Apple hat ein Bildmodell, das OpenAI und Google nacheifert
Mit einem neuartigen Hybrid-Ansatz will Apple den Konflikt zwischen Bildverständnis und Bilderzeugung lösen. Das Manzano-Modell zeigt laut den Forschenden minimale Leistungseinbußen bei der Vereinigung beider Fähigkeiten.
Das Modell ist zwar nicht öffentlich verfügbar und auch eine Demo fehlt, im Paper zeigen die Forschenden jedoch einige niedrig aufgelöste Bildbeispiele für herausfordernde Prompts im Vergleich zu Open-Source-Modellen wie Deepseeks Janus Pro und proprietären Alternativen wie GPT-4o und Gemini 2.5 Flash ("Nano Banana").

Laut Apple Research liegt ein zentrales Problem bisheriger Open-Source-Systeme in einem technischen Konflikt: Während proprietäre Modelle beide Funktionen beherrschen, müssen verfügbare Alternativen oft zwischen guter Bildanalyse oder guter Bilderzeugung wählen.
Die Apple-Forschenden berichten im Forschungspapier, dass bestehende Modelle besonders bei textreichen Aufgaben wie der Analyse von Dokumenten oder Diagrammen deutliche Schwächen zeigen.
Den Grund sehen die Wissenschaftler:innen in der unterschiedlichen Verarbeitung von Bildern. Für das Verstehen funktionieren laut Apple kontinuierliche Datenströme besser, für die Erzeugung braucht es diskrete Tokens. Bisherige Lösungen verwenden separate Systeme für beide Aufgaben, was zu Konflikten im Sprachmodell führe.
Hybrid-System als technische Lösung
Manzano, spanisch für "Apfelbaum", soll dieses Problem mit einem sogenannten Hybrid Image Tokenizer lösen. Das System verwendet laut Apple einen gemeinsamen Bildencoder, der zwei spezialisierte Ausgänge produziert: kontinuierliche Tokens, die Bilder als Fließkommazahlen darstellen und sich gut für das Verstehen eignen, sowie diskrete Tokens, die Bilder in feste Kategorien aus einem begrenzten Wortschatz unterteilen und besser für die schrittweise Generierung funktionieren. Da beide Ausgänge aus derselben Quelle stammen, sollen die Konflikte zwischen den verschiedenen Aufgaben erheblich reduziert werden.
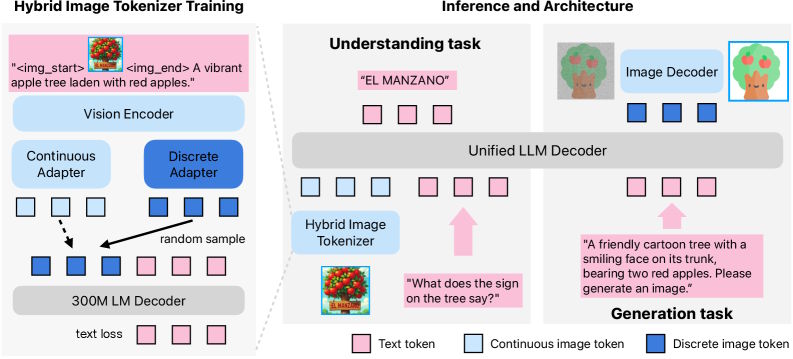
Die Gesamtarchitektur besteht aus drei entkoppelten Komponenten: dem Hybrid-Tokenizer, einem vereinheitlichten Sprachmodell und einem separaten Bilddecoder für die finale Pixelerzeugung. Apple bietet drei Konfigurationen des Bilddecoders mit 0,9, 1,75 und 3,52 Milliarden Parametern an, die Auflösungen von 256 bis 2048 Pixel unterstützen.
Das Training erfolgt laut Apple in drei Phasen mit 2,3 Milliarden Bild-Text-Paaren aus einer Mischung öffentlicher und intern lizenzierter Quellen sowie einer Milliarde internen Text-zu-Bild-Paaren. Das Training umfasst nach Angaben der Forschenden insgesamt 1,6 Billionen Tokens. Zusätzlich kommen synthetische Daten etwa von DALL-E 3 und ShareGPT-4o zum Einsatz.
Apple berichtet von Spitzenleistungen
In den Apple-Evaluationen übertrifft Manzano andere vereinheitlichte Modelle deutlich. Bei Wissens- und Reasoning-Benchmarks wie ScienceQA, MMMU und MathVista erzielt die 30-Milliarden-Version laut Apple Spitzenplätze. Besonders stark seien die Resultate bei textreichen Aufgaben wie der Analyse von Diagrammen und Dokumenten.
Die Skalierungsexperimente zeigen laut Apple kontinuierliche Verbesserungen beim Wachstum von 300 Millionen auf 30 Milliarden Parameter. Das 3-Milliarden-Modell verbesserte sich nach den Messungen um über 10 Punkte bei verschiedenen Aufgaben gegenüber der kleinsten Version.
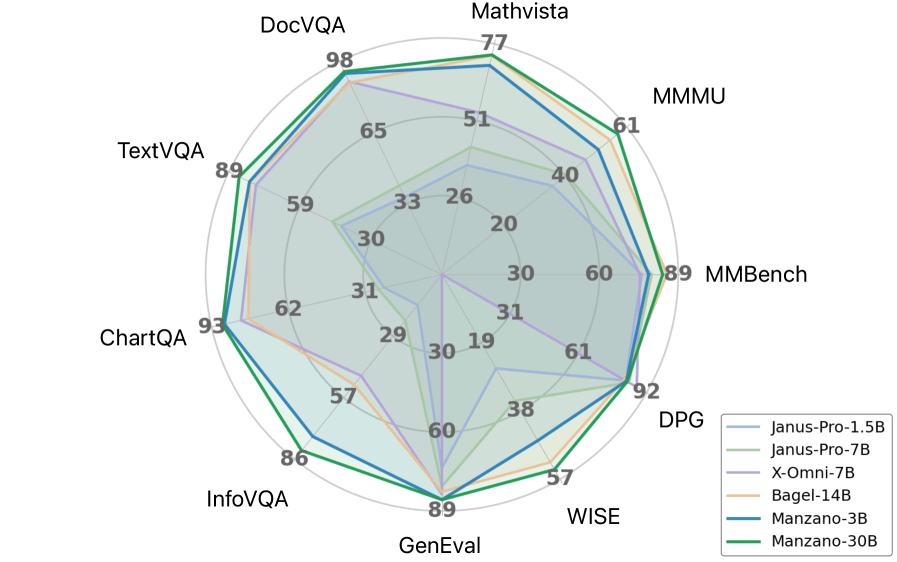
Vergleichsstudien zwischen dem vereinheitlichten System und spezialisierten Einzelmodellen zeigen laut Apple minimale Leistungsunterschiede. Bei der 3-Milliarden-Variante liegt der Performance-Gap laut Apple unter einem Punkt.
Für die Bilderzeugung erreicht Manzano nach Apple-Evaluationen Spitzenleistungen unter den vereinheitlichten Modellen bei etablierten Benchmarks. Das System kann laut den Forschenden komplexe Anweisungen umsetzen sowie Stile übertragen, Bilder ergänzen und Tiefen schätzen.

Modularer Ansatz für zukünftige Systeme
Die Forschenden positionieren Manzano als eine leistungsstarke Alternative zu bestehenden Systemen und sehen in dem modularen Ansatz einen vielversprechenden Weg für zukünftige multimodale KI. Das entkoppelte Design ermöglicht nach Apple-Angaben unabhängige Verbesserungen der einzelnen Komponenten und nutzt etablierte Trainingsmethoden aus verschiedenen KI-Bereichen.
Apples Weg zu einer souveränen Apple Intelligence bleibt dennoch holprig: Erste Benchmarks zeigen, dass die hauseigenen Foundation-Modelle trotz des neuen Frameworks für On-Device-KI noch deutlich hinter der Konkurrenz zurückliegen. Um die Leistungslücke kurzfristig zu schließen, wechselt Apple in Apple Intelligence ab iOS 26 auf OpenAIs neues Modell GPT-5. Vor diesem Hintergrund zeigt Manzano zwar, dass Apple technisch Boden gutmacht, doch erst künftige Integrationsschritte werden zeigen, ob das Hybrid-Modell die Abhängigkeit von externen Spitzen-LLMs wirklich verringern kann.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.