GPT-4.5: OpenAIs "größtes Modell der Welt" ist jetzt auch für ChatGPT Plus verfügbar

Update vom 5. März 2025:
GPT-4.5 ist ab sofort für Plus-User verfügbar.
Ursprünglicher Artikel vom 28. Februar 2025:
GPT-4.5 ist da: OpenAIs "größtes Modell der Welt" überzeugt mit Vibes statt Benchmarks
OpenAI hat GPT-4.5 als "Research Preview" veröffentlicht. Das neue Sprachmodell soll natürlicher und weniger halluzinieren, ist aber deutlich teurer als seine Vorgänger.
OpenAI hat GPT-4.5 als "Research Preview" veröffentlicht - nach eigenen Angaben das "größte und beste Modell für Chat". Das neue Modell ist zunächst für ChatGPT Pro-Nutzer und -Entwickler verfügbar, Plus- und Team-Nutzer sollen nächste Woche folgen.
GPT-4.5 stellt eine Weiterentwicklung des "unüberwachten Lernens" im Gegensatz zum "Reasoning"-Ansatz der o1-Serie dar. Während Modelle wie o1 und o3-mini mittels Reasoning nachdenken, bevor sie antworten, antwortet GPT-4.5 als klassisches großes Sprachmodell direkt und erreicht seine Leistungssteigerungen durch die klassische Skalierung des Pre-Trainings.
Laut OpenAI ist GPT-4.5 (oder Orion) das bisher größte Modell der Firma und laut OpenAI-Forscher Rapha Gontijo Lopes "(wahrscheinlich) das größte Modell der Welt". Gleichzeitig betont das Unternehmen in der System Card, dass es sich bei GPT-4.5 nicht um ein "Frontier Model" handelt. Dies liegt vermutlich daran, dass das Unternehmen mit o3 ein Modell trainiert hat, das in vielen Bereichen deutlich leistungsstärker ist.
Der Preis spiegelt den Rechenaufwand wider: Mit 75 Dollar pro Million Input-Token und 150 Dollar pro Million Output-Token ist GPT-4.5 deutlich teurer als GPT-4o (2,50/10 Dollar) oder o1 (15/60 Dollar). Das Team ist sich daher noch nicht sicher, ob das Modell in dieser Form langfristig über die API angeboten wird. Wie sein Vorgänger hat es eine Kontextlänge von 128.000 Token.
OpenAI geht davon aus, dass Reasoning eine Kernfähigkeit zukünftiger Modelle sein wird und dass sich die beiden Skalierungsansätze - Pretraining und Reasoning - gegenseitig ergänzen werden. Je intelligenter und wissensintensiver Modelle wie GPT-4.5 durch Pretraining werden, desto stärkere Grundlagen bieten sie für Reasoning und Tool-basierte Agenten. Altman hat bereits vor einigen Wochen angekündigt, dass GPT-5 diese beiden Fähigkeiten vereinen wird.
GPT-4.5 zeigt gemischte Leistung
In den Benchmark-Tests zeigt GPT-4.5 zum Teil deutliche Verbesserungen: Im SimpleQA-Test erreicht es eine Genauigkeit von 62,5 % gegenüber 38,2 % bei GPT-4o oder 43,6 % beim jüngst veröffentlichten Grok 3.
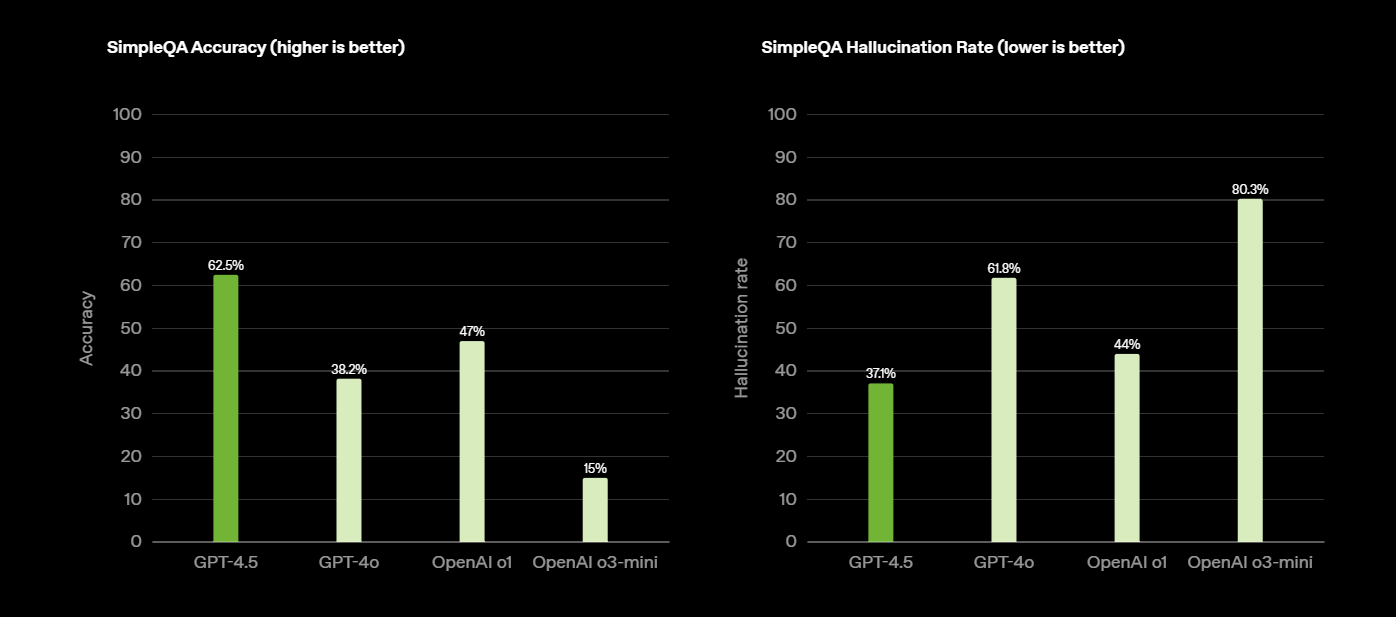
Die Halluzinationsrate sinkt von 61,8 % auf 37,1 %. Damit übertrifft es auch o1 und o3-mini. Bei MMMLU (multilingual) und MMMU (multimodal) übertrifft es mit 85,1 % bzw. 74,4 % seine Vorgänger GPT-4o (81,5 % bzw. 69,1 %) und o3-mini (81,1 % bzw. NN).
In menschlichen Bewertungstests bevorzugten die Tester den GPT-4.5 gegenüber dem GPT-4o in allen Kategorien: kreative Intelligenz (56,8 %), berufliche Fragen (63,2 %) und Alltagsfragen (57,0 %).
In STEM-Benchmarks hingegen kann es Reasoning-Modelle wie o3-mini nicht schlagen: Bei GPQA (Naturwissenschaften) erreicht es 71,4 % gegenüber 53,6 % bei GPT-4o, bleibt aber hinter OpenAI o3-mini (79,7 %) zurück. Bei AIME '24 (Mathematik) erreicht GPT-4.5 mit 36,7 % eine deutliche Verbesserung gegenüber GPT-4o (9,3 %), kommt aber nicht an o3-mini (87,3 %) heran. Bei Codierungsaufgaben schneidet GPT-4.5 im SWE-Lancer Diamond Test mit 32,6 % besser ab als GPT-4o (23,3 %) und übertrifft o3-mini (10,8 %) - allerdings bei deutlich höheren Kosten. Im SWE-Bench Verified Test erreicht es 38,0 % gegenüber 30,7 % für GPT-4o, bleibt aber hinter o3-mini (61,0 %) zurück.
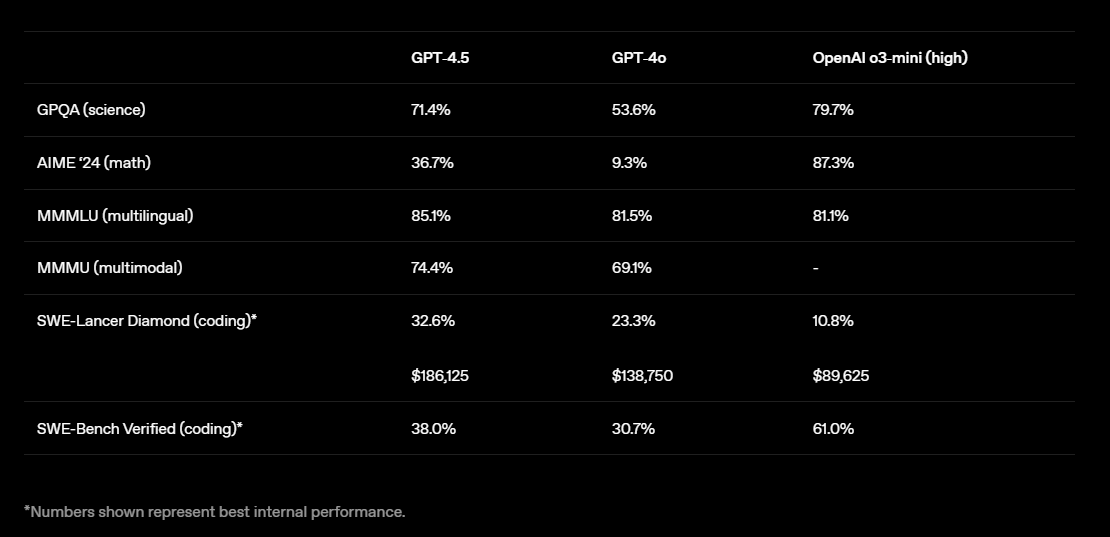
Das kürzlich veröffentlichte Claude 3.7 Sonnet erreicht in diesem Test 62,3 % bzw. 70,3 % in den von Anthropic veröffentlichten Benchmarks. Diese Werte sind jedoch nicht direkt vergleichbar, da teilweise andere Methoden und Problemstellungen verwendet bzw. getestet wurden. Case in Point: In der Systemkarte von o3-mini erreichte das Modell noch 49,3 %.
Im unabhängigen Aider Polyglot Coding Benchmark erreicht GPT-4.5 mit 45 % deutlich mehr als GPT-4o mit 23 %, liegt aber hinter anderen Modellen. Sonnet 3.7 erreicht ohne "Thinking" 60 %.
Kurzum: Es gibt keinen wahnsinnigen Leistungssprung, der sich in Benchmarks widerspiegelt - die besten Ergebnisse finden sich wahrscheinlich im SimpleQA-Test. In den nächsten Tagen wird daher viel darüber diskutiert werden, ob Scaling tot ist, ob Deep Learning vor die Wand fährt und wann Reasoning das gleiche Schicksal ereilen wird.
GPT-4.5: Vibes und diffuse Verbesserungen
OpenAI-CEO Sam Altman, kürzlich Vater geworden, war bei der Präsentation von GPT-4.5 nicht anwesend, äußerte sich aber auf X: "Es ist das erste Modell, das sich für mich wie ein Gespräch mit einer nachdenklichen Person anfühlt. Ich hatte mehrere Momente, in denen ich mich erstaunt zurücklehnte, weil ich tatsächlich gute Ratschläge von einer KI erhielt".
Altman betont, dass GPT-4.5 kein Reasoning-Modell ist und keine Benchmark-Rekorde brechen wird: "Es ist eine andere Art von Intelligenz, und sie hat eine Magie, die ich noch nie zuvor gespürt habe." Eher Vibes als Benchmarks also.
Ähnlich sieht es Gründungsmitglied und Ex-Mitarbeiter Andrej Karpathy, der zwar Fortschritte sieht, diese aber nur schwer messen kann. In seinem Kommentar zur Veröffentlichung erklärt er, dass jeder 0,5-Schritt in der Versionsnummer etwa eine Verzehnfachung der Trainingsrechenleistung bedeute.
Karpathy beschreibt die Evolution der GPT-Modelle: Von GPT-1, das kaum kohärenten Text erzeugte, über GPT-2 als "verwirrendes Spielzeug" bis hin zu GPT-3, das deutlich interessantere Ergebnisse lieferte. GPT-3.5 überschritt dann die Schwelle zur Marktreife und löste den "ChatGPT-Moment" von OpenAI aus.
Bei GPT-4 waren die Verbesserungen laut Karpathy schon subtiler. "Alles war einfach ein bisschen besser, aber auf eine diffuse Art und Weise", schreibt er. Die Wortwahl sei etwas kreativer gewesen, das Verständnis für Nuancen im Prompt habe sich verbessert, Analogien hätten etwas mehr Sinn ergeben, das Modell sei etwas witziger gewesen und Halluzinationen seien etwas seltener aufgetreten.
Mit ähnlichen Erwartungen testete er GPT-4.5, das mit der zehnfachen Trainingsrechenleistung von GPT-4 entwickelt wurde. Sein Fazit: "Ich bin wieder beim gleichen Hackathon wie vor zwei Jahren. Alles ist ein bisschen besser und das ist großartig, aber nicht unbedingt auf eine Art und Weise, die man leicht benennen kann".
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.