OpenAI bringt GPT-5.4 mini und nano: Schneller, fähiger, aber auch deutlich teurer
OpenAI veröffentlicht mit GPT-5.4 mini und nano zwei neue kompakte Modelle, die für Coding-Assistenten, Subagenten und Computersteuerung optimiert sind. Die Leistung nähert sich bei GPT-5.4 mini dem Vollmodell, die Preise steigen jedoch deutlich gegenüber den Vorgängern.
GTC 2026: Nvidia bringt mit Groq-3-LPX erstmals spezialisierte Inferenz-Hardware ins eigene Ökosystem
Eigene CPU-Racks, spezialisierte Inferenzchips, eine neue Speicherarchitektur, ein Inferenz-Betriebssystem, offene Modellallianzen und Agenten-Sicherheitssoftware: Auf der GTC 2026 füllt Nvidia die zur CES vorgestellte Vera-Rubin-Plattform mit einer Reihe neuer Bausteine.
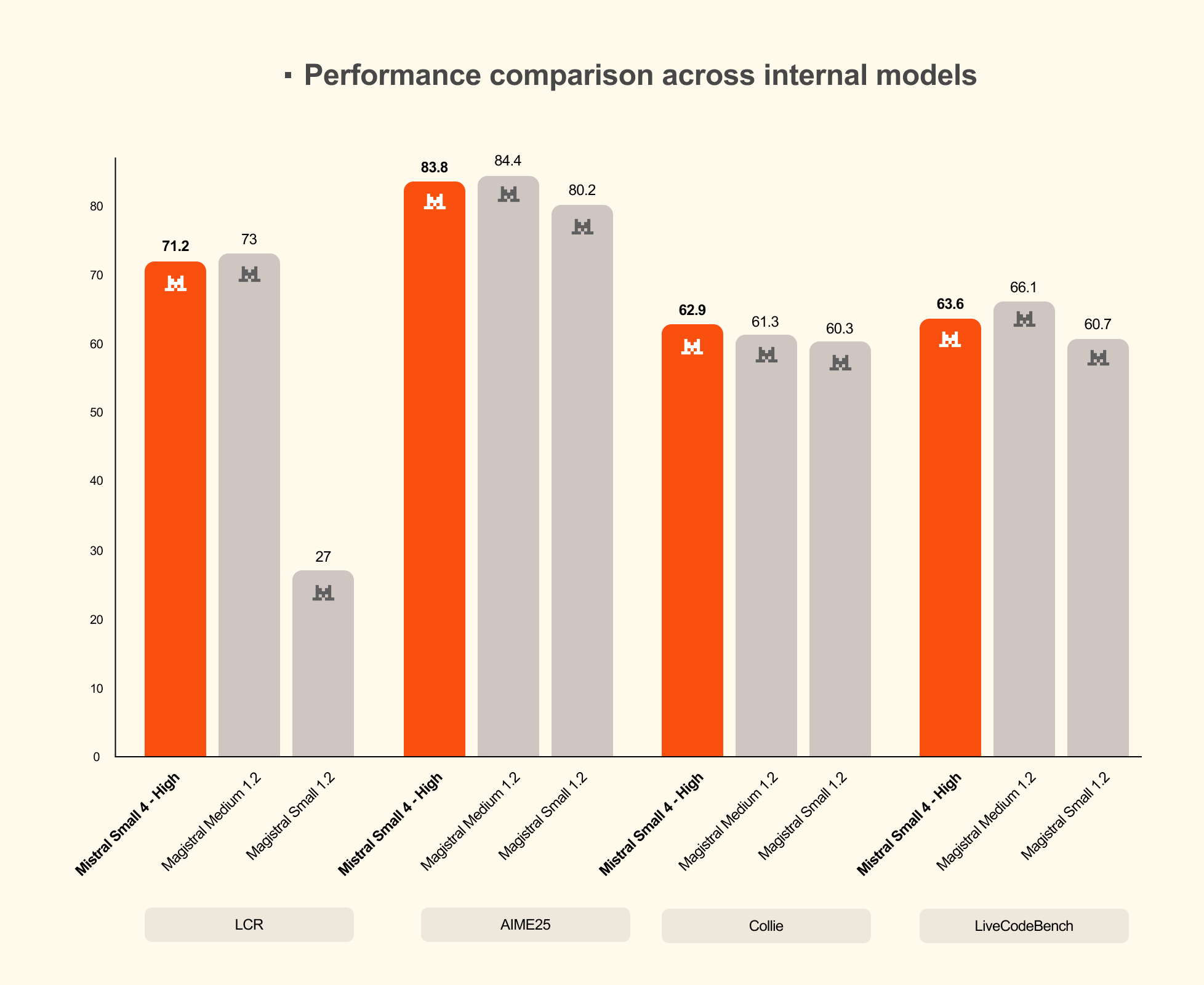
Mistral AI hat mit Mistral Small 4 ein neues Modell veröffentlicht, das schnelle Textantworten, logisches Denken und Bildverarbeitung in einem vereint. Obwohl das Modell 119 Milliarden Parameter hat, sind pro Anfrage nur 6 Milliarden aktiv, da eine Architektur mit 128 Experten-Modulen jeweils nur vier davon gleichzeitig nutzt. Nutzer können ähnlich zur Konkurrenz über einen Parameter steuern, ob das Modell schnell oder gründlich antworten soll. Laut Mistral AI ist es 40 Prozent schneller und verarbeitet dreimal mehr Anfragen pro Sekunde als der Vorgänger.
Mistral Small 4 mit hoher Reasoning-Stufe erreicht in internen Benchmarks ähnliche oder bessere Werte als die spezialisierten Magistral-Modelle.
Das Modell steht unter der offenen Apache-2.0-Lizenz und ist über Hugging Face, die Mistral API sowie Nvidia-Plattformen verfügbar. Mistral AI tritt zudem der Nvidia Nemotron Coalition bei, einem Zusammenschluss von Unternehmen, der die Entwicklung offener KI-Modelle vorantreiben soll. Bereits Anfang Dezember hatte Mistral AI mit der Mistral-3-Reihe neue multimodale Open-Source-Modelle veröffentlicht, darunter das Flaggschiff Mistral Large 3 mit 675 Milliarden Parametern.
OpenAI plant Milliarden-Joint-Venture mit Private-Equity-Firmen für KI-Vertrieb
OpenAI will seine KI schneller in große Unternehmen bringen und setzt dafür nicht nur auf neue Technik, sondern auf Vertrieb, Partner und Kapital. Gespräche über ein 10-Milliarden-Dollar-Joint-Venture und einen neuen Deployment-Arm zeigen: Der harte Teil beginnt erst nach dem Modellstart, nämlich bei der Einführung in echte Firmenabläufe.