Am "Rande des Chaos": Komplexe Systeme fördern Intelligenz in KI-Modellen

Forscher der Yale University haben untersucht, wie die Komplexität von Trainingsdaten die Leistungsfähigkeit von KI-Modellen beeinflusst. Die Ergebnisse deuten darauf hin, dass ein optimaler Komplexitätsgrad für die Entwicklung intelligenterer KI-Modelle existiert.
Eine neue Studie der Yale University legt nahe, dass die Komplexität der Trainingsdaten einen entscheidenden Einfluss auf die Entwicklung von Intelligenz in KI-Systemen hat. Die Forscher trainierten verschiedene Large Language Models (LLMs) mit Daten aus elementaren zellulären Automaten (ECAs) unterschiedlicher Komplexität und untersuchten anschließend deren Leistung bei Reasoning-Aufgaben und der Vorhersage von Schachzügen.
Elementare zelluläre Automaten sind eindimensionale Systeme, bei denen der Zustand jeder Zelle in der nächsten Generation von ihrem eigenen Zustand und dem ihrer beiden Nachbarn abhängt. Obwohl sie auf einfachen Regeln basieren, können ECAs ein breites Spektrum an Verhaltensweisen von trivial bis hochkomplex erzeugen.
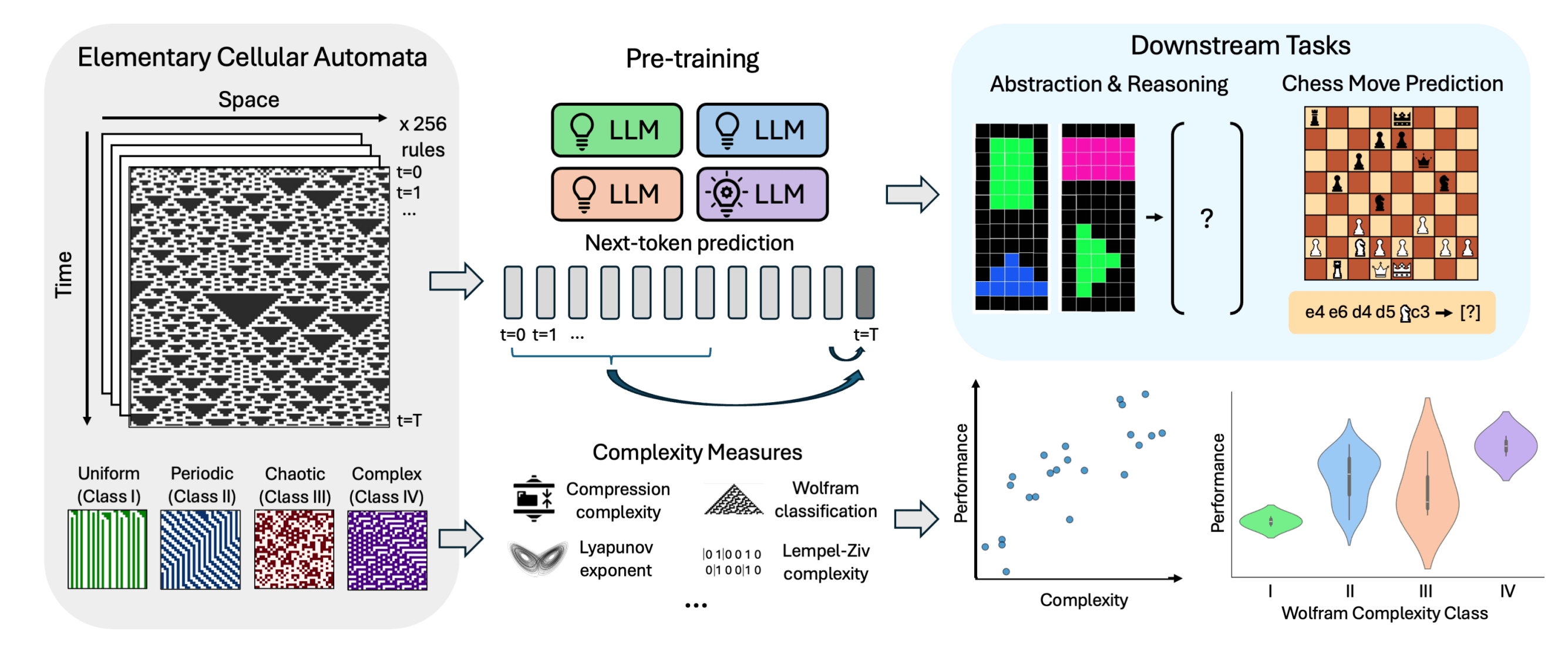
Die Studie zeigt, dass Modelle, die auf das Verhalten von komplexeren ECA-Regeln trainiert wurden, bei nachgelagerten Aufgaben besser abschneiden. Eine besonders gute Leistung zeigten Modelle, die mit ECAs der Klasse IV nach der Wolfram-Klassifikation trainiert wurden. Deren Regeln erzeugen Muster, die weder vollständig geordnet noch vollständig chaotisch sind, sondern eine Art strukturierte Komplexität aufweisen.
Am Rande des Chaos
"Überraschenderweise stellen wir fest, dass Modelle komplexe Lösungen lernen können, wenn sie mit einfachen Regeln trainiert werden. Unsere Ergebnisse deuten auf einen optimalen Komplexitätsgrad oder 'Rand des Chaos' hin, der Intelligenz fördert und bei dem das System zwar strukturiert, aber schwer vorhersagbar ist", so die Autoren.
Modelle, die mit sehr einfachen ECAs trainiert wurden, neigten dazu, triviale Lösungen zu lernen. Im Gegensatz dazu entwickelten Modelle, die mit komplexeren ECAs trainiert wurden, anspruchsvollere interne Repräsentationen, selbst wenn einfachere Lösungen möglich gewesen wären. Die Autoren vermuten, dass diese Komplexität in den gelernten Repräsentationen ein Schlüsselfaktor ist, der es den Modellen ermöglicht, ihr Wissen auf andere Aufgaben zu übertragen.
Die Studie wirft auch Licht auf die Frage, warum große Sprachmodelle wie GPT-3 oder GPT-4 so leistungsfähig sind. Die Forscher vermuten, dass die enorme Menge und Vielfalt der Trainingsdaten dieser Modelle einen ähnlichen Effekt haben könnte wie die komplexen ECA-Regeln in ihrer Studie. Sie betonen jedoch, dass weitere Untersuchungen notwendig sind, um diese Hypothese zu bestätigen, und planen, ihre Experimente auf größere Modelle und komplexere Systeme auszudehnen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.