GPT-oss: OpenAI veröffentlicht erste Open-Source-Modelle seit GPT-2

Mit gpt-oss-120b und gpt-oss-20b bringt OpenAI erstmals seit GPT-2 wieder große Sprachmodelle mit offenen Gewichten auf den Markt. Es handelt sich um spezialisierte Reasoning-Modelle, deren Leistung in Benchmarks an die von o4-mini heranreicht. Ein neues Sicherheitsprotokoll soll dabei Missbrauch verhindern.
Erstmals seit GPT-2 veröffentlicht OpenAI mit gpt-oss-120b und gpt-oss-20b wieder zwei große Sprachmodelle mit offenen Gewichten, die unter der Apache-2.0-Lizenz verfügbar sind. Laut der begleitenden Model Card handelt es sich dabei explizit um Reasoning-Modelle mit Mixture-of-Experts-Architektur. Sie wurden speziell für komplexe logische Schlussfolgerungen, schrittweises Denken (Chain-of-Thought) und die Nutzung von externen Werkzeugen wie Websuche oder Code-Interpretern entwickelt.
Das größere Modell, gpt-oss-120b, soll auf einer einzelnen 80-GB-GPU betrieben werden können, während das kleinere gpt-oss-20b für Systeme mit 16 GB Arbeitsspeicher konzipiert ist. OpenAI-CEO Sam Altman bezeichnete die Veröffentlichung als Beitrag zu einer "demokratischen" KI-Infrastruktur. Beide Modelle sind über Hugging Face zugänglich.
Starke Leistung bei Logik, Code und Gesundheit
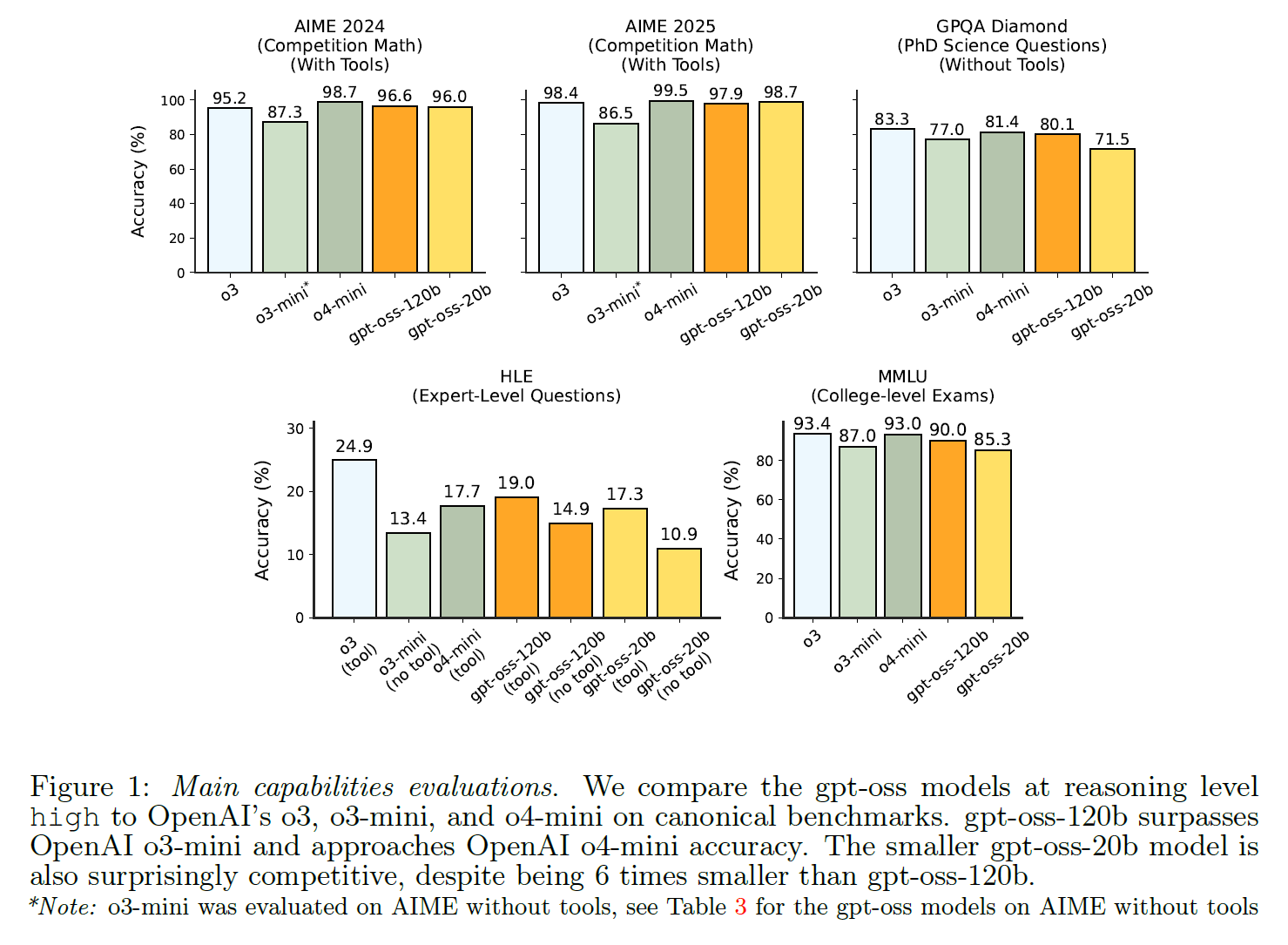
Laut OpenAI erreicht gpt-oss-120b in mehreren anspruchsvollen Benchmarks eine Leistung, die an das proprietäre Modell o4-mini heranreicht und damit in vielen Anwendungen GPT-4o deutlich übertrifft. Besonders stark sollen die Modelle bei Aufgaben sein, die lange Denkketten erfordern. Im Mathematik-Wettbewerb AIME 2024 erreicht gpt-oss-120b mit Werkzeugen eine Genauigkeit von 96,6 % und liegt damit nur knapp hinter o4-mini (98,7 %).
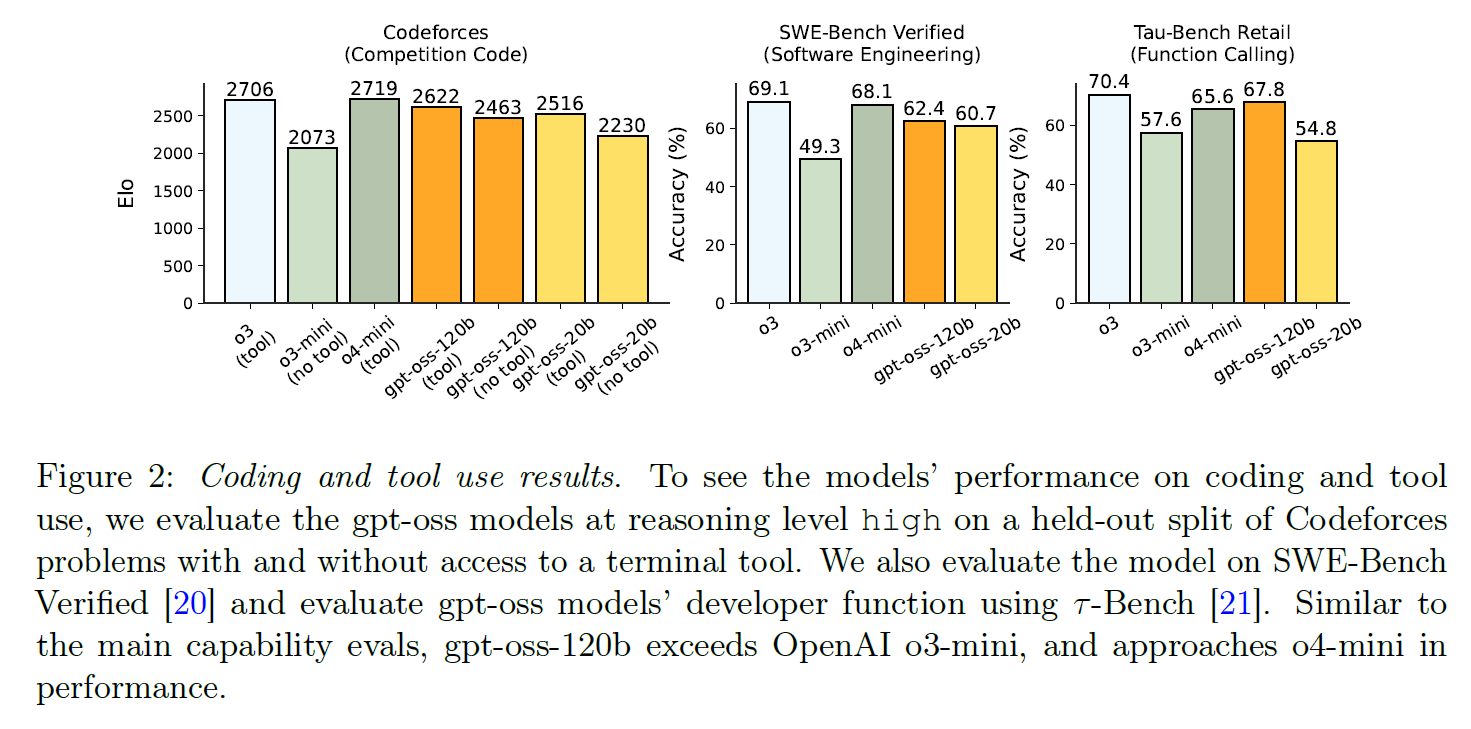
Auch bei Programmieraufgaben zeigt sich eine hohe Leistungsfähigkeit. Im Codeforces-Benchmark erzielt das Modell eine Elo-Wertung von 2622, was sich der von o4-mini (2719) annähert, in SWE-bench Verified erreichen die Modelle Werte von 60 bzw. 62 Prozent (o4-mini 69 %, o3 68 %).
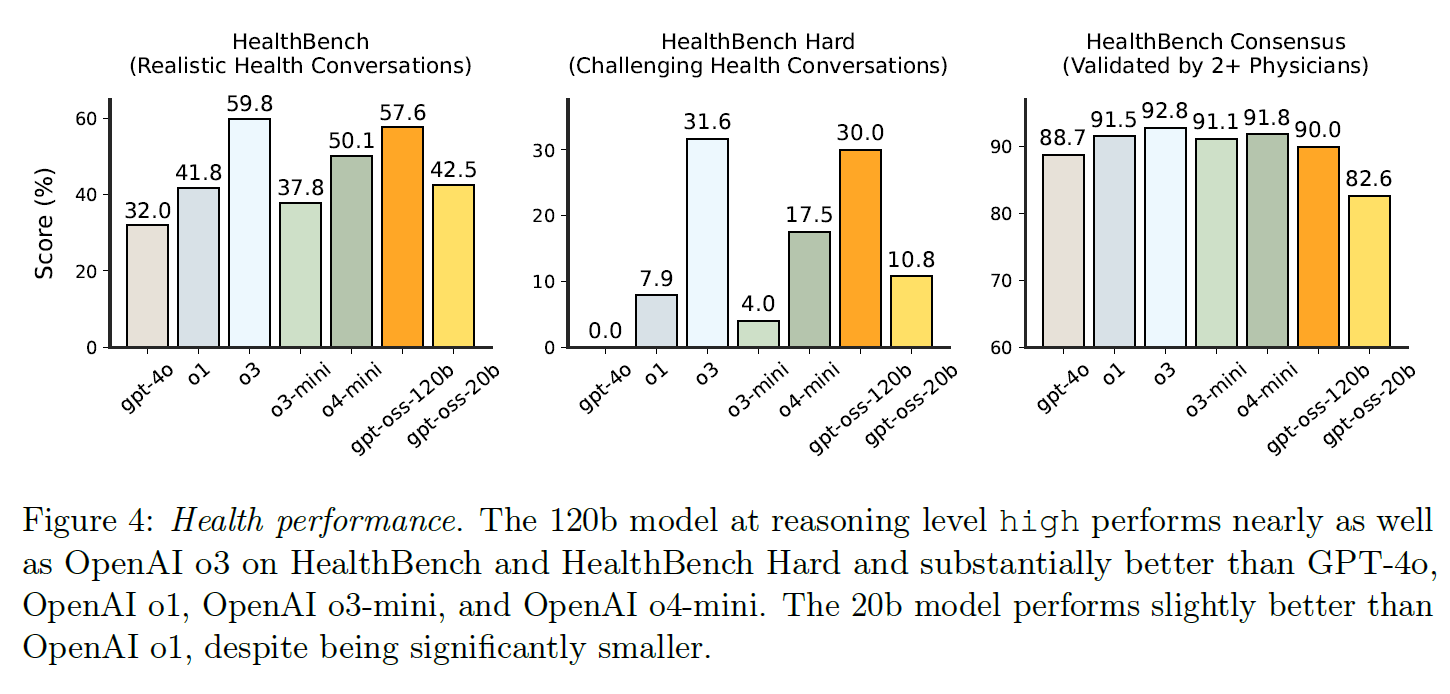
Im Gesundheitsbereich übertrifft gpt-oss-120b auf dem HealthBench-Benchmark laut OpenAI viele Modelle deutlich und liegt fast auf dem Niveau von o3.
Wichtig ist jedoch, dass es sich um reine Textmodelle ("text-only models") handelt. Sie können keine Bilder verarbeiten oder generieren. Ihr Wissensstand ist auf Juni 2024 datiert.
Defizite haben die Modelle bei der Fakten-Treue: Die gpt-oss-Modelle neigen laut dem Bericht stärker zu Halluzinationen. Laut OpenAI ist das zu erwarten: Sie sind kleinere Modelle mit weniger Weltwissen.
Ein neues Sicherheitsprotokoll für Open-Source-KI
Da Open-Source-Modelle von Angreifern für schädliche Zwecke modifiziert werden könnten, führt OpenAI ein neues Sicherheitsprotokoll ein. Kernstück ist ein "Worst-Case-Fine-Tuning"-Verfahren, bei dem OpenAI gezielt versuchte, das Modell auf gefährliche Fähigkeiten zu trainieren, etwa für die Planung von Cyberangriffen oder die Nutzung von biologischem Wissen.
Laut dem Sicherheitspapier erreichte das Modell selbst nach diesem Prozess keine "hohe" Fähigkeitsschwelle in den überwachten Risikokategorien. Dieses Ergebnis wurde von der internen Safety Advisory Group (SAG) und externen Fachleuten überprüft. OpenAI kommt zu dem Schluss, dass die Veröffentlichung die Grenze gefährlicher Fähigkeiten bei Open-Source-Modellen nicht wesentlich verschiebt, da andere Modelle wie Qwen 3 Thinking oder Kimi K2 bereits eine vergleichbare Leistung aufweisen sollen.
Trotz der Sicherheitsvorkehrungen weist die Model Card auf verbleibende Herausforderungen hin. So schneiden die gpt-oss-Modelle bei der Einhaltung der Anweisungshierarchie schlechter ab als o4-mini. Zudem wurden die Denkketten der Modelle bewusst nicht auf "schlechte Gedanken" hin optimiert, um deren Überwachung durch Entwickler zu ermöglichen, weshalb sie unmoderierte Inhalte enthalten können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.