Genmo Mochi 1: Neuer Maßstab für offene Video-KI

Das KI-Start-up Genmo hat sein Videomodell Mochi 1 als Open-Source-Version veröffentlicht. Nach Angaben des Unternehmens ist es mit 10 Milliarden Parametern das bisher größte öffentlich verfügbare KI-Modell zur Videogenerierung.
Das Modell wurde von Grund auf neu entwickelt und setzt laut Genmo vor allem bei zwei kritischen Aspekten neue Maßstäbe: der Bewegungsqualität und der Genauigkeit, mit der Textanweisungen umgesetzt werden.
Video: Genmo
Mochi 1 kann Videos mit 30 Bildern pro Sekunde und einer Länge von bis zu 5,4 Sekunden erzeugen. Dabei simuliert es laut Genmo physikalische Effekte wie Flüssigkeiten sowie Fell- und Haarbewegungen besonders realistisch.
Video: Genmo
Nach Angaben des Unternehmens ist das Modell für fotorealistische Inhalte optimiert und weniger für animierte Inhalte geeignet. Bei extremen Bewegungen kann es gelegentlich zu Verzerrungen kommen.
In der aktuellen Version produziert Mochi 1 Videos mit einer Auflösung von 480p. Eine HD-Version mit 720p-Auflösung soll noch in diesem Jahr folgen.
Neue Architektur für effiziente Videogenerierung
Technisch basiert Mochi 1 auf einer neuartigen Architektur namens "Asymmetric Diffusion Transformer" (AsymmDiT). Diese verarbeitet Text- und Videoinhalte getrennt, wobei der visuelle Teil etwa viermal so viele Parameter nutzt wie der Textverarbeitungsteil.
Im Gegensatz zu anderen modernen Diffusionsmodellen verwendet Mochi 1 nur ein einziges Sprachmodell (T5-XXL) zur Verarbeitung der Prompts. Das soll die Effizienz steigern, ein wissenschaftliches Paper mit tiefergehenden Informationen haben die Entwickler:innen allerdings noch nicht veröffentlicht.
Bei der Umsetzung von Text-Prompts erreicht das Modell in Benchmarks eine höhere Genauigkeit als die Konkurrenz, während es bei der Bewegungsqualität komplexe physikalische Effekte realistischer simulieren kann.
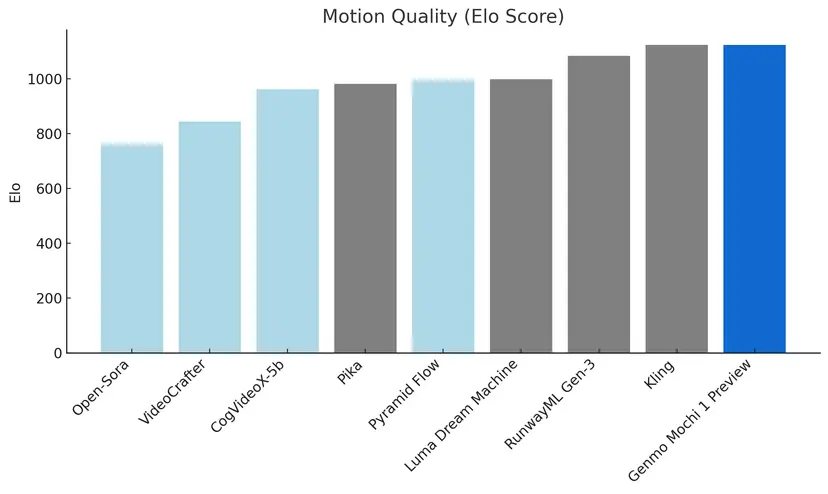
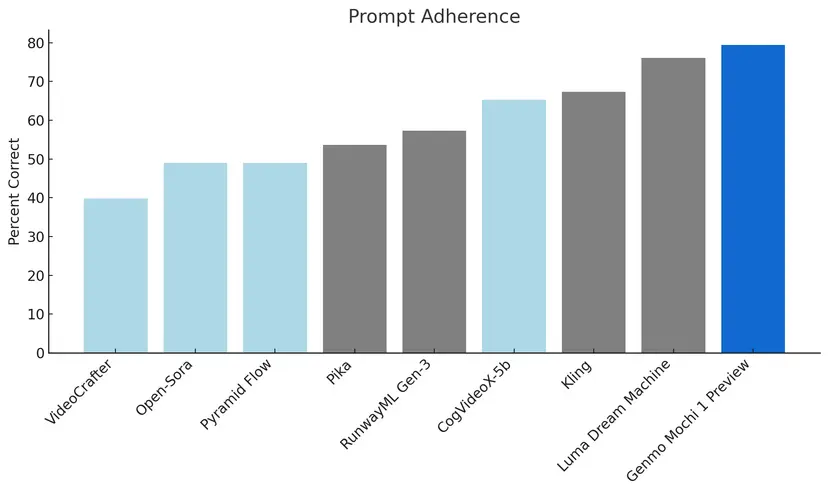
Laut Selbstbeschreibung auf der offiziellen Website fungiere Mochi 1 als Weltmodell. An einer solchen Fähigkeit von Videogeneratoren ließen kürzliche Untersuchungen zweifeln.
28,4 Millionen Dollar Finanzierung
Parallel zur Veröffentlichung des Modells gibt Genmo eine von NEA angeführte Series-A-Finanzierungsrunde über 28,4 Millionen US-Dollar bekannt. Das Team von Genmo besteht aus Kernmitgliedern wichtiger KI-Projekte wie DDPM, DreamFusion und Emu Video.
Die Gewichte und der Code des Modells stehen unter der Apache-2.0-Lizenz auf Hugging Face und GitHub zur Verfügung. Interessierte können das Modell auch kostenlos über einen rudimentären Playground auf der Genmo-Website ausprobieren, auf der auch zahlreiche Beispiele aus der Community inklusive deren Prompt angezeigt werden.
Kommerziell immer noch besser
Auch wenn die Qualität für ein offenes Videomodell durchaus zu beeindrucken weiß, haben kommerzielle Modelle wie Runway Gen-3 derzeit noch die Nase vorn. Das darauf basierende Tool kann sowohl längere als auch höher auflösende Clips produzieren und unterstützt Zusatzfunktionen wie Bildprompts, virtuelle Kameraführungen oder die Übertragung von Mimik auf einen KI-Charakter. Weitere Angebote gibt es von Kling, Vidu und MiniMax. Auch Meta hat kürzlich mit Movie Gen ein neues Videomodell vorgestellt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.