Wie ein zappelnder Torwart eine KI-Schwachstelle offenbart
Eine KI bewegt sich hölzern über den virtuellen Rasen und versenkt den Ball im Tor. Beim zweiten Versuch hält der KI-Torwart den Ball. Soweit so gut – alles nimmt seinen Lauf.
Plötzlich lässt sich der KI-Torwart fallen, zappelnd liegt er auf dem Boden. Der Feldspieler stolpert verwirrt zu Seite, winkt wild mit einem Arm, verfehlt den Ball und stürzt – Torversuch vereitelt, der Torwart hat gewonnen.
Diese seltsame Szene spielt sich in einer KI-Simulation von Forschern der Universität Kalifornien, Berkeley ab. Der KI-Forscher Adam Gleave und sein Team erforschen dort die Schwachstellen moderner KI-Systeme (Adversarial Learning - KI-Glossar).
Gerade Bildanaylse-KIs können mit einfachsten Tricks hinters Licht geführt werden: Eine Schildkröte sieht für die KI aus wie ein Gewehr, weil sie ein für das menschliche Auge fast unsichtbares Muster im Panzer trägt. Ein T-Shirt schützt mit einem gezielt gedruckten Muster auf der Brust vor Gesichtserkennung. Ein autonomes Auto scannt beiläufig einen unscheinbaren Sticker auf einem Stoppschild - und rast plötzlich los. Diese grundlegenden Schwachstellen in mit überwachtem Lernen (KI-Glossar) trainierten KI-Systemen sind bekannt.
Erfolg durch Ablenkung
Gleave und sein Team zeigen nun, dass auch mit bestärkendem Lernen trainierte KI-Systeme solche gezielt angreifbaren Schwachstellen haben.
Für ihr Experiment brachten die Forscher KI-Figuren bei, eine Reihe von einfachen Spielen zu meistern, darunter, einen Ball ins Tor zu schießen, über eine Linie zu rennen oder Sumoringen. Die KI-Figuren lernten dafür unter anderem, die Position und Bewegung der gegnerischen Gliedmaßen zu erkennen.
Etwas hölzern, aber erfolgreich: Die erste Gruppe spielt Fußball.
Anschließend trainierten sie eine zweite Gruppe KI-Figuren, die Schwächen der ersten Gruppe zu entdecken. Die Erfolge der zweiten Gruppe ließen nicht lange auf sich warten: Schon nach drei Prozent der Trainingszeit, die die erste Gruppe benötigte, um das Spiel zu lernen, konnte die zweite Gruppe ihre Gegner zuverlässig schlagen.
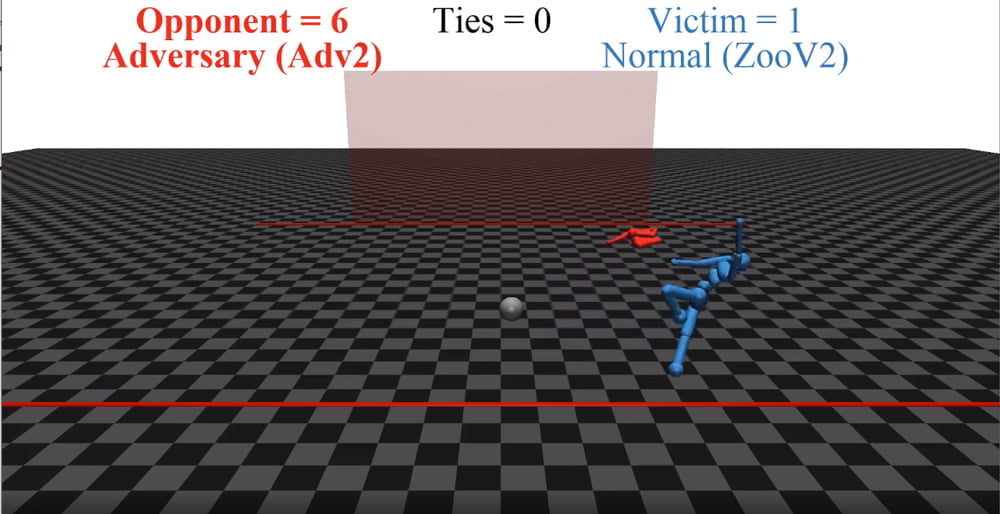
Die Torhüter der zweiten Gruppe müssen den Ball nicht halten - sie schalten ihre Gegner vor dem Schuss aus, indem sie sich auf den Boden fallen lassen.
Doch die Gewinner-KI-Teams waren keine besseren Fußballer, geschicktere Sprinter oder begabtere Sumoringer. Stattdessen nutzten sie eine Schwachstelle der ersten Gruppe aus: Die KI-Figuren orientierten sich so stark an den Bewegungen ihrer Gegner, dass sie durch bestimmte eigene Bewegungen ihre Gegner komplett ausschalteten. Im Fußball- und Laufspiel stehen die gegnerischen KI-Figuren nicht mehr auf, sondern sie stürzen in einem Haufen Gliedmaßen zusammen oder laufen im Kreis.
Die Figuren müssen beim KI-Sumo ihren Gegner zu Boden bringen oder von der Plattform schieben.
Wie beim Fußball nutzt die zweite Gruppe die Ablenkungstaktik durch seltsame Bewegungen erfolgreich aus.
Angriff auf das zentrale System
Solche Schwachstellen sind ein großes Problem, denn bestärkendes Lernen (KI-Glossar) gilt neben dem unüberwachten Lernen als die Zukunft Künstlicher Intelligenz. Einige der großen KI-Durchbrüche wie Deepminds Brettspiel-KIs Alpha und MuZero oder OpenAIs jonglierende Roboterhand Dactyl basieren auf der Lernmethode. Forscher erhoffen sich vom bestärkenden Lernen Durchbrüche im autonomen Fahren und der Robotik.
Durch Gleaves Arbeit ist nun klar, dass auch das bestärkende Lernen angreifbar ist. Die Folgen könnten fatal sein, denn die Lernmethode bildet die gesamte Verhaltensweise einer KI aus und nicht nur die Fähigkeit, beispielsweise ein einzelnes Objekt zu erkennen. Gezielte Angriffe auf die Verhaltensweise könnten andere Sicherheitsnetze überspringen.
Ein Beispiel: Die KI-Kamera eines autonomen Autos registriert den Vollgas-Sticker, doch GPS-Datenbank und Radar widersprechen der Eingabe. Der Widerspruch wird registriert und löst entsprechende Sicherheitsvorkehrungen aus. Ein Angreifer müsste daher alle Sensoren gleichzeitig täuschen, um Schaden anzurichten.
Doch die Sabotage des durch bestärkendes Lernen trainierten Kontrollsystems überspringt dieses Sicherheitsnetz: Der Angreifer attackiert nicht ein einzelnes Erkennungssystem, sondern direkt die zentrale Steuerung. So könnte im Extremfall ein autonomes Auto durch bestimmte Bewegungen eines Fußgängers von der Straße abgebracht werden.
Forscher fordern vielfältigere Tests für mehr KI-Sicherheit
Gleave fordert daher umfassendere Tests für KIs, die mit bestärkendem Lernen trainiert wurden. Beim überwachten Lernen ist es üblich, die trainierte KI mit anderen Datensätzen zu testen, um sicherzustellen, dass sie sich zum Beispiel nicht einfach nur eine Reihe von Fotos gemerkt hat, sondern auch auf unbekannten Fotos zuverlässig Gegenstände erkennt.
Beim überwachten Lernen werden KIs aber häufig in der gleichen Umgebung trainiert und getestet. Sobald sie dann mit einer unbekannten Umgebung konfrontiert werden, können sie versagen.
Ein Umstand, den etwa OpenAI mit KI-Training in prozedural generierten Spielewelten ändern möchte. Nur so kann sichergestellt werden, dass die KI auch mit neuen Situationen klarkommt – und sich nicht so leicht austricksen lässt.
Dass dieses erweiterte KI-Training Schwachstellen von KIs beheben kann, beweisen die Forscher um Gleave in ihrem Experiment: Die KI-Figuren der ersten Gruppe konnten nach zusätzlichem Training besser mit den Tricks der zweiten Gruppe umgehen.
Die zweite Gruppe brachte dann die KI-Figuren der ersten Gruppe mit vollem Körperkontakt zum Stolpern, anstatt sie durch absurde Bewegungen abzulenken - so wie es eigentlich vorgesehen war. Das zeigt, dass die KI ihre Strategie umstellen musste und keinen Fehler im System ausnutzen konnte.
Quellen: Arxiv, Gleave (GitHub)
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.