Studie deckt gravierende Logik-Schwächen bei kleinen KI-Sprachmodellen auf

Eine neue Untersuchung zeigt erhebliche Defizite in der Schlussfolgerungsfähigkeit von KI-Sprachmodellen. Besonders kleinere und kosteneffiziente Modelle haben Schwierigkeiten bei verketteten Mathematikaufgaben auf Grundschulniveau.
Forscher des Mila-Instituts, Google DeepMind und Microsoft Research haben in einer aktuellen Studie erhebliche Unterschiede in der Schlussfolgerungsfähigkeit verschiedener KI-Sprachmodelle aufgedeckt. Die Wissenschaftler untersuchten, wie gut die Modelle bei der Lösung von verketteten mathematischen Textaufgaben auf Grundschulniveau abschneiden.
Dazu entwickelten sie den "Compositional GSM"-Test, bei dem zwei Textaufgaben aus dem bekannten GSM8K-Datensatz so kombiniert werden, dass die Antwort der ersten Aufgabe als Variable in der zweiten Aufgabe verwendet wird. Die Ergebnisse zeigen, dass viele Modelle deutlich schlechter abschneiden als erwartet.
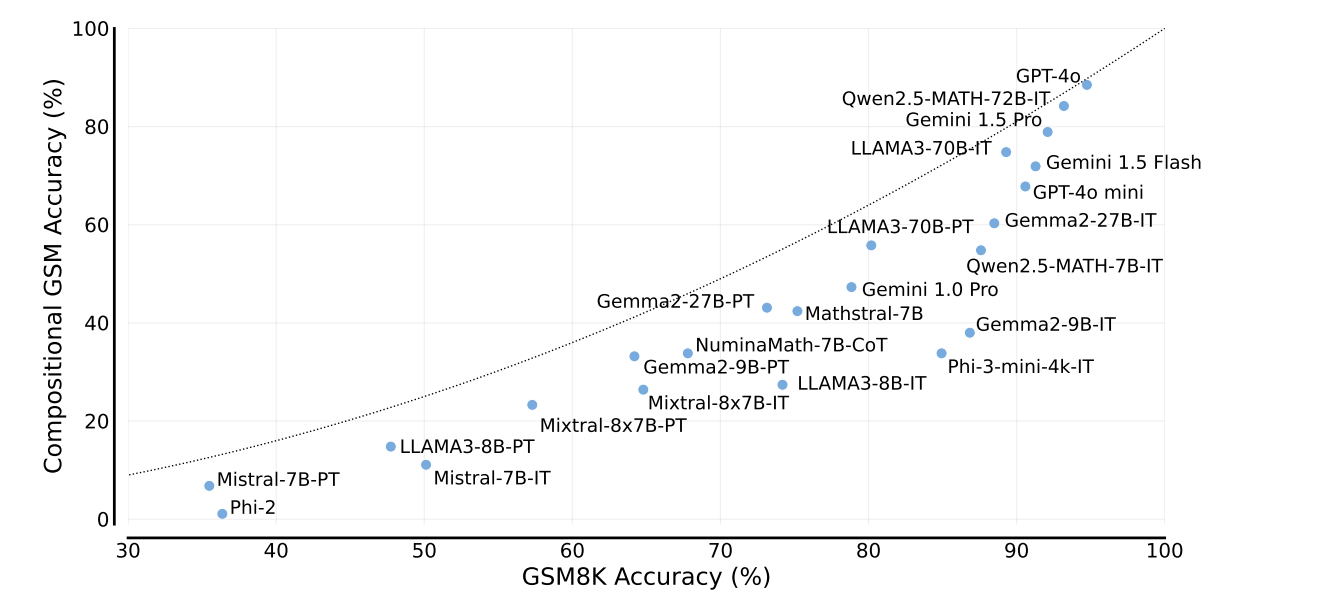
"Wir beobachten eine signifikante Lücke in der Schlussfolgerungsfähigkeit der meisten Sprachmodelle", erklären die Autoren um Arian Hosseini vom Mila-Institut. Diese "Reasoning Gap" sei bei kleineren, kosteneffizienteren und sogar bei auf Mathematik spezialisierten Modellen besonders ausgeprägt.
Alles nur gelernt?
Die Studie zeigt gravierende Schwächen bei kleineren und kostengünstigeren Sprachmodellen, wenn es um komplexere Schlussfolgerungen geht. Während diese Modelle in herkömmlichen mathematischen Benchmarks wie GSM8K oft ähnlich gut abschneiden wie ihre größeren Pendants, weisen sie im Compositional GSM Test eine zwei- bis zwölfmal größere Logiklücke auf.
Beispielsweise fällt GPT-4o mini im Compositional GSM deutlich hinter GPT-4o zurück, während es im Original-Benchmark fast gleichauf liegt. Ähnliche Muster zeigen sich bei anderen Modellfamilien wie Gemini und LLAMA3.
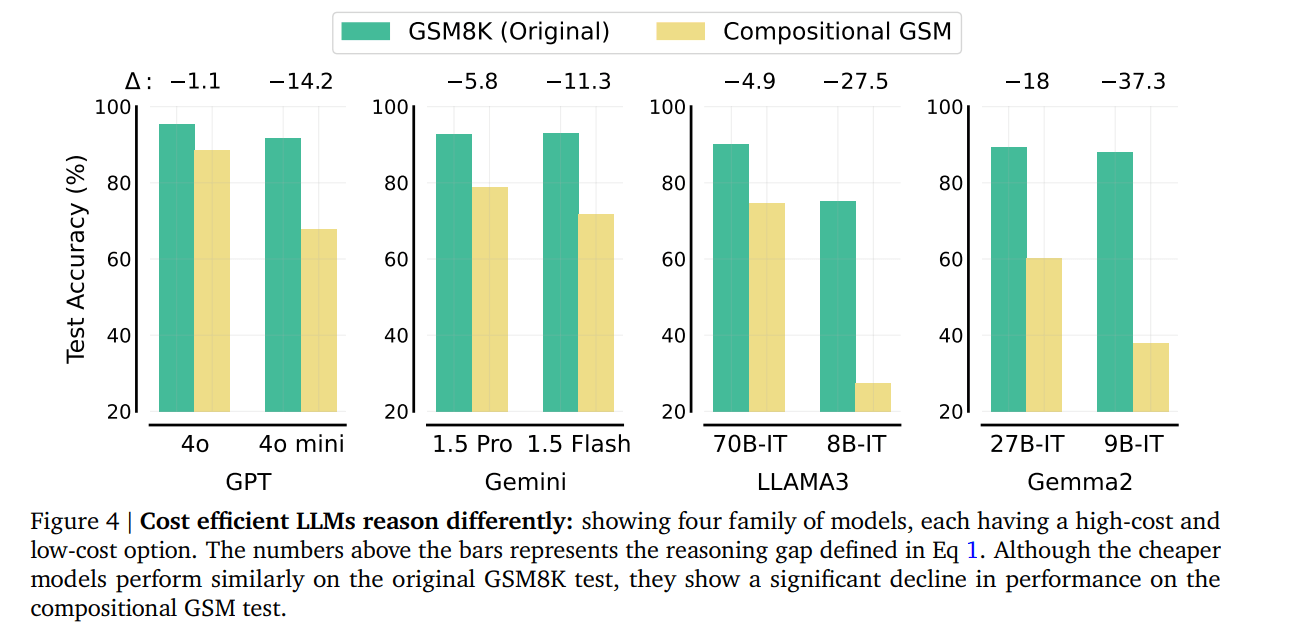
Diese Ergebnisse deuten laut den Forschern darauf hin, dass kleine Modelle zwar in der Lage sind, oberflächliche Muster in Standardaufgaben zu erkennen, aber Schwierigkeiten haben, dieses Wissen auf neue Kontexte zu übertragen.
Die Forscher vermuten, dass die derzeitigen Trainingsmethoden für kleine Modelle zu sehr auf die Optimierung gängiger Benchmarks ausgerichtet sind, was zu Lasten der allgemeinen Schlussfolgerungsfähigkeit gehe-
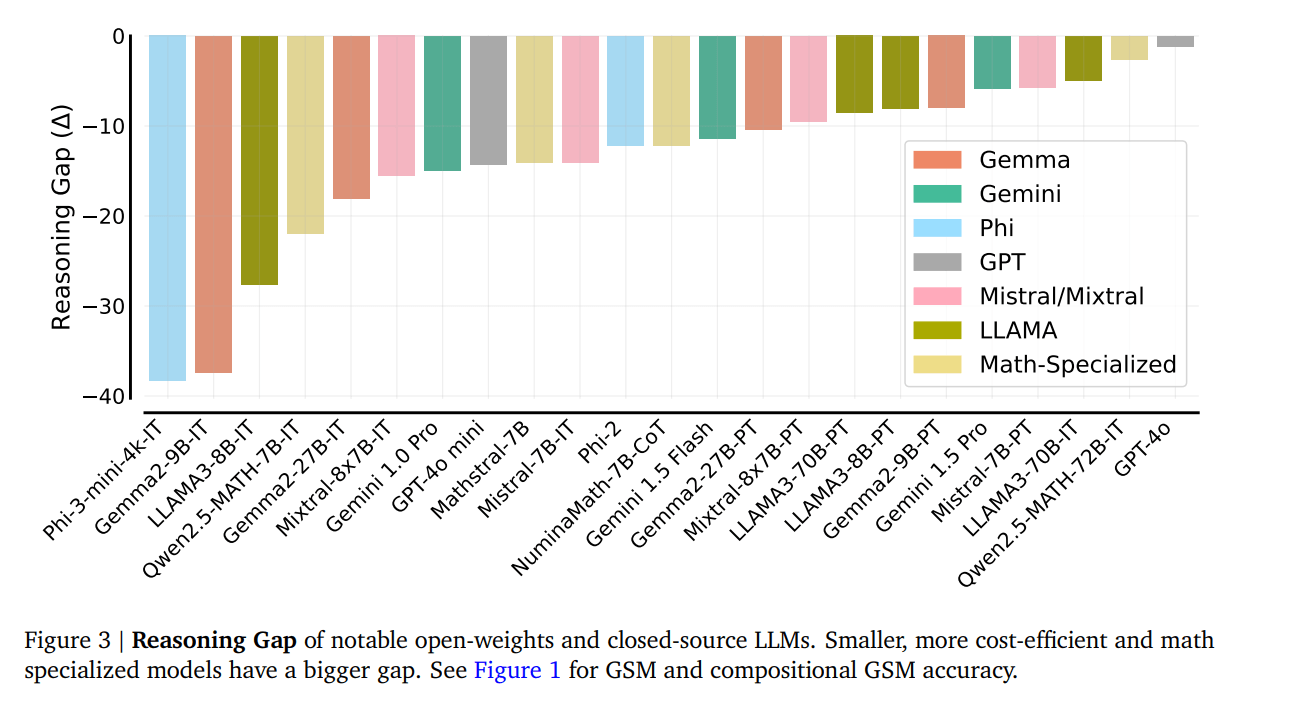
Ähnliche Schwächen zeigen auch die kleinen, auf Mathematik spezialisierten Modelle. So erreicht Qwen2.5-Math-7B-IT zwar eine Genauigkeit von über 80 Prozent bei schwierigen Gymnasialaufgaben, löst aber weniger als 60 Prozent der verketteten Grundschulaufgaben richtig.
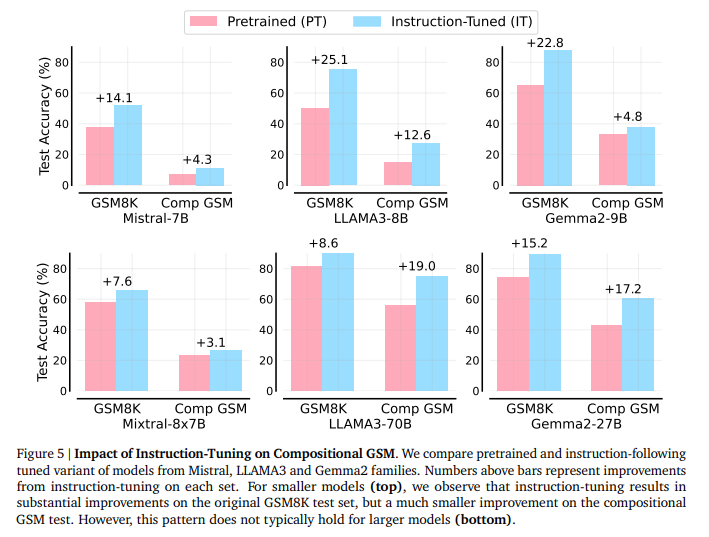
Besonders aufschlussreich sind die Ergebnisse zum Instruction Tuning, einer Methode zur Verfeinerung von KI-Sprachmodellen. Dabei wird das Modell darauf abgestimmt, bestimmte Anweisungen oder Aufgaben zu verstehen und auszuführen.
Bei kleinen Modellen führt das Instruction Tuning zu deutlichen Verbesserungen im originalen GSM8K-Test, aber nur zu geringen Verbesserungen im Compositional GSM. Bei den Instruktionsvarianten größerer Modelle ist dieser Effekt nicht zu beobachten. Das deute auf grundsätzliche Unterschiede in der Lern- und Generalisierungsfähigkeit kleinerer Modelle hin.
Die Studie ist insofern nicht ganz aktuell, da das neue, für Logik optimierte o1-Modell von OpenAI nicht getestet wurde. Auch die Gemini-Modelle von Google sollen nach Updates in Mathematik besser abschneiden.
Ein Mathematikprofessor hat kürzlich gezeigt, dass ihm mit o1 ein mathematischer Beweis gelungen ist, an dem er zuvor mit anderen LLMs gescheitert war. Ein Mensch konnte die Aufgabe jedoch schneller und eleganter lösen.
Mehr als nur ein neuer Benchmark
Die Forscher betonen, dass diese systematischen Unterschiede bisher von den gängigen Bewertungsmethoden verdeckt wurden. Sie warnen davor, die Fähigkeiten kleiner Modelle zu überschätzen und fordern eine Neubewertung von Entwicklungsstrategien für kostengünstige KI-Systeme.
Insgesamt wirft die Studie die Frage auf, ob kleine und kostengünstige Modelle grundsätzlich in ihrer Fähigkeit zu komplexeren Schlussfolgerungen und Verallgemeinerungen eingeschränkt sind. Dies könnte weitreichende Konsequenzen für den Einsatz solcher Systeme in der Praxis haben.
Das Ergebnis wirft auch einen Schatten auf das Narrativ der letzten Monate, dass Sprachmodelle zwar nicht wesentlich leistungsfähiger, aber effizienter geworden seien und man durch Skalierung dieser effizienteren Modelle in neue Leistungssphären vorstoßen könne.
Die Autoren betonen, dass es nicht ihr Ziel war, mit dem Compositional GSM Test einen weiteren Benchmark für Sprachmodelle zu schaffen. Vielmehr sehen sie ihre Arbeit als eine Fallstudie, die einen tieferen Einblick in die Funktionsweise und Grenzen aktueller KI-Systeme geben soll.
Durch die Verkettung von Aufgaben wollen die Wissenschaftler testen, ob die Modelle wirklich in der Lage sind, gelerntes Wissen flexibel anzuwenden und zu kombinieren. Dies sei entscheidend, um echtes Verständnis von oberflächlichem Mustererkennen zu unterscheiden.
Die Forscher sehen den Compositional GSM Test als ein Werkzeug, um die tatsächlichen Fähigkeiten von Sprachmodellen besser zu verstehen. Sie hoffen, dass ihre Methodik auch auf andere Domänen und Benchmarks angewendet werden kann, um ein umfassenderes Bild der KI-Fähigkeiten zu erhalten.
Die Logik-Probleme von Sprachmodellen sind gut dokumentiert
Dass LLMs Probleme mit Logik haben, ist keine neue Erkenntnis. Schon frühere Studien zeigten, dass Sprachmodelle bei einfachsten logischen Schlüssen schwach sind. So kennen sie zwar faktisch die Mutter von Tom Cruise, können aber nicht ableiten, dass Cruise dann der Sohn dieser Mutter ist - der sogenannte "Reversal Curse".
Eine aktuelle Studie demonstriert die logischen Schwächen anhand einer einfachen Textaufgabe. Selbst führende Modelle wie GPT-4o und Claude konnten diese nur sporadisch lösen, eine härtere Version brachte sie an den Rand des Zusammenbruchs ihrer Denkfähigkeit. Dabei zeigten die Modelle starkes Selbstvertrauen in ihre falschen Lösungen und setzten Pseudo-Logik ein, um diese zu rechtfertigen.
Auch einfache Planungsrätsel wie das Wolf-Ziege-Kohl-Problem können aktuelle Sprachmodelle nicht zuverlässig lösen und liefern mitunter absurde Lösungen. Diese Ergebnisse sind umso bemerkenswerter, als dieselben Modelle bei gängigen Logik-Benchmarks Spitzenwerte erzielen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.