Google PaLM: Riesige Sprach-KI kann Witze erklären
Google stellt den neuesten Fortschritt bei Künstlicher Intelligenz vor: Das Sprach-KI-Modell PaLM ist riesig, mächtig und der erste Baustein einer großen Vision.
Im vergangenen Jahr stellte Google das Pathways-Konzept vor, eine KI-Architektur für die nächste Generation Künstlicher Intelligenz. Die Vision: Ein einzelnes, großes KI-Modell soll viele unterschiedliche Aufgaben beherrschen.
Mit dem PaLM-Modell (Pathways Language Model) enthüllt Google jetzt den ersten Baustein der Pathway-Architektur für die natürliche Sprachverarbeitung.
PaLM ist eines der größten KI-Sprachmodelle
Mit 540 Milliarden Parametern gehört PaLM zu den größten seiner Art. Die Google-Schwester Deepmind stellte mit Gopher im Dezember 2021 ein Modell mit 280 Milliarden Parametern vor, die OpenAIs bekannte Sprach-KI GPT-3 mit 175 Milliarden Parametern bei vielen Sprachaufgaben schlagen konnte. Nvidia und Microsoft trainierten gemeinsam das 530-Milliarden-Parameter starke Megatron-Modell. All diese Systeme basieren auf der Transformer-Architektur.
Grundlage für das KI-Training ist ein von Google für Pathways entwickeltes Trainingssystem, mit dem die KI über 6144 Chips hinweg trainiert werden konnte, parallel auf zwei Cloud TPU v4 Pods. Laut Google war es das bisher größte TPU-basierte Trainings-Setup für Künstliche Intelligenz.
Trainiert wurde PaLM mit einer Mischung aus englischen und mehrsprachigen Datensätzen. Die Texte stammen von "hochwertigen" Webseiten wie Wikipedia, aus Büchern und Diskussionen und - im Falle von Code-Beispielen - von der Programmierplattform Github.
Sprach-KI wird weiter besser, wenn sie größer wird
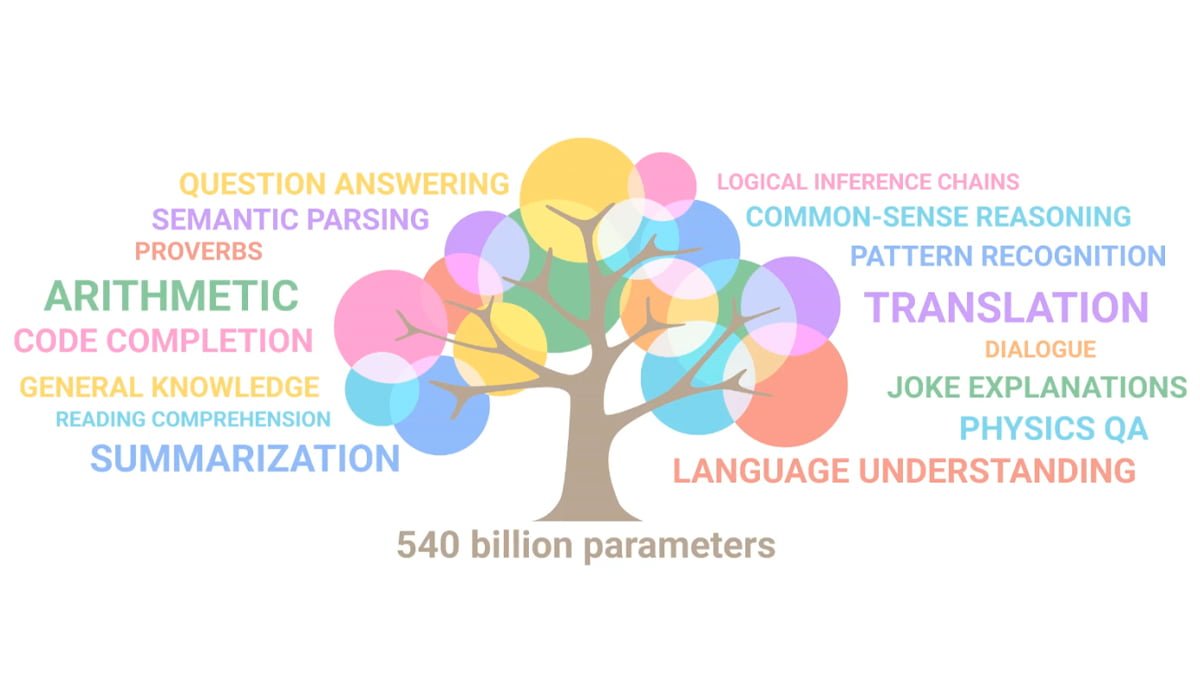
Die wohl wichtigste Erkenntnis aus Googles PaLM-Modell ist, dass die Sprachverarbeitung der KI-Modelle weiter entlang der Anzahl ihrer Parameter skaliert. Einfach gesagt: Je größer das Modell ist, desto besser und vielfältiger verarbeitet es Sprache. Google veranschaulicht das in der folgenden Animation.
Je mehr Parameter das Sprachmodell hat, desto mehr Fähigkeiten soll es entwickeln. Google vergleicht das mit Ästen an einem wachsenden Baum. | Video: Google
Laut Google zeigt PaLM "bahnbrechende Fähigkeiten" bei zahlreichen besonders anspruchsvollen Sprachaufgaben wie Sprachverständis- und generierung, schlussfolgerndes Denken und codebezogene Aufgaben.
Das Modell soll etwa Ursache und Wirkung unterscheiden können, Begriffskombinationen in geeigneten Kontexten verstehen und sogar einen Film anhand eines Emojis erraten, wie die folgende Animation illustriert.
Video: Google
Wie es bei großen Sprachmodellen gängige Praxis ist, kann auch PaLM mit wenigen zusätzlichen Beispielen für spezielle Aufgaben wie die Code-Generierung feinjustiert werden. Bei diesem sogenannten "few-shot"-Lernen soll PaLM alle bekannten großen KI-Sprachmodelle schlagen, was das Modell vielfältiger einsetzbar macht.
Speziell logische Schlussfolgerungen und ein "generelles Wissen" sollen von einer steigenden Parameteranzahl profitieren. Zeigt man der KI etwa in einem Beispiel den Lösungsweg einer einfachen Textaufgabe auf ("Chain of thought prompting"), kann sie eine vergleichbare Aufgabe eigenständig lösen.

Das Textverständnis von PaLM soll so weit gehen, dass die KI einfache Witze erklären kann. Google zeigt das am folgenden Beispiel, bei dem der für das KI-Training eingesetzte Cloud-Computer (Pod) mit einem Pottwal verglichen wird.
Die Aufforderung "Erkläre diesen Witz" in Kombination mit dem Hinweis, wann der Witz beginnt, reicht dem PaLM-Modell für eine passende Erläuterung. Der Witz samt seiner Erklärung soll nicht in den Trainingsdaten enthalten gewesen sein.

Bei Code-Aufgaben soll PaLM dank der starken few-shot-Fähigkeit mit weniger Datenbeispielen eine ähnliche Leistung erzielen wie Codex von OpenAI. Im Datensatz für das Vortraining befanden sich rund fünf Prozent Code-Beispiele.
Bei der Programmiersprache Python benötigte PaLM beim Training laut Google 50 Mal weniger Code-Daten als Codex für eine vergleichbare Leistung. Googles Forschende sehen das als Hinweis, dass "größere Modelle stichprobeneffizienter sein können als kleinere Modelle, da sie das Lernen aus anderen Programmiersprachen und natürlichsprachlichen Daten besser übertragen können."
Auf dem Pfad zur Pathways-Vision
Das Google-Team geht davon aus, dass der Ansatz, riesige KI-Modelle zu trainieren, um sie dann mit wenigen Daten auf spezifische Aufgaben feinzujustieren, mit PaLM nicht ausgereizt ist. Die Few-Shot-Fähigkeit soll von größeren Modellen weiter profitieren: "Die Ausweitung der Grenzen der Modellskalierung ermöglicht die bahnbrechende few-shot Leistung von PaLM bei einer Vielzahl von Aufgaben in den Bereichen natürliche Sprachverarbeitung, Schlussfolgerungen und Code."
PaLM ebne so den Weg für noch leistungsfähigere Modelle, da es die Fähigkeit zur Skalierung mit neuartigen architektonischen Entscheidungen und Trainingsschemata kombiniere. Es sei daher ein wichtiger Schritt hin zur großen Pathways Vision, bei dem ein einziges KI-Modell verschiedene Daten verstehen und so effizient Tausende oder gar Millionen Aufgaben bewältigen kann.
Der PaLM-Code ist bei Github verfügbar. Mehr zum aktuellen Stand bei Sprach-KI-Forschung gibt es in unserem KI-Podcast DEEP MINDS mit Sebastian Riedel von Meta AI.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.