OpenAIs neues Reasoning-Modell "o3" startet ab Ende Januar 2025

OpenAI kündigt mit o3 sein bisher leistungsfähigstes KI-Modell an. Die kostengünstigere Mini-Version soll Ende Januar erscheinen, die Vollversion kurz darauf.
OpenAI hat sein neues "Reasoning"-Modell o3 vorgestellt, das in wichtigen KI-Benchmarks neue Maßstäbe setzt. Wie das kürzlich veröffentlichte Vorgängermodell o1 nimmt sich o3 mehr Zeit und Rechenleistung, um Aufgaben zu lösen. Dabei durchläuft es einen komplexen Denkprozess bis zur Antwort.
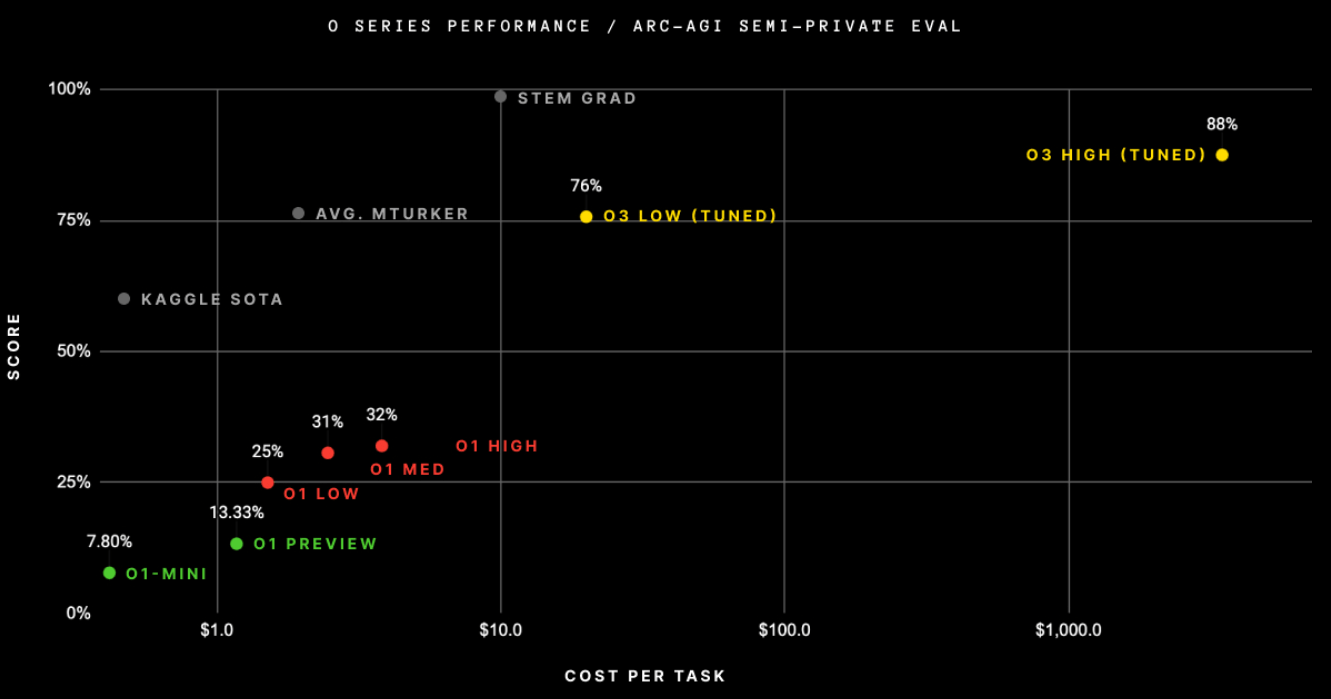
Laut OpenAI erreicht das System beim AGI-Benchmark ARC eine bisher unerreichte Leistung von 75,7 Prozent bei normaler und 87,5 Prozent bei erhöhter Rechenleistung. Der Benchmark gilt als wichtiger Gradmesser für künstliche allgemeine Intelligenz (AGI), die neue Aufgaben lösen und generalisieren kann.
Besonders beeindruckend sind die mathematischen Fähigkeiten: Bei der amerikanischen Mathematik-Olympiade AIME 2024 löste o3 96,7 Prozent der Aufgaben und verfehlte nur eine einzige Frage. Beim Frontier Math Benchmark von EpochAI, einem der schwierigsten mathematischen KI-Tests, erreichte o3 25,2 Prozent - bisherige Modelle kamen nicht über 2 Prozent hinaus. Der Test wurde erst im November vorgestellt, dessen Entwickler bezeichnet das Ergebnis als "signifikanten Sprung".
Bei Software-Aufgaben erreicht das Modell eine Genauigkeit von 71,7 Prozent, was laut OpenAI eine Verbesserung von 20 Prozent gegenüber den o1-Modellen darstellt. Im Programmierbereich übertraf o3 auf der Plattform Codeforces mit einer Wertung von 2727 sogar OpenAIs Chief Scientist (2665).
Bei PhD-Level-Wissenschaftsfragen im GPT Diamond Benchmark kommt o3 auf 87,7 Prozent - deutlich über dem Durchschnitt von PhD-Experten, die laut OpenAI in ihren jeweiligen Fachgebieten etwa 70 Prozent erreichen.
Fortschritt, aber keine AGI
François Chollet, der Entwickler des ARC-Benchmarks, bezeichnet das gute Abschneiden als einen überraschenden und wichtigen Sprung in den KI-Fähigkeiten.
Laut Chollet unterscheidet sich o3 grundlegend von bisherigen Sprachmodellen. Während diese hauptsächlich gespeicherte Muster abrufen, könne o3 zur Laufzeit neue Programme entwickeln, um unbekannte Aufgaben zu lösen.
Das System durchsuche dabei den Raum möglicher Lösungswege (Chains of Thought) womöglich ähnlich wie Google Deepminds AlphaZero beim Schachspiel. Dieser Suchprozess erklärt auch den hohen Rechenaufwand von bis zu 33 Millionen Tokens pro Aufgabe.
Entsprechend sind auch die Kosten für den Betrieb von o3 erheblich im Vergleich zu existierenden ConsumerKI-Systemen: Für die effiziente Version (High-Efficiency) fallen laut Chollet bei 100 Testaufgaben etwa 2.012 Dollar an, was 20 Dollar pro Aufgabe entspricht. Für 400 öffentliche Testaufgaben wurden 6.677 Dollar fällig - etwa 17 Dollar pro Task.
Die rechenintensive Version (Low-Efficiency) benötigt etwa 172-mal mehr Ressourcen, die genauen Kosten will OpenAI nicht veröffentlichen. Pro Aufgabe verarbeitet das System zwischen 33 und 111 Millionen Tokens und benötigt etwa 1,3 Minuten Rechenzeit.
Doch trotz der beeindruckenden Leistung betont Chollet, dass o3 noch keine künstliche allgemeine Intelligenz (AGI) darstellt. Das System scheitere weiterhin an einigen einfachen Aufgaben und zeige fundamentale Unterschiede zur menschlichen Intelligenz.
Von AGI könne erst dann gesprochen werden, wenn es nicht mehr möglich sei, Aufgaben zu entwickeln, die für Menschen einfach, für KI-Systeme aber schwierig seien. Bis dahin bleibe der ARC-Benchmark ein wichtiges Instrument, um die Grenzen heutiger KI-Systeme aufzuzeigen.
Der ARC-AGI-Benchmark sei mit dem neuen o3-System langsam gesättigt. Chollet kündigt deshalb einen Nachfolger für 2025 an: ARC-AGI-2 soll deutlich anspruchsvoller werden. Erste Tests deuten darauf hin, dass auch o3 hier nur etwa 30 Prozent erreichen wird. Kluge Menschen könnten in diesem Test ohne Training 95 Prozent der Aufgaben lösen.
Kostengünstige o3 Mini-Version startet ab Ende Januar 2025
OpenAI plant, Ende Januar 2025 zunächst eine kostengünstigere Mini-Version von o3 zu veröffentlichen. Die Vollversion von o3 soll später folgen.
Die kleinere Variante o3 mini soll laut OpenAI eine besonders kostengünstige Alternative darstellen. Das Modell bietet drei Geschwindigkeitsstufen (niedrig, mittel, hoch) und erzielt bereits in der mittleren Einstellung bessere Ergebnisse als o1 - bei deutlich geringeren Kosten und schnellerer Verarbeitung.
In einer Live-Demonstration zeigte OpenAI, wie das Modell selbstständig Code generieren und ausführen kann. So erzeugte O3 mini ein Python-Skript, das ein User Interface (UI) generierte, um sich selbst auf einem "GPQ"-Datensatz zu evaluieren.
o3 mini unterstützt auch API-Funktionen wie Funktionsaufrufe und strukturierte Ausgaben. Laut OpenAI erreicht es hier vergleichbare oder bessere Ergebnisse als O1.
Vor der Veröffentlichung startet OpenAI ein neues öffentliches Sicherheitstestprogramm. Sicherheitsforscher können sich bis zum 10. Januar für die Teilnahme bewerben. Das Unternehmen führt auch eine neue Sicherheitstechnik namens "Deliberative Alignment" ein, die die Argumentationsfähigkeiten des Modells nutzt, um bessere Sicherheitsgrenzen zu definieren.
Der Name "o3" wurde übrigens gewählt, weil OpenAI die Bezeichnung "o2" aus Rücksicht auf den Telekommunikationskonzern O2 überspringen musste.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.