Llama 3.2: Meta bringt winzige Smartphone-Modelle und große mit Bildverständnis

Nur wenige Monate nach der letzten Veröffentlichung folgt der nächste Aufschlag in der Llama-Reihe. Auf das riesige 405B-Textmodell von Llama 3.1 folgen mit Version 3.2 zwei winzige Modelle für Smartphones und zwei größere, die Bilder verstehen können.
Metas neuste Sprachmodellausgabe enthält zunächst zwei Textmodelle mit ein bzw. drei Milliarden Parametern, die auf Smartphones laufen können und dort etwa Texte zusammenfassen, Texte umschreiben oder bestimmte Funktionen in anderen Apps aufrufen sollen.
Video: Meta
Dafür arbeitete Meta eng mit wichtigen Hardware-Herstellern wie Qualcomm, MediaTek und Arm zusammen. Die lokale Verarbeitung bringt laut Meta vor allem Vorteile in puncto Geschwindigkeit und Datenschutz mit sich.
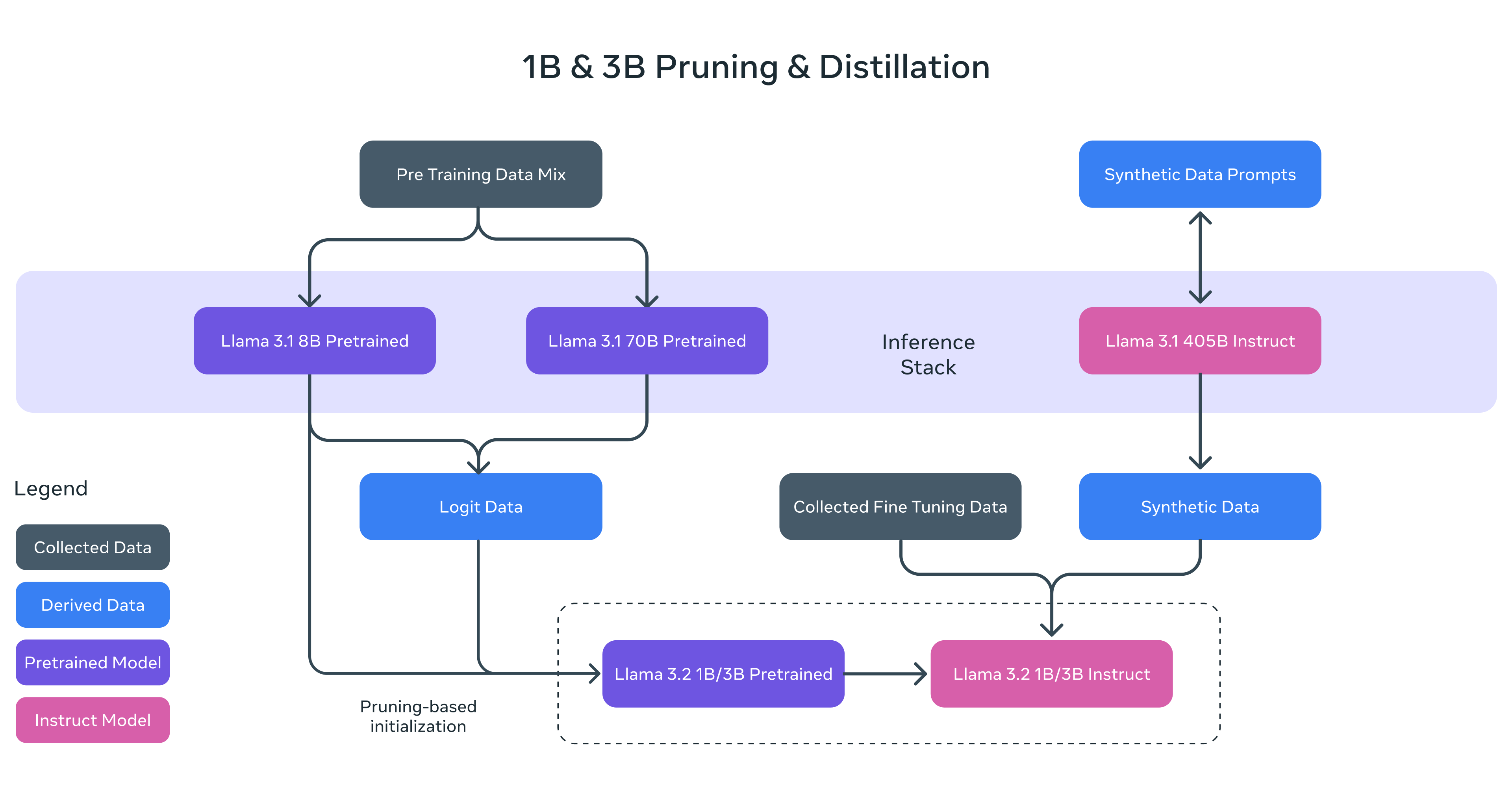
Um die leichtgewichtigen 1B und 3B Modelle zu optimieren, setzte Meta auf eine Kombination aus Pruning und Wissensübertragung durch größere Lehrer-Modelle. Beim strukturierten Pruning in einem einzigen Durchgang vom vorangehenden Llama-3.1-8B-Modell wurden systematisch Teile des Netzwerks entfernt und die Gewichte angepasst.
Auch Visionmodelle mit 11 und 90 Milliarden Parametern
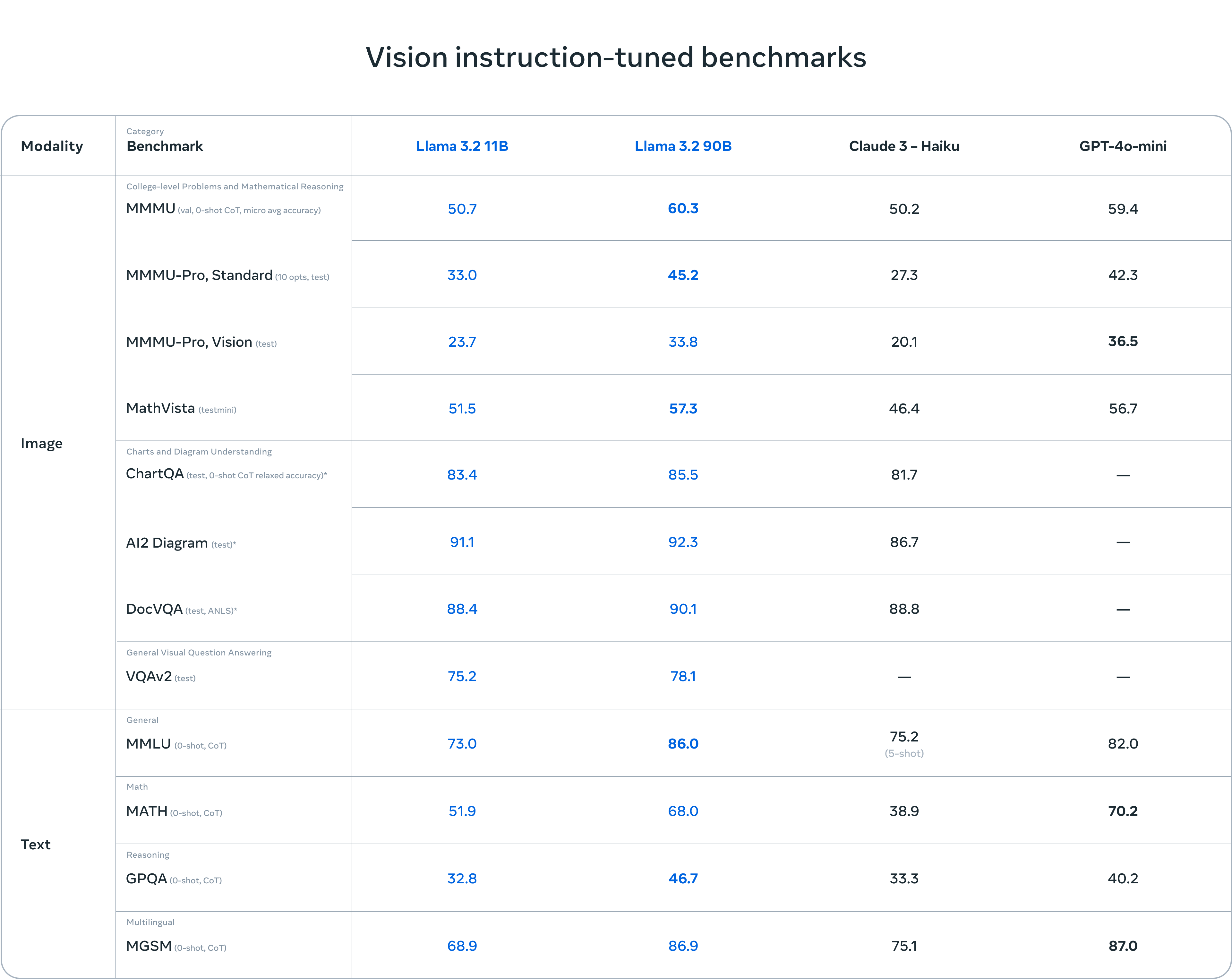
Zusätzlich zu den leichtgewichtigen Modellen veröffentlicht Meta seine ersten Vision-Modelle mit 11 und 90 Milliarden. Llama 3.2 11B und 90B können nach Benchmarks von Meta bei Aufgaben zum Bildverständnis mit führenden geschlossenen Modellen wie Claude 3 Haiku und GPT-4o mini mithalten. Open-Source-Konkurrent Mistral hatte mit Pixtral kürzlich ebenfalls sein erstes Vision-Modell enthüllt, das allerdings eine deutlich kleinere Parameterzahl aufweist.
Video: Meta
Um die Eingabe von Bildern zu ermöglichen, hat Meta die Llama 3.2 Visionmodelle mit einer neuartigen Architektur ausgestattet. Dabei werden zusätzliche Adapter-Gewichte trainiert, die den vortrainierten Bildencoder in das vortrainierte Sprachmodell integrieren.
Im Gegensatz zu anderen offenen multimodalen Modellen sind die Llama-3.2-Vision-Modelle sowohl in vortrainierten als auch in ausgerichteten Versionen für das Fine-Tuning und die lokale Bereitstellung verfügbar. Bei der Leistung liegen sie auf Augenhöhe mit zuletzt veröffentlichten Modellen wie Pixtral von Mistral oder Qwen 2 VL.
Llama-Stack-API soll RAG und mehr vereinfachen
Um die Entwicklung mit Llama-Modellen zu vereinfachen, führt Meta die ersten offiziellen Llama-Stack-Distributionen ein. Diese ermöglichen die schlüsselfertige Bereitstellung von Anwendungen mit Retrieval-Augmented Generation (RAG) und Tool-Anbindung in verschiedenen Umgebungen.
Für die API arbeitet Meta unter anderem mit AWS, Databricks, Dell und Together AI zusammen. Hinzu kommen unter anderem eine Schnittstelle für die Kommandozeile (CLI) und Code für verschiedene Programmiersprachen.
Meta fehlt mobil der Heimvorteil
Die Veröffentlichung von Llama 3.2 stellt einen weiteren Meilenstein in Metas Bemühungen dar, Open-Source-KI zum Standard zu machen. Allerdings kamen um diesen Begriff im Kontext des US-Unternehmens erst kürzlich Diskussionen auf. So werfen Kritiker:innen ihm unter anderem vor, Trainingsdaten zurückzuhalten.
Erst im Juli hatte Meta die vorhergehende Version 3.1 mit bis zu 405 Milliarden Parametern veröffentlicht, das sich, trotz des Trainings auf synthetischen Daten, gegenüber kommerziellen Modellen behaupten konnte.
Llama 3.2 ist im Gegensatz dazu auf Geräte mit beschränkten Ressourcen wie Smartphones optimiert. Ob es da jedoch überhaupt sinnvoll zur Anwendung kommt, bleibt abzuwarten – schließlich gibt es unter Android mit Gemini Nano und unter iOS mit Apple Intelligence eigene und tief ins System integrierte Lösungen für die lokale KI-Verarbeitung.
Mit dem Vision-Upgrade für die Llama-Modelle hat Meta vor allem seinem KI-Assistenten Meta AI eine wichtige Funktion verpasst, die vielen Nutzer:innen auf den zahlreichen Plattformen des Social-Media-Giganten zugutekommt. Das könnte auf lange Sicht etwa ChatGPT Kund:innen kosten, das vor rund einem Jahr diese Funktion erhalten hat.
Die Llama-3.2-Modelle stehen zum Download auf llama.com und Hugging Face sowie über ein breites Ökosystem von Partnerplattformen zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.