OpenAI: In Siebenmeilenstiefeln zum effizienten KI-Training

KI-Training braucht viel Rechenleistung – oder doch nicht? OpenAI zeigt, welche großen Fortschritte KI-Training in Sachen Effizienz gemacht hat.
Der Siegeszug des Deep Learning begann 2012 mit der Bildanalyse-KI AlexNet, die den ImageNet-Wettbewerb gewann. Der “ImageNet-Durchbruch” bewies endgültig, wie vielversprechend das Deep Learning für maschinelle Lernaufgaben ist.
Ermöglicht wurde der folgende Deep-Learning-Siegeszug durch leistungsstarke Grafikkarten, die besser für das KI-Training geeignet sind als bis dato gängige Prozessoren. Es zeigte sich, was KI-Forscher Rich Sutton „die bittere Lektion“ nennt: KI-Methoden, die rein auf maschinelles Lernen und viel Rechenleistung setzen, sind den zuvor verwendeten Methoden, die aufwendig per Hand konstruierte Systeme mit menschlichem Input nutzen, haushoch überlegen.
Anders gesagt: Eine KI benötigt kein aufwendiges Einprogrammieren von Wissen und keine tiefgreifenden Einblicke in unsere eigenen mentalen Fähigkeiten. Wir müssen nur genug Daten in ein neuronales Netzwerk mit genug Rechenleistung schaufeln.
KI-Training muss günstiger werden
Die verfügbare und genutzte Rechenleistung steigt seitdem immer weiter an, da noch größere neuronale Netzwerke mit noch mehr Daten trainiert werden. Die daraus resultierenden Künstlichen Intelligenzen analysieren Bilder noch exakter oder übersetzen Sprachen auf hohem Niveau.
Gleichzeitig gibt es Bemühungen, die notwendige Rechenleistung für das KI-Training zu reduzieren. Denn die ist einerseits teuer. Andererseits sollen KIs für neue Anwendungsszenarien auch auf Hardware mit wenig Rechenleistung trainiert werden können - so wie Smartphones. Derzeit laufen dort hauptsächlich vortrainierte Modelle, was weniger flexibel ist.
OpenAI, dessen Mitgründer Ilya Sutskever auch an AlexNet arbeitete, zeigt nun, wie erfolgreich Forscher in den letzten Jahren die für das KI-Training notwendige Rechenleistung reduziert haben. Die Grundlage für diesen Fortschritt bilden effizientere Algorithmen, die schneller Lernen und mit kleineren Netzwerken auskommen.
KI-Training 2020: Viel effizienter als noch vor wenigen Jahren
Bildanalyse
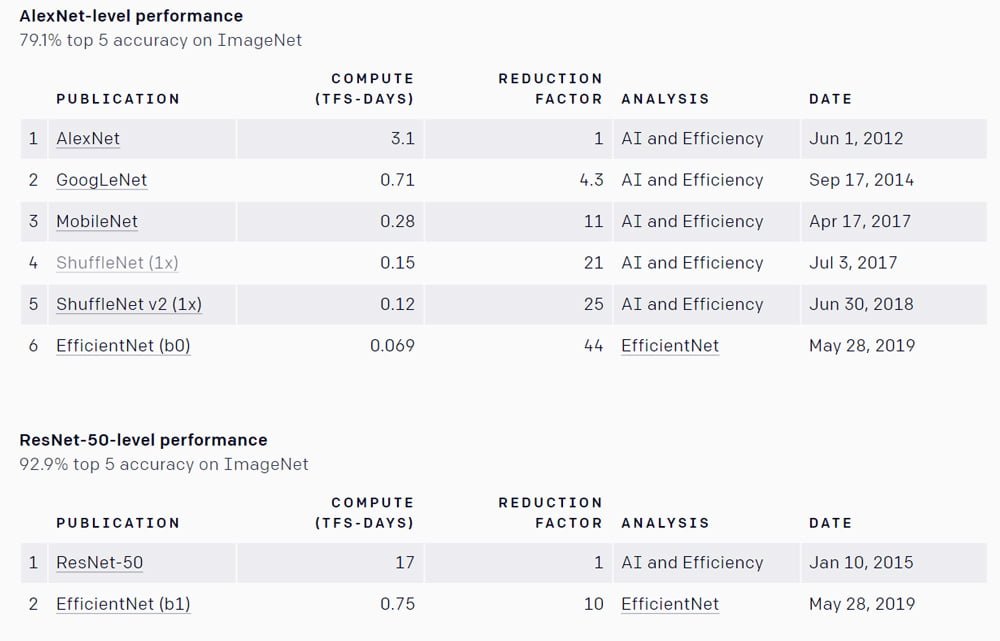
Die bei ImageNet so erfolgreiche Bildanalyse-KI „AlexNet“ erscheint Ende 2012. Sieben Jahre später hat sich die benötigte Rechenleistung für die gleiche Leistung im ImageNet-Text mit Googles Bildanalyse-KI „EfficientNet“ um den Faktor 44 reduziert.
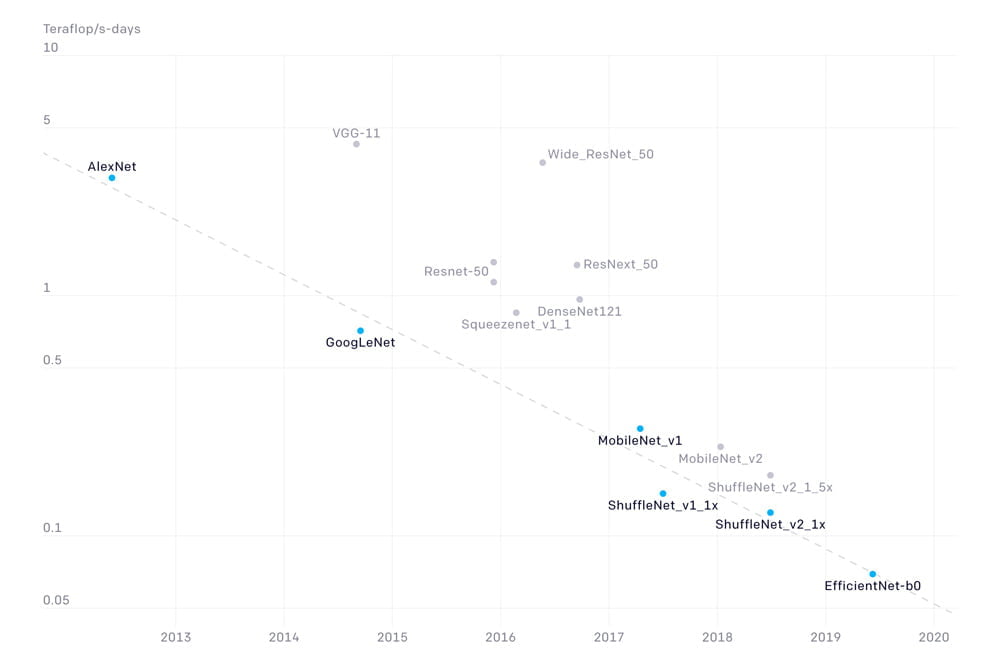
Die für den ImageNet-Test notwendige Rechenleistung habe sich alle 16 Monate um den Faktor zwei reduziert, schreibt OpenAI.
Übersetzung
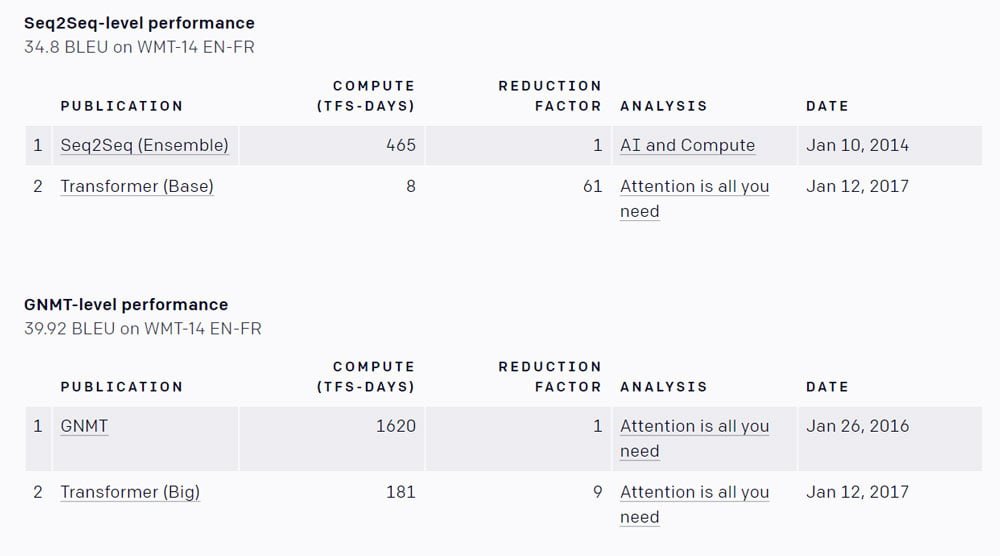
Auch bei Übersetzungs-KIs gibt es große Fortschritte in Sachen Trainingseffizienz: Die mittlerweile standardmäßig genutzte Transformerarchitektur, die die Grundlage für die Übersetzungsfunktion legt, erlaube im Vergleich zur vorher genutzten seq2seq-Architketur bessere Übersetzungen bei einer im Vergleich um den Faktor 61 reduzierten Rechenleistung. Dieser Fortschritt gelang innerhalb von nur drei Jahren.
Spieleleistung
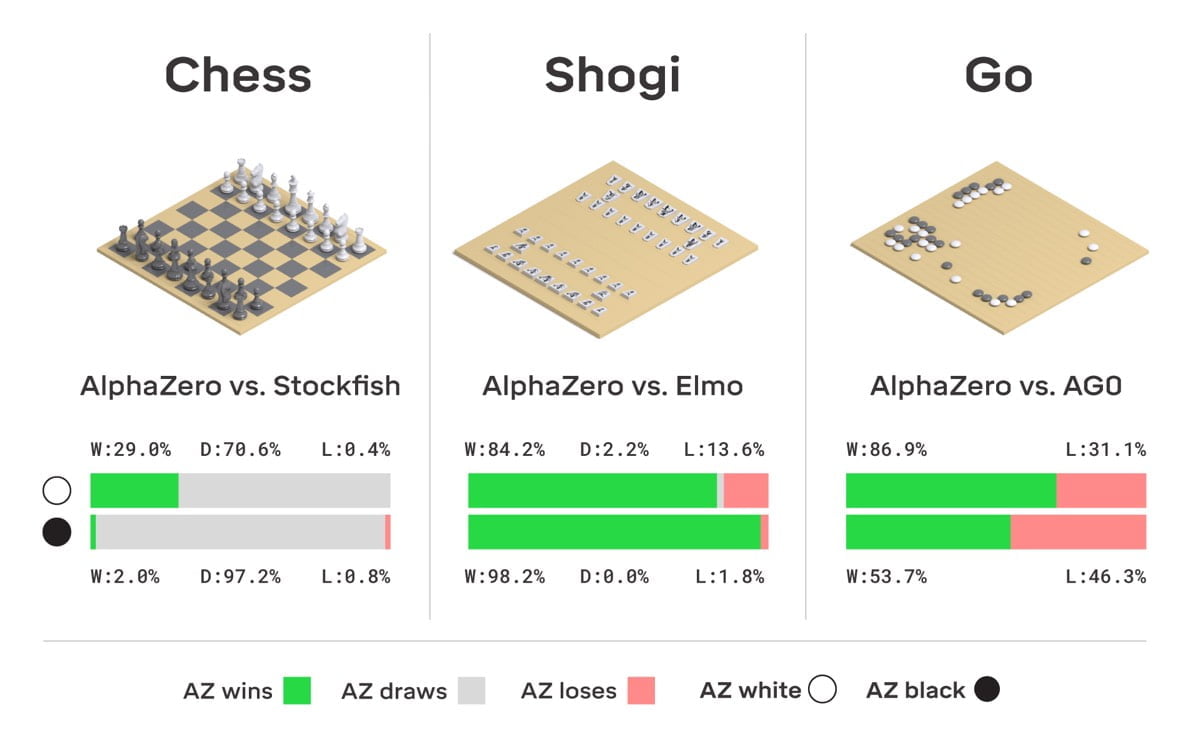
Auch die besonders aufwendig trainierten Spiele-KIs von Google und OpenAI sind effizienter geworden: Googles Brettspiel-KI AlphaZero habe achtmal weniger Rechenpower benötigt als AlphaGoZero. Die Dota-KI Open AI Five Rerun benötigte fünfmal weniger als die erste Version von Five.
Mehr als Selbstzweck
OpenAI möchte die Bestenliste der effizientesten KIs weiterpflegen mit dem Ziel, ein besseres Verständnis für Fortschritt in der KI-Forschung zu entwickeln.
Womöglich ließe sich so eine Art Gesetz finden, das eine ähnliche Vorhersagekraft für Effizienzgewinne wie das Mooresche Gesetz für das Wachstum von Rechenleistung bietet. Besonders effiziente KIs seien darüber hinaus gute Kandidaten, um durch Weiterentwicklungen noch bessere Leistung zu erzielen.
Aktuell erfasst OpenAI Effizienz-Benchmarks für Bildanalyse und Übersetzungen. In Zukunft sollen noch weitere Benchmarks hinzukommen. Die aktuelle Version der Bestenliste ist bei Github verfügbar.
Quelle: OpenAI
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.