Microsoft VibeVoice generiert in einem Rutsch 90-Minuten-Podcasts mit 4 Sprechern

Microsofts neues VibeVoice-System soll bis zu 90 Minuten lange Gespräche mit vier Sprecher:innen synthetisieren können. Ein neuartiger Speech Tokenizer macht die Langform-Generierung erst möglich.
Bisher scheiterten KI-Systeme zur Sprachgenerierung meist schon nach wenigen Minuten oder bei mehr als zwei Gesprächspartnern. Microsoft Research hat mit VibeVoice diese Limitationen überwunden und kann laut des technischen Berichts erstmals anderthalb Stunden lange Gespräche mit bis zu vier verschiedenen Sprechern erzeugen, komplett in einem Durchgang ohne Unterbrechungen.
Die Innovation liegt in einer neuen Methode zur Audiokompression. Die Microsoft-Forschenden entwickelten einen neuen Speech Tokenizer, der 80-mal effizienter sei als bisherige Verfahren und es erst ermögliche, sehr lange Gespräche im Arbeitsspeicher zu halten und zu generieren.
Gesang, Emotionen und Sprachenwechsel
Microsoft zeigt verschiedene Einsatzszenarien in den Demonstrationen: Das System kann Emotionen in Gespräche einbauen, spontan in Gesang übergehen oder komplette Podcasts erstellen.
In den Demos wurden diese teilweise mit Hintergrundmusik unterlegt, das Modell konzentriert sich laut Paper jedoch ausschließlich auf die Sprachsynthese und verarbeitet keine Hintergrundgeräusche, Musik oder andere Soundeffekte. VibeVoice funktioniert derzeit nur mit englischen und chinesischen Texten, zeigt hier aber spannende sprachübergreifende Anwendungen.
Gesang:
Emotionen:
Mandarin zu Englisch:
Ein Beispiel für lange Konversationen ist ein 93-minütiges Gespräch über Klimawandel mit vier verschiedenen Sprecher:innen, das natürliche Diskussionsdynamiken, Meinungsverschiedenheiten und emotionale Reaktionen enthält. Das System erzeugt dabei realistische Gesprächspausen, flüssige Übergänge zwischen Sprecher:innen und kontextabhängige Betonungen.
Zwei spezialisierte Systeme arbeiten zusammen
VibeVoice teilt die Audioverarbeitung in zwei Bereiche auf: Ein System kümmert sich ausschließlich um Klangqualität und Stimmcharakteristika, das andere versteht Inhalt und Bedeutung der Gespräche. Diese Trennung soll laut den Microsoft-Forschenden sowohl die Audioqualität als auch das Sprachverständnis verbessern.
Als Basis nutzt das System das vortrainierte Sprachmodell Qwen2.5 mit wahlweise 1,5 oder 7 Milliarden Parametern. Dieses versteht komplexe Gesprächssituationen und steuert den Dialogfluss. Zusätzlich kommt ein spezieller Diffusion Head mit 4 Schichten und etwa 123 Millionen Parametern zum Einsatz, der die eigentliche Audiogenerierung übernimmt.
Die beiden Tokenizer arbeiten parallel: Der Acoustic Tokenizer basiert auf einer Variational Autoencoder-Architektur mit je etwa 340 Millionen Parametern für Encoder und Decoder. Er reduziert 24-kHz-Audio um das 3.200-Fache auf 7,5 Frames pro Sekunde. Der Semantic Tokenizer nutzt eine ähnliche Architektur, wurde aber speziell für Spracherkennung trainiert, um den Inhalt zu verstehen.
Nutzer:innen können Textskripte und Stimmproben eingeben, um verschiedene Sprecher:innen zu definieren. Das System generiert dann schrittweise die komplette Audioausgabe und berücksichtigt dabei Kontext, natürliche Sprecher:innenwechsel und realistische Gesprächspausen. Das größere Modell mit 7 Milliarden Parametern erzeugt dabei natürlichere und ausdrucksstärkere Sprache als die kleinere Variante, benötigt aber auch mehr Rechenleistung.
Laut Microsoft ist VibeVoice explizit nicht für Echtzeit-Anwendungen wie Live-Übersetzungen in Telefonkonferenzen gedacht. Wie lange die Synthese einer Audiodatei im Schnitt dauert und welche Hardware dafür benötigt wird, verraten die Forschenden nicht.
Angeblich bessere Ergebnisse als Gemini und Elevenlabs
In Vergleichstests mit 24 menschlichen Bewerter:innen übertraf VibeVoice etablierte Systeme wie Googles Gemini 2.5 Pro und Elevenlabs V3. Die Testenden bewerteten Natürlichkeit, Realismus und Ausdrucksstärke der generierten Sprache. Das 7-Milliarden-Parameter-Modell erreichte dabei in allen Kategorien die höchsten Werte.
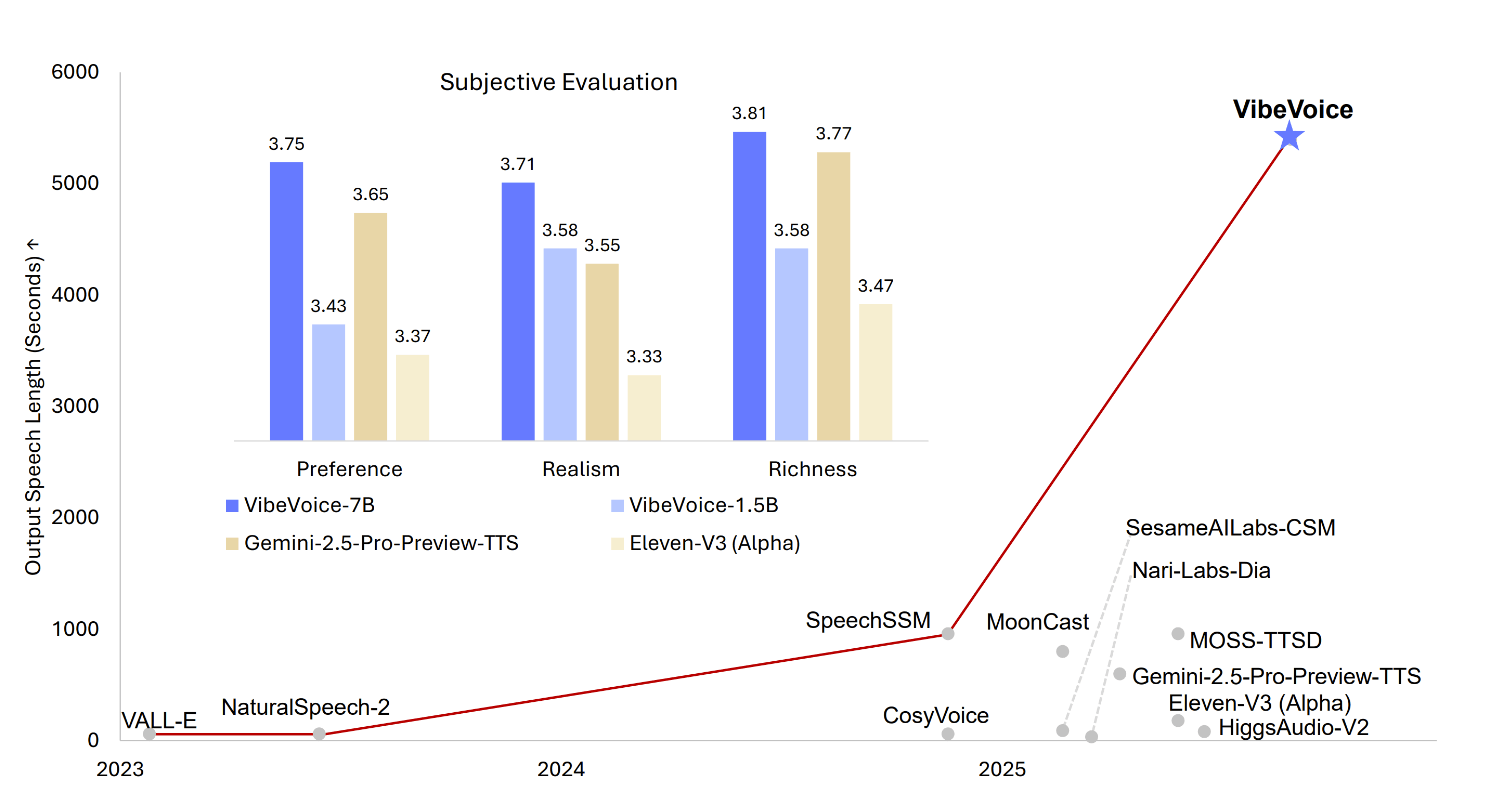
Auch automatische Tests zur Sprachqualität bestätigten die Überlegenheit: Die Fehlerrate bei der automatischen Transkription der VibeVoice-Ausgaben lag mit 1,29 Prozent mit Abstand unter der Konkurrenz. Zum Vergleich: Googles System erreichte 1,73 Prozent, Elevenlabs 2,39 Prozent.
Die Forschenden testeten das System mit acht verschiedenen langen Gesprächstranskripten mit einer Gesamtdauer von etwa einer Stunde. VibeVoice konnte dabei durchgehend natürliche Gespräche ohne Qualitätsverlust oder Unterbrechungen erzeugen.
Hörbares KI-Wasserzeichen
Microsoft adressiert die erheblichen Missbrauchsrisiken von VibeVoice und warnt davor, die hohe Qualität der synthetischen Sprache für Deepfakes, Identitätsbetrug oder gezielte Desinformation zu verwenden.
Um diesen Gefahren entgegenzuwirken, wurden konkrete Schutzmaßnahmen implementiert: Jede erzeugte Audiodatei enthält sowohl einen automatisch eingefügten, hörbaren Hinweis auf ihren KI-Ursprung als auch ein unsichtbares digitales Wasserzeichen, das die Nachverfolgung ermöglicht. Aufgrund dieser Risiken ist das Modell laut Microsoft explizit nur für Forschungszwecke und nicht für den kommerziellen oder realen Einsatz vorgesehen.
Das System ist als Open-Source-Projekt verfügbar und die Gewichte sind über Hugging Face zugänglich.
Schon im März 2024 legte Microsoft mit NaturalSpeech 3 den Grundstein für nuancierte Sprachklone, die Inhalt, Prosodie und Klangfarbe getrennt steuern können. Inzwischen zieht OpenAI nach: Ein Juni-Update machte ChatGPTs Advanced Voice Mode laut OpenAI „flüssiger, emotional nuancierter“ und ergänzt eine fortlaufende Mehrsprachen-Übersetzung.
Parallel zur Microsoft-Entwicklung hat das Start-up Resemble AI mit dem quelloffenen Modell Chatterbox gezeigt, dass sich ausdrucksstarke Stimmen inzwischen lokal und nahezu in Echtzeit mit nur 5 bis 6 GB VRAM erzeugen lassen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.