DeepThought-8B: Ruliad veröffentlicht offenes "Reasoning"-Modell

Das KI-Start-up Ruliad hat ein neues Sprachmodell namens DeepThought-8B vorgestellt, das seinen Denkprozess in strukturierter Form offenlegt. Trotz seiner geringen Größe soll es mit deutlich größeren Modellen mithalten können.
Das neue KI-Modell DeepThought-8B von Ruliad dokumentiert seine Schlussfolgerungen Schritt für Schritt in einem strukturierten JSON-Format. Laut den Entwicklern macht dies die Entscheidungsfindung des Modells transparenter und kontrollierbarer.
Wie Ruliad in einem Blogpost mitteilt, basiert DeepThought-8B auf dem Sprachmodell Llama-3.1 8B und läuft lokal auf Grafikkarten ab 16 GB Speicher. Anders als das zugrundeliegende Modell löst DeepThought-8B Probleme jedoch primär in mehreren Schritten. Das Team nennt das "Reasoning Chain" - es handelt sich im Kern um Chain-of-Thought-Abfolgen. Diese Schritte werden wie auch bei OpenAIs "Structured Outputs" in einem maschinenlesbaren JSON-Format ausgegeben.
{ "step": 1,
"type": "problem_understanding",
"thought": "The user is asking how many Rs there are in the word 'strawberry'" }
Beispiel für strukturierte DeepThought-Ausgabe
Eine Besonderheit ist die Möglichkeit in diese "Reasoning Chains" einzugreifen: Das Modell unterstützt es sogenannte "Injections" namens Scripted, Max Routing und Thought Routing. Bei Scripted lassen sich im Vorfeld konkrete Argumentationspunkte festlegen.
Demo-Video für das "Thought Routing" von DeepThought-8B. | Video: Ruliad
Max Routing erlaubt sowohl eine maximale Anzahl an Denkschritten zu wählen als auch zu bestimmen, wie DeepThought-8B die Gedankenkette abschließen soll. Über Thought Routing werden Wenn/Dann-Regeln bestimmt, die dynamisch je nach Chatverlauf zum Einsatz kommen.
Ruliad setzt auf Test-time compute
Laut Ruliad kann das Modell die Tiefe seiner Analyse an die Komplexität der Aufgabe anpassen, das sogenannte "Test-time Compute Scaling". Damit soll die Performance eines Sprachmodells durch mehr Rechenleistung während der Inferenz steigern. Auch OpenAIs o1-Modell setzt auf diesen Ansatz, unterscheidet sich jedoch mutmaßlich im Einsatz von Reinforcement Learning im Training und internen Chain-of-Thoughts von Ruliads Modell. Wie genau o1 trainiert wurde und wie es funktioniert, ist jedoch bisher nicht bekannt.
Das Unternehmen betont, dass DeepThought-8B trotz seiner vergleichsweise geringen Größe in Benchmarks für Reasoning, Mathematik und Programmierung konkurrenzfähige Ergebnisse erzielt. Über verschiedene Benchmarks hinweg liegt es etwa auf Niveau der viel größeren Qwen-2-72B und Llama-3.1-70B, jedoch unter Claude 3.5 Sonnet, GPT-4o und o1-mini.
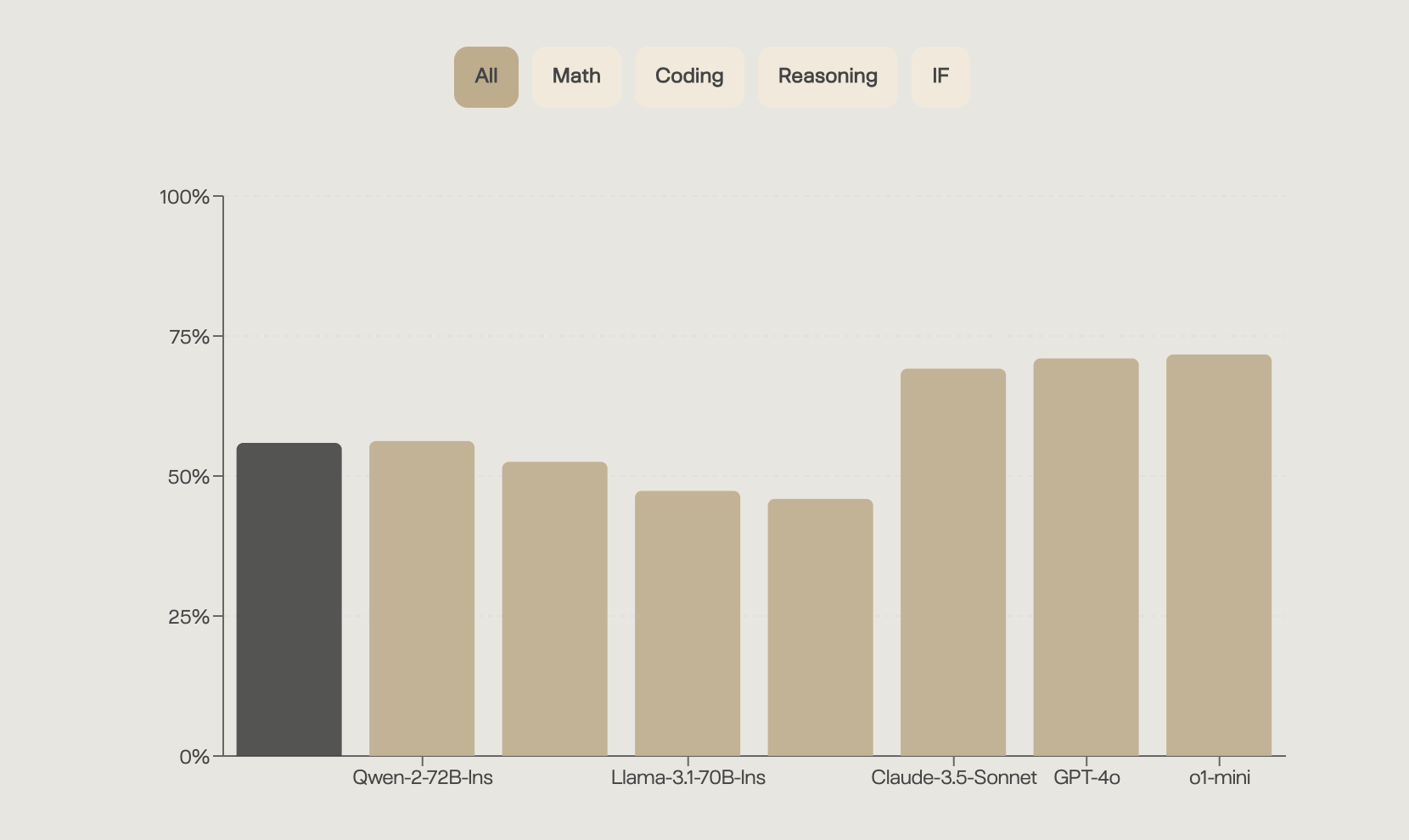
Als Einschränkungen nennt das Team komplexes mathematisches Reasoning, die Verarbeitung langer Kontexte und der Umgang mit Randfällen.
DeepThought-8B auf Hugging Face, API und Demo
Ruliad hat die Gewichte des Modells daher Open Source auf Hugging Face veröffentlicht. In den kommenden Wochen soll eine Entwickler-API folgen, die sich derzeit in geschlossener Beta-Phase befindet. Bis dahin lässt sich DeepThought-8B bereits kostenlos nach Google-Login über chat.ruliad.co ausprobieren.
In den letzten Wochen haben auch andere Unternehmen Reasoning-Modelle auf den Markt gebracht, so etwa DeepSeek-R1 und Qwen QwQ.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.