Zugriff auf externe Daten macht Open-Source-Modelle besser als GPT-4
Aktuelle Forschungsergebnisse legen nahe, dass die Anwendung von Retrieval-Augmented Generation (RAG) in Kombination mit umfangreichen Daten die Leistung von LLMs erheblich verbessert.
Eine aktuelle Forschung von einem Team bei Pinecone hat den Einfluss der Anwendung von Retrieval-Augmented Generation (RAG) auf die Leistung großer Sprachmodelle in generativen KI-Anwendungen untersucht. Die Ergebnisse zeigen, dass RAG die Leistung von LLMs wesentlich verbessert, sogar bei Fragen, die innerhalb ihres Trainingsbereichs liegen. Darüber hinaus nimmt der positive Effekt zu, wenn mehr Daten für die Abrufung verfügbar sind. Das Unternehmen testete mit Stichprobengrößen von bis zu einer Milliarde Dokumenten.
RAG ist eine Methode, die die Leistung von LLMs verbessert, indem sie diesen Modellen ermöglicht, auf eine große Menge externer Informationen zuzugreifen. Diese Methode erweitert das Wissen der Modelle erheblich und ermöglicht es ihnen, genauere, zuverlässigere und kontextuell relevantere Antworten zu generieren.
Open-Source-Modelle mit RAG deutlich zuverlässiger als mit internen Daten
Für das Experiment verwendeten die Forscher das Falcon RefinedWeb Dataset, das 980 Millionen Webseiten von CommonCrawl enthält. Diese wurden in Abschnitte von 512 Token aufgeteilt, aus denen eine zufällige Stichprobe von einer Milliarde gezogen wurde. Anschließend generierten sie mit GPT-4-Turbo 1.000 offene Fragen, die eine breite Verteilung über den Datensatz aufwiesen. Die Modelle wurden dann getestet, indem sie angewiesen wurden, diese Fragen zu beantworten, wobei sie entweder nur auf ihr internes Wissen oder auf die mit RAG abgerufenen Informationen zurückgreifen sollten.
In allen Experimenten wurde folgender Prompt benutzt, um dem Modell zu befehlen, Informationen ausschließlich aus der Wissensdatenbank zu entnehmen und Halluzinationen vorzubeugen. Große Sprachmodelle neigen bekanntlich dazu, eine Antwort zu erfinden, auch wenn sie sie nicht kennen.
Use the following pieces of context to answer the user question. This context retrieved from a knowledge base and you should use only the facts from the context to answer.
Your answer must be based on the context. If the context not contain the answer, just say that 'I don't know', don't try to make up an answer, use the context.
Don't address the context directly, but use it to answer the user question like it's your own knowledge.
Answer in short, use up to 10 words.Context:
{context}Aus der Studie
In den Experimenten mit den Open-Source-Modellen LLaMA-2-70B und Mixtral-8x-7B wurde zudem deutlich, wie wichtig es ist, sich streng an den gegebenen Kontext zu halten und nicht auf internes Wissen zurückzugreifen, was mit folgendem Prompt sichergestellt werden sollte.
Your answer must be based on the context, don't use your own knowledge. Question: {question}
Aus der Studie
Mehr Daten sind besser?
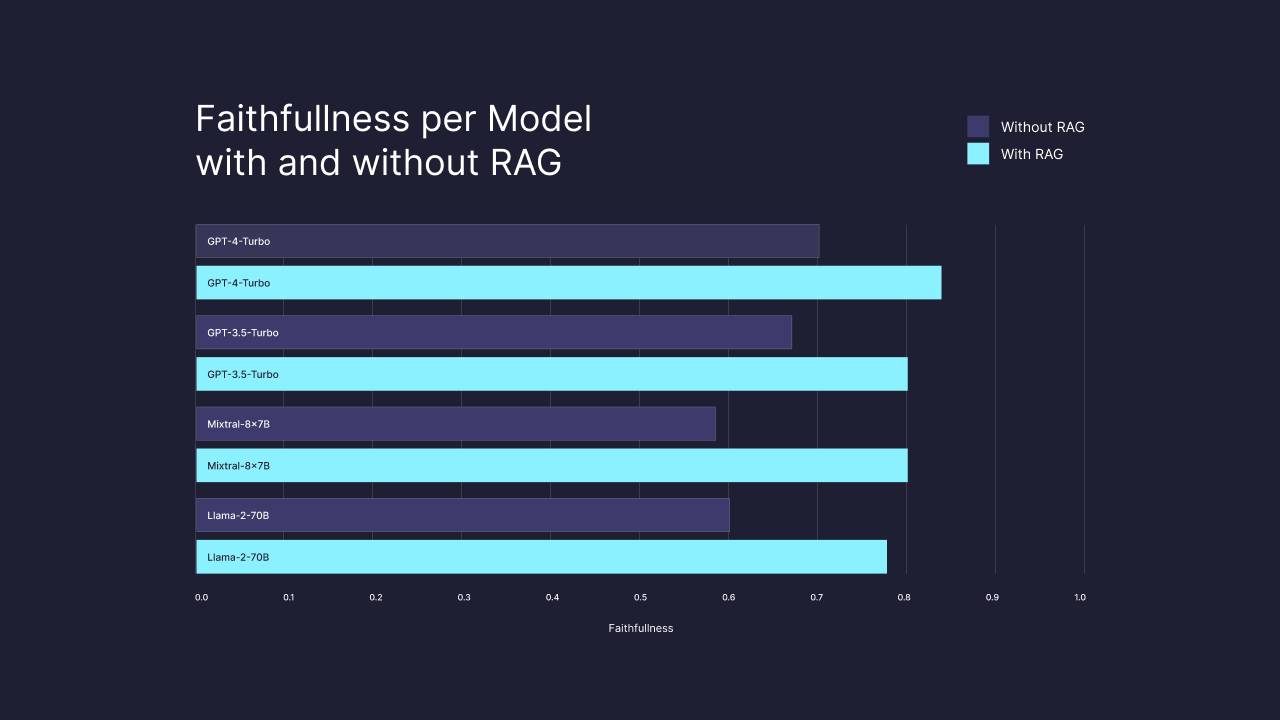
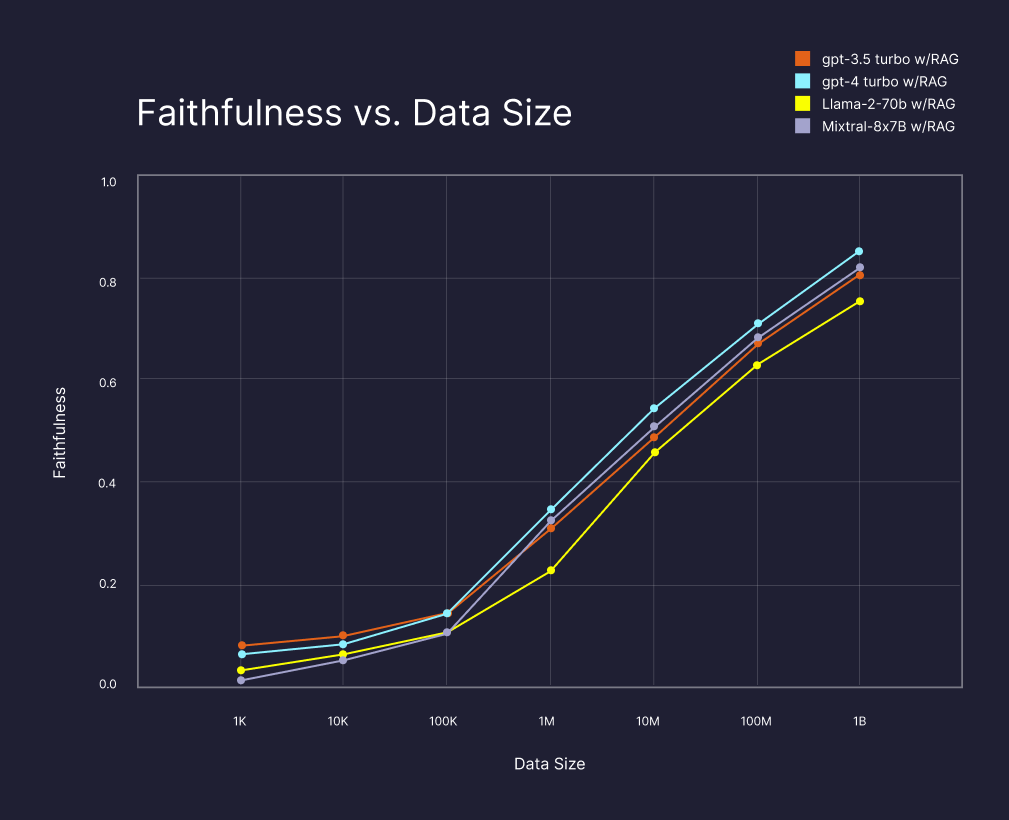
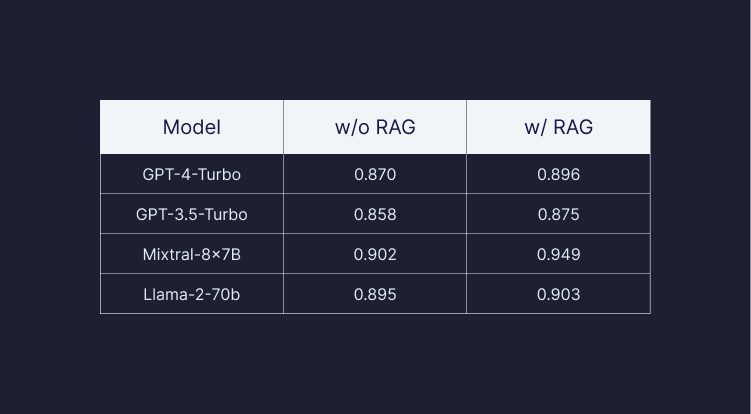
Die Studie von Pinecone zeigt, dass die einfache Verfügbarkeit von mehr Daten für die Kontextabrufung die Ergebnisse der LLMs erheblich verbessert, sogar wenn die Datengröße auf eine Milliarde erhöht wird, unabhängig vom gewählten LLM. Im Vergleich zu GPT-4 alleine verbesserte GPT-4 mit RAG und ausreichenden Daten die Qualität der Antworten signifikant um 13 Prozent für die Metrik "Faithfulness", sogar bei solchen Informationen, auf die das LLM trainiert wurde. Diese Metrik sagt nach Pinecone aus, wie sachlich richtig eine Antwort ist.
Darüber hinaus zeigte die Studie, dass die gleiche Leistung (80 Prozent Faithfulness) mit anderen LLMs, wie dem Open-Source-Modell LLaMa-2-70B und Mixtral-8x-7B, erreicht werden kann, solange genügend Daten über eine Vektor-Datenbank verfügbar gemacht werden.
Als zusätzliche Metrik zur Faithfulness haben die Forscher:innen die Relevanz der Antworten überprüft. Diese zeigt in allen Experimenten hohe Werte, die durch RAG nur leicht gesteigert werden können, bei GPT-4 um bis zu drei und bei LLaMa um bis zu fünf Prozent.
Die Forschungsergebnisse deuten darauf hin, dass RAG mit ausreichenden Daten eine signifikante Verbesserung der Ergebnisse großer Sprachmodelle erzielt. Das hatten vorherige Untersuchungen beispielsweise von Microsoft und Google schon vermuten lassen. Jetzt zeigt sich jedoch das Potenzial der Skalierung: Je mehr Daten durchsucht werden können, desto korrekter sind die Ergebnisse.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.