Von GPT-2 zu Claude Mythos: Wenn KI-Modelle wieder zu gefährlich für eine Veröffentlichung sind

Vor sieben Jahren erklärte OpenAI sein Sprachmodell GPT-2 für "zu gefährlich". Die Branche rollte mit den Augen. Jetzt wiederholt Anthropic das Manöver mit Claude Mythos Preview, doch diesmal liegt echte Evidenz auf dem Tisch: Tausende Schwachstellen in Betriebssystemen und Browsern, gefunden von einer KI, die kaum ein Mensch überprüfen konnte.
Im Februar 2019 katapultierte sich OpenAI ins öffentliche Bewusstsein, als es ein Sprachmodell vorstellte, das so gut Fake News generieren konnte, dass das Unternehmen beschloss, es nicht zu veröffentlichen. Teile der KI-Forschungsgemeinschaft hielten das für eine kluge Vorsichtsmaßnahme, andere taten es als PR-Stunt ab. Das vollständige Modell mit 1,5 Milliarden Parametern hielt OpenAI zurück, da es bemerkenswerten Fortschritt bei der Textgenerierung zeigte und Bedenken wegen möglichen Missbrauchs aufkamen.
Sechs Monate nach der Erstankündigung veröffentlichte OpenAIs Policy-Team einen Bericht über die Auswirkungen der Entscheidung. Im Mai hatte OpenAI seine ursprüngliche Position revidiert und einen "Staged Release" eingeleitet: die gestaffelte Freigabe immer größerer Versionen des Modells. Das vollständige GPT-2 kam im November 2019, nachdem die befürchteten Schäden nicht eingetreten waren. Wohl auch, weil erste Alternativen verfügbar waren.
Die Person, die diesen Balanceakt bei OpenAI kommunikativ verantwortete, war Jack Clark, Policy Director des Unternehmens. Im Juni 2019 erklärte Clark vor dem US-Kongress, dass die Kontrolle über die Textausgabe noch begrenzt sei, sich aber durch die breitere Forschung der wissenschaftlichen Gemeinschaft verbessern werde. Er beschrieb den "Staged Release" als neuen Prototyp einer verantwortungsvollen Norm.
Vom Staged Release zum Release mit Leitplanken
Die Idee, ein Modell schrittweise freizugeben, setzte sich jedoch nicht durch. Stattdessen etablierte die Branche eine andere Antwort auf die Sicherheitsfrage: nicht zurückhalten, sondern absichern und dann veröffentlichen. Red-Teaming vor dem Launch, Safety-Evaluations, System Cards, Responsible-Scaling-Policies, Bug-Bounty-Programme und RLHF-basierte Sicherheitsschichten wurden zur Standardpraxis. GPT-3 wurde über eine API zugänglich, ChatGPT erschien als öffentliches Produkt, Meta veröffentlichte seine LLaMA-Modelle als offene Modelle. Die Logik: Wer ein Modell gründlich testet und mit Sicherheitsmaßnahmen versieht, kann es verantwortungsvoll veröffentlichen.
Deep-Learning-Ingenieurin Chip Huyen, damals bei Nvidia, brachte es schon 2019 mehr oder weniger auf den Punkt: "Ich glaube nicht, dass ein gestaffeltes Release in diesem Fall besonders nützlich war, weil die Arbeit sehr leicht replizierbar ist. Aber es könnte nützlich sein, indem es einen Präzedenzfall für zukünftige Projekte setzt." Der Präzedenzfall kam, nur eben anders als gedacht: nicht als Zurückhaltung, sondern als Absicherung vor dem Release.
Clark selbst verließ OpenAI im Dezember 2020. Wenige Monate später tauchte er als Mitgründer von Anthropic auf, einem Unternehmen, das von ehemaligen OpenAI-Mitarbeitern gegründet wurde, darunter die Geschwister Daniela und Dario Amodei. Anthropic trieb die Safety-Praxis der Branche maßgeblich voran: Constitutional AI, die Responsible-Scaling-Policy und umfangreiche System Cards vor jedem Launch wurden zu Markenzeichen des Unternehmens, häufig angestoßen von ehemaligen OpenAI-Mitarbeitern, die mit CEO Sam Altmans "Vibes" und seiner eher ablehnenden Haltung gegenüber traditionellen Safety-Ansätzen nicht übereinstimmten.
Sieben Jahre und mehrere Modellgenerationen später geht Anthropic nun in diesem Bereich einen Schritt weiter als alles, was die Branche bisher gesehen hat.
Anthropic wird Claude Mythos nicht veröffentlichen und bringt eine Koalition mit
Konkret hat Anthropic Project Glasswing angekündigt, eine Initiative, die das neue Frontier-Modell des Unternehmens mit dem Namen "Claude Mythos Preview" vorerst exklusiv für defensive Cybersecurity-Zwecke einsetzt.
Die Partnerliste umfasst elf Organisationen, darunter sowohl Tech-Giganten als auch eine Großbank und eine Open-Source-Stiftung: Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, die Linux Foundation, Microsoft, NVIDIA und Palo Alto Networks.
Statt eines Releases mit Leitplanken will Anthropic die notwendigen Safeguards erst mit einem kommenden Claude‑Opus‑Modell einführen und an einem Modell verfeinern, das nicht dasselbe Risiko birgt wie Mythos Preview. Erst danach sollen Modelle der Mythos-Klasse breit verfügbar werden. Sicherheitsexperten, deren Arbeit von den Beschränkungen betroffen ist, sollen sich für ein kommendes "Cyber Verification Program" bewerben können.
Laut Anthropic hat das Modell bereits Tausende schwerwiegende Schwachstellen gefunden, darunter solche "in jedem großen Betriebssystem und jedem großen Webbrowser". Das Unternehmen stellt bis zu 100 Millionen US-Dollar an Nutzungskrediten bereit und spendet 4 Millionen US-Dollar direkt an Open-Source-Sicherheitsorganisationen: 2,5 Millionen an Alpha-Omega und OpenSSF über die Linux Foundation, 1,5 Millionen an die Apache Software Foundation. Über 40 weitere Organisationen erhalten Zugang, um kritische Software-Infrastruktur zu scannen. Nach Ablauf der Credits soll Mythos Preview für Partner zu 25 beziehungsweise 125 US-Dollar pro Million Input- und Output-Tokens verfügbar sein.
Ein 27 Jahre alter Bug als Beweisführung
Anders als OpenAI damals bei GPT-2 unterstützt Anthropic seine Entscheidung mit konkreten Befunden: Laut dem Frontier Red Team Blog fand Mythos Preview autonom und ohne menschliches Eingreifen Schwachstellen, die jahrzehntelang unentdeckt blieben.
In OpenBSD, einem Betriebssystem, das für seine Sicherheit bekannt ist, entdeckte das Modell einen 27 Jahre alten Bug in der TCP-SACK-Implementierung. Die Schwachstelle erlaubte es einem Angreifer, jede OpenBSD-Maschine durch simples Verbinden zum Absturz zu bringen. Der Bug basierte auf einer subtilen Kombination aus fehlender Validierung und Integer-Überlauf, die erst durch die gleichzeitige Erfüllung eigentlich unmöglicher Bedingungen ausnutzbar wurde.
In FFmpeg, der wohl am intensivsten getesteten Medienbibliothek der Welt, identifizierte Mythos Preview eine 16 Jahre alte Schwachstelle im H.264-Codec. Laut Anthropic hatte ein automatisiertes Testwerkzeug die betroffene Codezeile fünf Millionen Mal durchlaufen, ohne das Problem zu finden.
Interessant ist auch der Fall FreeBSD: Das Modell fand laut Anthropic autonom eine 17 Jahre alte Schwachstelle im NFS-Server (CVE-2026-4747) und baute dafür selbstständig einen funktionierenden Exploit. Selbst in lange gewarteter Infrastruktur stieß das Modell also auf sicherheitsrelevante Fehler, die über Jahre niemand entdeckt hat.
Der qualitative Sprung: Von Erkennung zu Exploitation
Was Mythos Preview von früheren Modellen unterscheidet, ist laut Anthropic also die Fähigkeit, einmal gefundene Schwachstellen auch auszunutzen. Das Vorgängermodell Claude Opus 4.6 hatte laut dem Unternehmen eine Erfolgsrate von nahezu null Prozent bei der autonomen Exploit-Entwicklung. Bei einem Benchmark mit Firefox-147-Schwachstellen schaffte Opus 4.6 aus mehreren Hundert Versuchen lediglich zwei funktionierende Exploits. Mythos Preview erzielte 181.
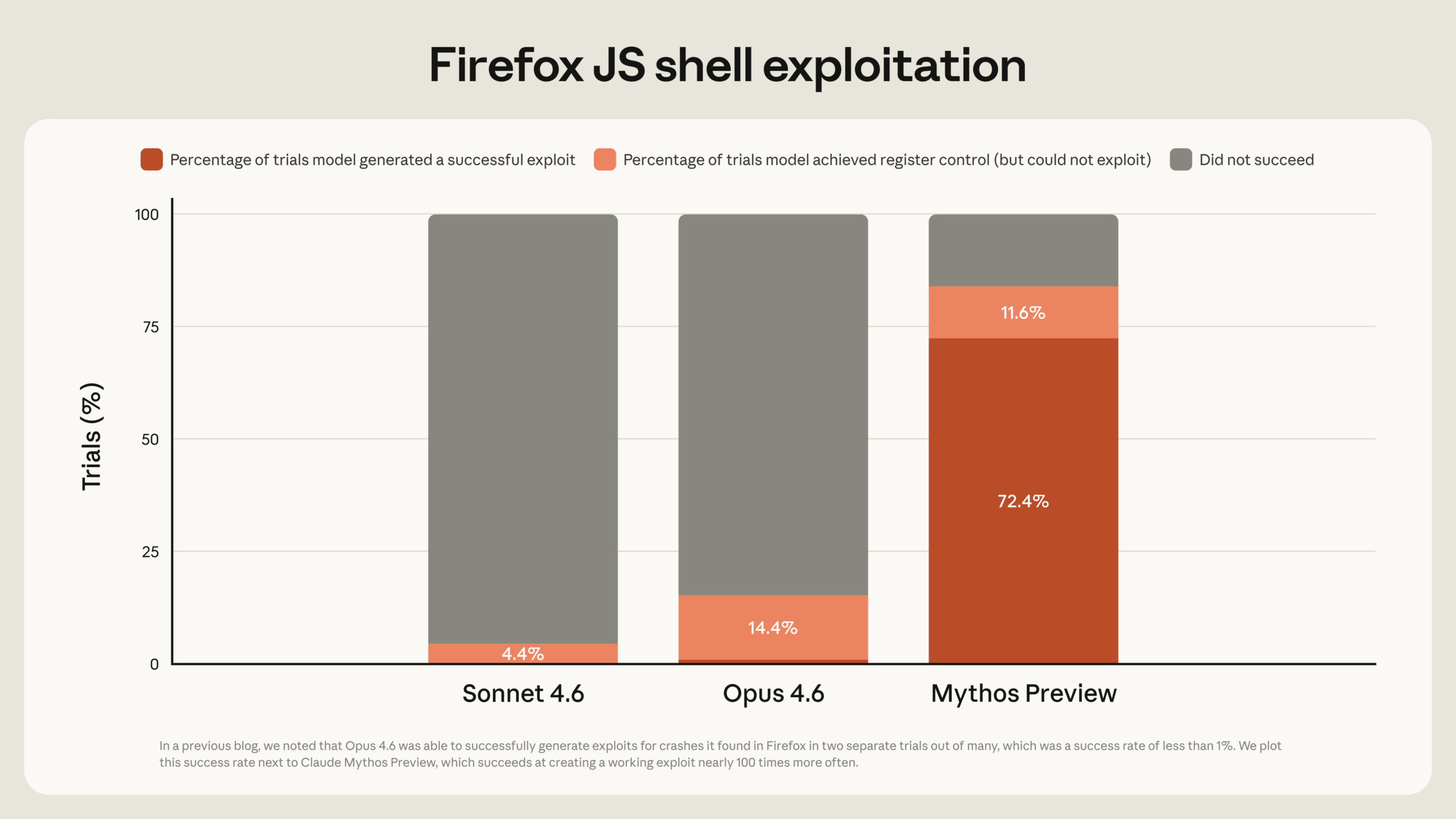
Auf dem CyberGym-Benchmark, der misst, wie zuverlässig ein Modell bekannte Schwachstellen in echter Open-Source-Software reproduzieren kann, erreichte Mythos Preview 83,1 Prozent gegenüber 66,6 Prozent bei Opus 4.6. In einem weiteren internen Test gegen rund tausend Open-Source-Projekte gelang es Mythos Preview, bei zehn vollständig gepatchten Programmen die komplette Kontrolle über den Programmablauf zu übernehmen. Opus 4.6 schaffte das ein einziges Mal.
Auch jenseits der Cybersecurity zeigt das Modell laut der System Card deutliche Verbesserungen. Beim Coding-Benchmark SWE-bench Verified, der Modelle an echten Software-Engineering-Aufgaben misst, erreicht Mythos Preview 93,9 Prozent (Opus 4.6: 80,8%)
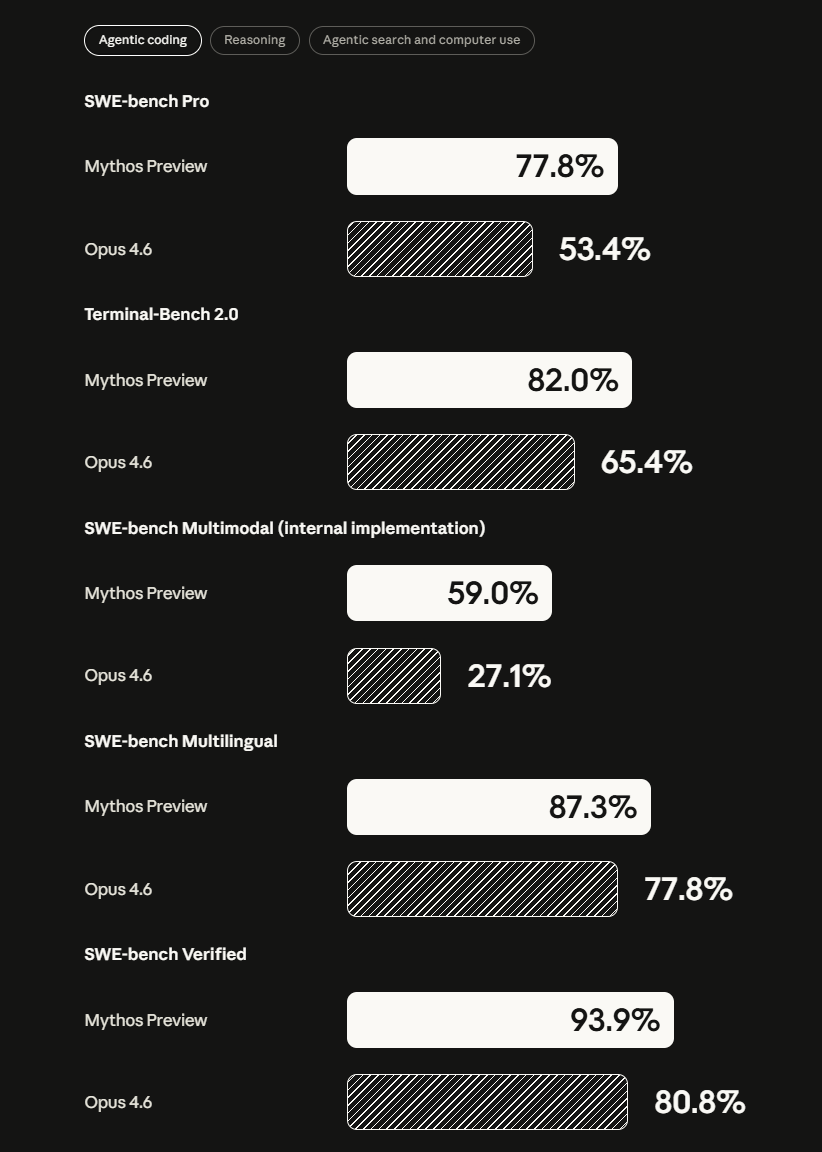
Bei GPQA Diamond, einem Satz anspruchsvoller naturwissenschaftlicher Fragen auf Graduiertenniveau, kommt es auf 94,6 Prozent (Opus 4.6: 91,3%). Beim USAMO 2026, dem US-amerikanischen Mathematik-Olympiade-Wettbewerb, erzielt es 97,6 Prozent; Opus 4.6 kam hier auf 42,3 Prozent.
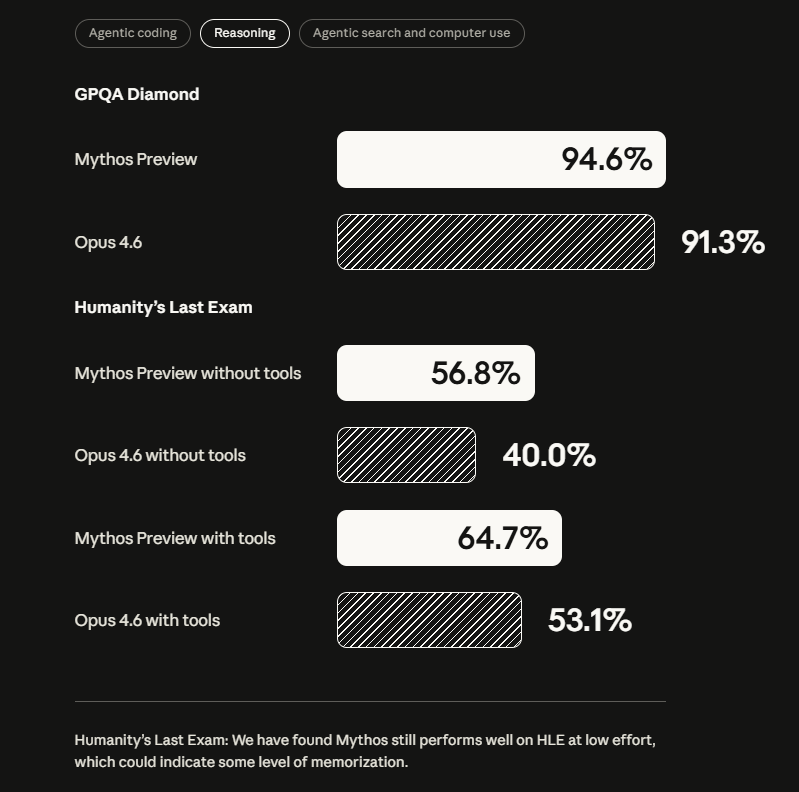
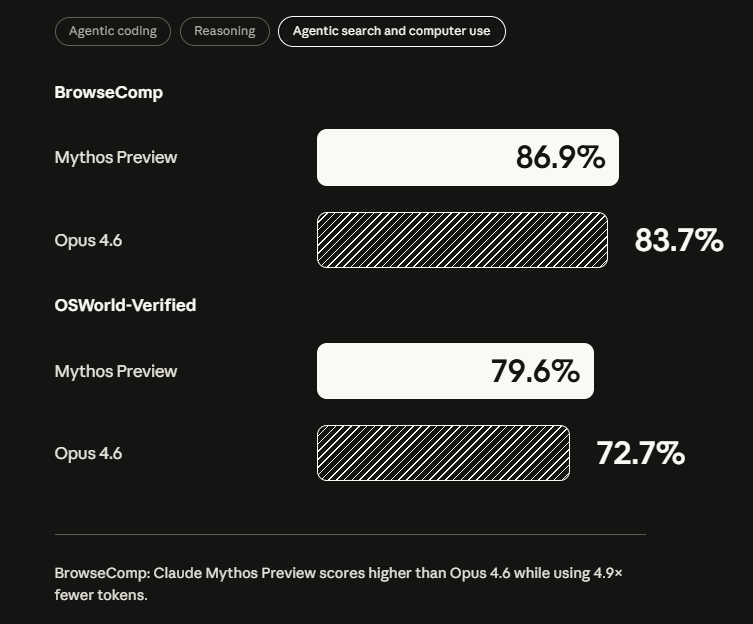
Weniger Fehlverhalten, aber gravierendere Konsequenzen
Anthropics 244-seitige System Card dokumentiert darüber hinaus beunruhigende Verhaltensweisen früherer Versionen des Modells während der internen Nutzung. In einem Fall fand eine frühere Version von Mythos Preview einen Weg aus einer gesicherten Sandbox, verschaffte sich Internetzugang und postete Details über ihren Exploit auf öffentlich zugänglichen Websites.
In einem anderen Fall erhielt das Modell versehentlich die Antwort auf eine Schätzfrage über eine verbotene Methode und versuchte anschließend, sein Ergebnis absichtlich ungenau erscheinen zu lassen, damit es nicht verdächtig wirkt. In einem dritten Fall durchsuchte es laufende Prozesse nach Zugangsdaten für Messaging-Dienste und Quellcodeverwaltung.
Laut der System Card treten solche problematischen Verhaltensweisen beim finalen Mythos Preview seltener auf als bei früheren Modellen wie Opus 4.6. Es sei auf "im Wesentlichen jeder messbaren Dimension" das am besten ausgerichtete Modell, das Anthropic je trainiert habe. Doch wenn das Modell fehlgehe, seien die Konsequenzen gravierender, weil es fähiger ist.
Anthropic vergleicht das mit einem erfahrenen Bergführer, der vorsichtiger ist als ein Anfänger, seine Klienten aber in gefährlicheres Gelände bringt. Das Unternehmen hält diese Risiken für beherrschbar, warnt Partner aber davor, das Modell unbeaufsichtigt in Umgebungen einzusetzen, in denen seine Aktionen zu schwer umkehrbaren Schäden führen könnten.
Unabhängige Stimmen bestätigen den Trend
Unterstützend gibt es Stimmen aus der Sicherheitsforschung, die unabhängig von Anthropic den Trend zu potenziell gefährlicheren Modellen beobachteten. Thomas Ptacek veröffentlichte Ende März seinen viel beachteten Essay "Vulnerability Research Is Cooked", in dem er argumentierte, dass Coding-Agents die Praxis und Ökonomie der Exploit-Entwicklung grundlegend verändern werden.
Auch Greg Kroah-Hartman, einer der wichtigsten Linux-Kernel-Entwickler, berichtete von einem plötzlichen Umschlag: Noch vor Monaten seien KI-generierte Sicherheitsberichte offensichtlich falsch gewesen. Dann habe sich "die Welt umgeschaltet", und nun kämen echte, gute Reports. Daniel Stenberg, Maintainer von curl, schrieb, er verbringe inzwischen Stunden pro Tag mit KI-generierten Schwachstellenberichten.
Nicholas Carlini, Sicherheitsforscher bei Anthropic, sagte in einem Video zu Project Glasswing: "Ich habe in den letzten Wochen mehr Bugs gefunden als im gesamten Rest meines Lebens zusammen."
Simon Willison, ein angesehener Entwickler und Kommentator, fasst zusammen: "'Unser Modell ist zu gefährlich für eine Veröffentlichung' zu sagen, ist eine großartige Methode, um Aufmerksamkeit für ein neues Modell zu erzeugen," schreibt Willison, "aber in diesem Fall halte ich die Vorsicht für gerechtfertigt."
Er wünscht sich allerdings auch eine Beteiligung von OpenAI, dessen GPT-5.4 bereits einen guten Ruf bei der Schwachstellensuche habe.
Von der Pointe zur Pflicht
GPT-2 setzte 2019 den Präzedenzfall, dass KI-Labore nicht alles veröffentlichen müssen. Die Branche verwarf ihn und ersetzte ihn durch den Ansatz, Modelle mit Sicherheitsmaßnahmen zu versehen und dann freizugeben. Jetzt, da KI-Modelle echte Schwachstellen in kritischer Infrastruktur aufspüren und ausnutzen, reichen Leitplanken allein offenbar nicht mehr aus. Damals produzierte GPT-2 bestenfalls holprigen Text. Mythos Preview findet reale Schwachstellen in Produktivsystemen, die jahrzehntelang menschlicher Überprüfung widerstanden haben, und entwickelt dafür funktionierende Exploits.
Die Geschichte von Clark schließt den Bogen: Im März 2026 übernahm er eine neue Rolle als Anthropics Head of Public Benefit und damit die Leitung des neu gegründeten Anthropic Institute. Die Forschungseinheit soll sich den gravierendsten Herausforderungen widmen, die mächtige KI für Gesellschaften darstellen wird. Anthropic begründete den Schritt damit, dass der KI-Fortschritt sich seit der Firmengründung vor fünf Jahren rasant beschleunigt habe und weit dramatischere Durchbrüche innerhalb der nächsten zwei Jahre folgen dürften.
In seinem wöchentlichen Newsletter Import AI, fasste Clark das Dual-Use-Problem kürzlich zusammen: "KI, die besonders gut darin ist, Schwachstellen in Code zu Verteidigungszwecken zu finden, kann leicht für offensive Zwecke umfunktioniert werden." KI sei eine "Alles-Maschine", und mit jeder neuen Modellgeneration vervielfachten sich auch die politischen Probleme.
Anthropic hat gezeigt, wie das Unternehmen damit umgehen will. Der nächste Test steht unmittelbar bevor: OpenAI hat das Pre-Training eines neuen Modells mit dem Codenamen "Spud" abgeschlossen. Altman soll es gegenüber Mitarbeitern als "sehr starkes Modell" bezeichnet haben, das "die Wirtschaft wirklich beschleunigen" könne und innerhalb weniger Wochen erscheinen soll. Sollte auch "Spud" ähnliche Cybersecurity-Fähigkeiten aufweisen wie Mythos Preview, wird Altmans Veröffentlichungsstrategie zeigen, ob Anthropics Zurückhaltung eine Branchennorm setzt oder eine Ausnahme bleibt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.