Qwens QVQ-72B ist das erste Open-Source-Modell für anspruchsvolles visuelles Schlussfolgern

Alibabas KI-Forschungsteam Qwen hat mit QVQ-72B-Preview ein neues Open-Source-Sprachmodell vorgestellt, das komplexe Schlussfolgerungen aus Bildern ziehen kann. Das Modell übertrifft bisherige Ansätze deutlich, ist aber noch experimentell.
Durch schrittweises Schlussfolgern zeigt QVQ verbesserte Fähigkeiten bei Aufgaben, die visuelles Schlussfolgern erfordern, insbesondere in Bereichen, die anspruchsvolles analytisches Denken erfordern. QVQ-72B-Preview liest ein Bild und eine Anweisung, beginnt zu "denken", reflektiert, wenn nötig, fährt mit der Schlussfolgerung fort und erzeugt schließlich eine Vorhersage mit Konfidenzwert. Laut Qwen ist es das erste Open-Source-Modell seiner Art.
Qwen testete QVQ-72B-Preview in den Benchmarks MMMU, MathVista, MathVision und OlympiadBench. Die Benchmarks prüfen das Modell auf unterschiedliche Fähigkeiten: MMMU prüft visuelles Verständnis auf Uni-Niveau, MathVista testet mathematisches Denken anhand von Grafiken, MathVision nutzt Mathematik-Wettbewerbsaufgaben und OlympiadBench fordert Wissen auf Olympiade-Niveau in zwei Sprachen.
Laut Qwen übertrifft das neue Modell das Vorgängermodell Qwen2-VL-72B-Instruct in allen Benchmarks und erreicht das Leistungsniveau führender KI-Modelle wie OpenAI o1 und Claude 3.5 Sonnet.
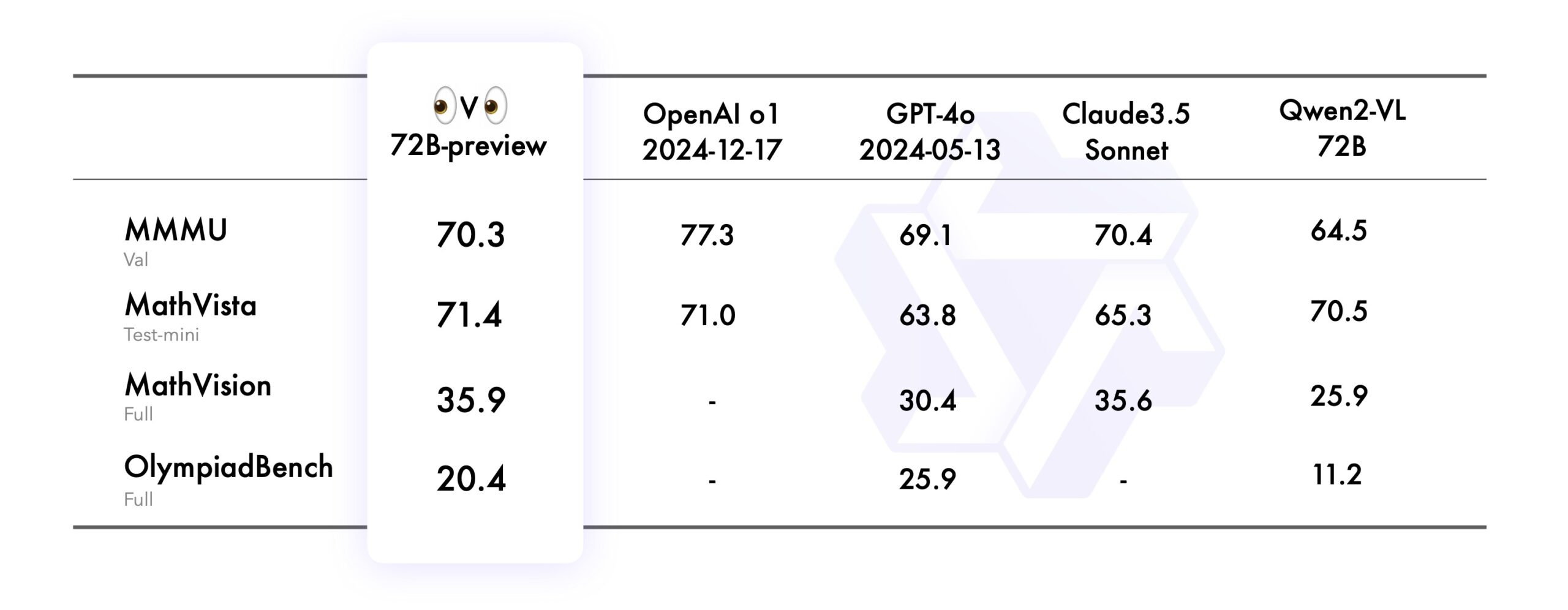
Die Tests zeigen, dass QVQ nicht nur Bilder erkennen, sondern diese auch im mathematisch-naturwissenschaftlichen Kontext verstehen und für komplexe Problemlösungen nutzen kann.
QVQ-72B-Preview basiert auf dem Vision-Language-Modell Qwen2-VL-72B, das um Fähigkeiten des Denkens und Schlussfolgerns auf der Grundlage visueller Informationen erweitert wurde. Mit dieser Reasoning-Funktion erinnert es an QwQ, das ebenfalls kürzlich von Qwen enthüllt wurde. Das Forschungsteam hat sich bisher nicht zu möglichen Verbindungen zwischen den beiden Modellen geäußert.
Vorschau-Modell hat noch Einschränkungen
Allerdings weist QVQ-72B-Preview laut Qwen noch eine Reihe von Einschränkungen auf, die bei der Verwendung beachtet werden sollten. So kann das Modell Sprachen mischen oder unerwartet zwischen ihnen wechseln.
Auch könne das Modell in zirkulären Logikmustern stecken bleiben und ausschweifende Antworten produzieren, ohne zu Schlussfolgerungen zu gelangen - Probleme, mit denen auch OpenAIs o1 zu kämpfen hat.
Darüber hinaus erfordert das Modell verbesserte Sicherheitsmaßnahmen, um eine zuverlässige und sichere Leistung zu gewährleisten, und Entwickler sollten bei der Verwendung und Bereitstellung vorsichtig sein.
Beispiel für die visuelle Lösung eines Mathematik-Problems. | Video: Qwen
Obwohl das Modell Verbesserungen beim visuellen Schlussfolgern zeigte, konnte es die Fähigkeiten von Qwen2-VL-72B-Instruct nicht vollständig ersetzen. Außerdem kann das Modell bei mehrstufigem visuellem Schlussfolgern den Fokus auf den Bildinhalt verlieren, was zu Halluzinationen führen kann.
Weitere Links zum Open-Source-Code und den Modellgewichten finden sich auf der Projektseite. Auf Hugging Face ist auch eine kostenlose Demo verfügbar.
Visual Reasoning: Teilschritt auf dem Weg zum Omni-Modell
In einem Tweet bezeichnet das Qwen-Team QVQ als "letztes Geschenk" an die Nutzer vor dem Jahreswechsel. Nach eigenen Angaben arbeitet das Team an einem "allwissenden und intelligenten Modell", um dem Ziel einer Artificial General Intelligence (AGI) näherzukommen.
Das neue Vision-Language-Modell mit erweiterten Denk- und Schlussfolgerungsfähigkeiten auf Basis visueller Informationen soll ein weiterer Schritt in diese Richtung sein.
Für die nahe Zukunft plant Qwen die Integration zusätzlicher Modalitäten in ein einheitliches "Omni"-Modell ähnlich GPT-4o von OpenAI, um das Modell insgesamt intelligenter zu machen und damit komplexeren Aufgaben und wissenschaftlichen Untersuchungen gerecht zu werden.
"Man stelle sich eine KI vor, die ein komplexes physikalisches Problem betrachten und sich mit der Sicherheit eines Meisterphysikers methodisch zur Lösung vorarbeiten kann", schreibt das Team.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.