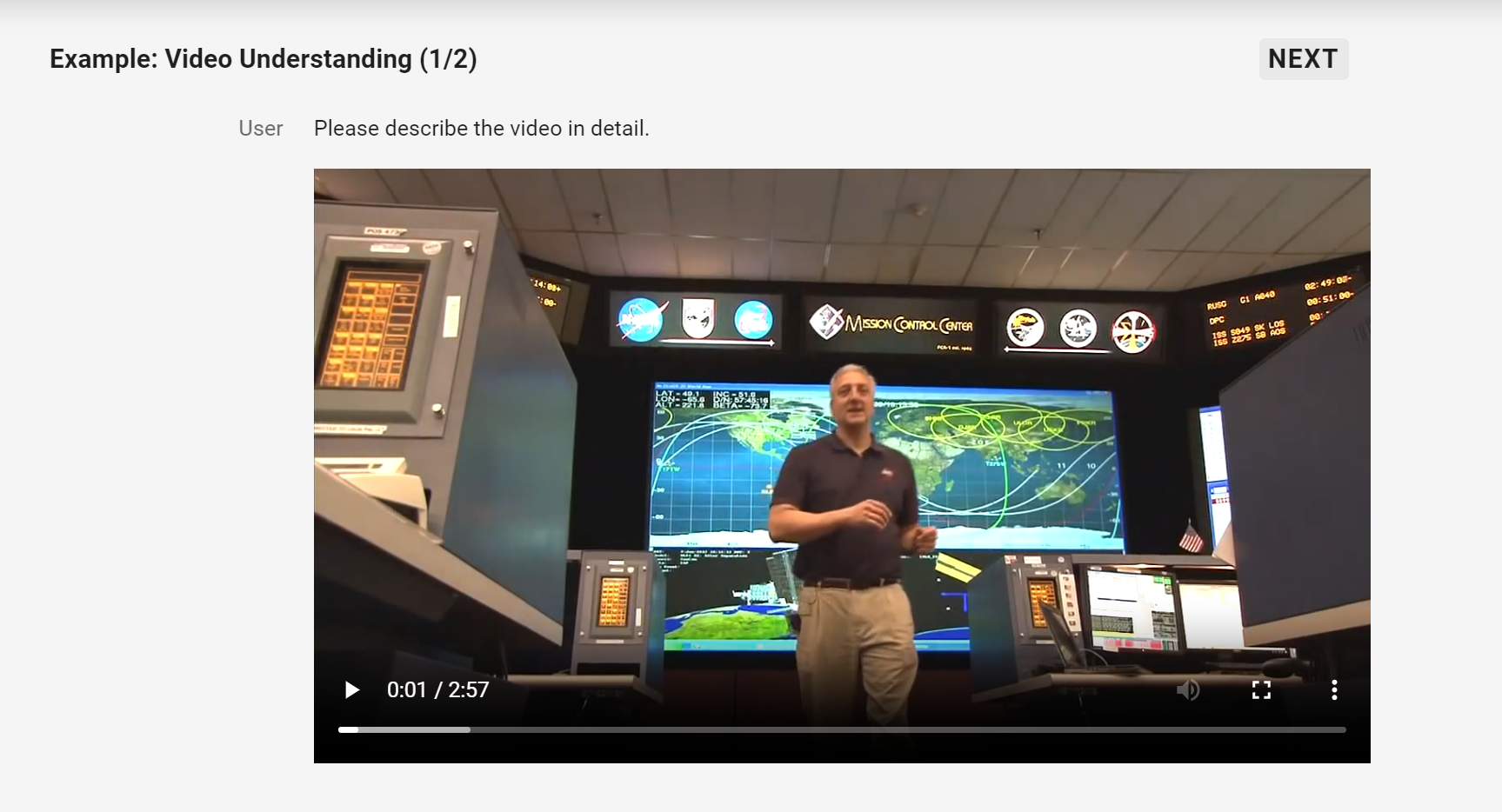
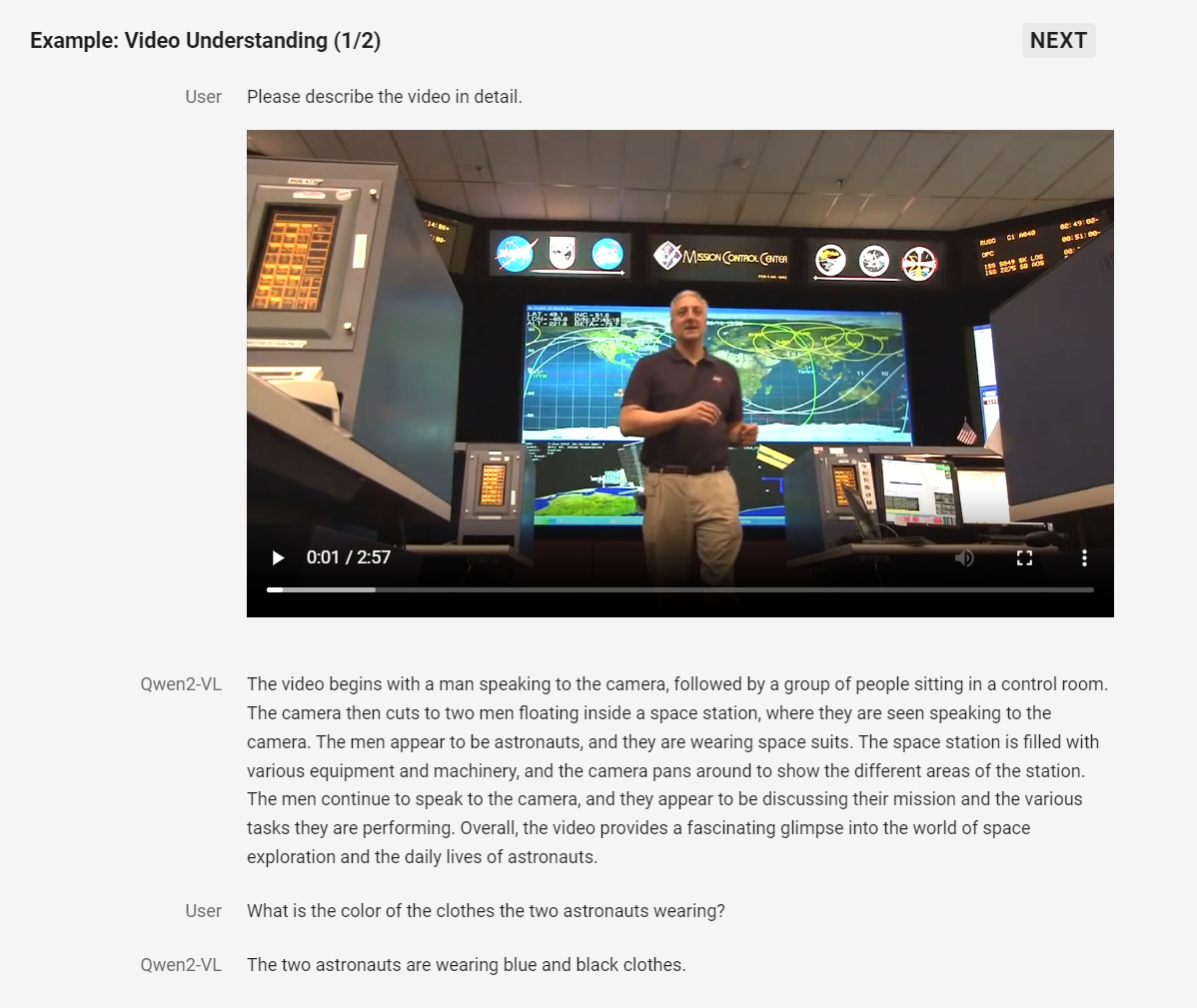
Alibaba Cloud hat eine neue Version seines Vision-Language-Modells Qwen2-VL vorgestellt, das Bilder in verschiedenen Auflösungen und Formaten sowie Videos mit einer Länge von über 20 Minuten verstehen kann. Die kleineren Varianten mit 2 und 7 Milliarden Parametern sind als Open Source verfügbar.
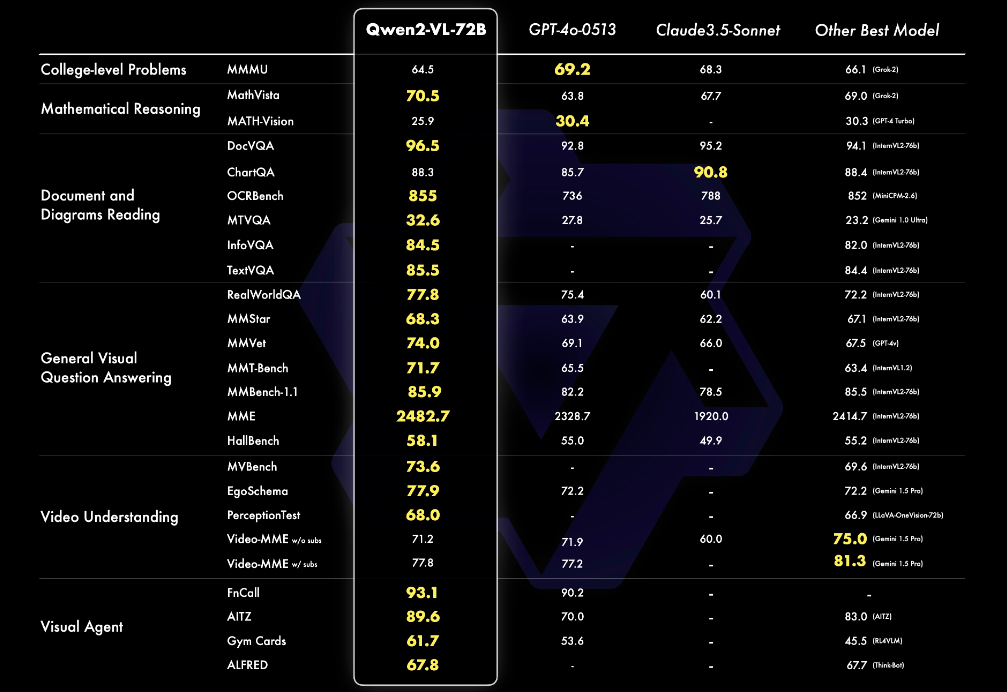
Alibabas KI-Forschungsabteilung Qwen hat eine neue Version seines Vision-Language-Modells Qwen2-VL veröffentlicht. Laut des Qwen-Teams erreicht das Modell in verschiedenen Benchmarks für visuelle Verständnisaufgaben wie MathVista, DocVQA, RealWorldQA und MTVQA State-of-the-Art-Ergebnisse.
Qwen2-VL als visueller Agent
Eine Besonderheit von Qwen2-VL ist die Fähigkeit, Videos mit einer Länge von über 20 Minuten zu analysieren und darauf basierende Fragen zu beantworten, Dialoge zu führen oder Inhalte zu generieren.
Qwen2-VL soll sich auch als visueller Agent eignen, der mit Geräten wie Mobiltelefonen oder Robotern integriert werden kann. Auf Basis von visuellen Informationen und Textanweisungen soll das Modell komplexe Schlussfolgerungen ziehen, Entscheidungen treffen und automatisierte Aktionen ausführen können.
Qwen2-VL unterstützt neben Englisch und Chinesisch auch das Verständnis von Texten in Bildern in verschiedenen Sprachen, darunter die meisten europäischen Sprachen, Japanisch, Koreanisch, Arabisch und Vietnamesisch.
Als Einschränkungen nennt Qwen unter anderem die fehlende Unterstützung von Audiodaten, Schwächen beim Zählen von Objekten und beim räumlichen Schlussfolgern in 3D-Umgebungen sowie eine Begrenzung des Wissens auf den Stand von Juni 2023.
Drei Modellgrößen, zwei davon Open Source
Qwen2-VL ist in drei Größen mit 2, 7 und 72 Milliarden Parametern verfügbar. Die kleineren Varianten mit 2 und 7 Milliarden Parametern sind auf GitHub und Hugging Face unter der Apache-2.0-Lizenz als Open Source veröffentlicht worden.
Für die 72-Milliarden-Variante stellt Alibaba vorerst eine API zur Verfügung. Der Zugriff erfolgt über die Plattform DashScope, wo man sich registrieren und einen API-Schlüssel anfordern muss.
Um die Modelle mit dem Hugging-Face-Transformers-Framework zu nutzen, empfiehlt Qwen eine Installation aus dem Quellcode. Zusätzlich gibt es ein Toolkit namens "qwen-vl-utils", das die Verarbeitung verschiedener visueller Eingabeformate erleichtern soll.
Qwen sind leistungsfähige KI-Modelle, die von der Cloud-Computing-Einheit des chinesischen E-Commerce-Giganten Alibaba entwickelt wurde. Die neueste Version, Qwen2 von Anfang Juni, bietet bedeutende Verbesserungen in verschiedenen Bereichen wie Programmierung, Mathematik, Logik und mehrsprachigem Verständnis. Die Modelle wurden mit Daten in 27 weiteren Sprachen, darunter auch Deutsch, Französisch, Spanisch, Italienisch, Russisch, neben Englisch und Chinesisch trainiert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.