Große Sprachmodelle können sich selbst verbessern

Eine neue Forschungsarbeit zeigt, dass sich große Sprachmodelle (LLM) selbst verbessern können, wenn sie mit ihren eigenen Schlussfolgerungen feinjustiert werden.
Große Sprachmodelle können meist viele Aufgaben lösen, wenige davon allerdings von Haus aus auf hohem Niveau. Sogenanntes Feintuning hilft dabei, die Sprachmodelle für spezifische Ziele zu justieren. Dafür werden sie mit ausgewählten, spezifischen Daten nachtrainiert.
Dieses Vorgehen kann spezialisierte Sprachsysteme aus einem großen Sprachmodell abstrahieren, was deutlich weniger aufwendig als das eigentliche Training des Sprachmodells ist. Allerdings erfordert es noch immer einen gewissen manuellen Aufwand, weil etwa die Daten vorbereitet werden müssen.
Große Sprachmodelle können sich anhand ihrer eigenen Antworten selbst verbessern
Forschende der Universität von Illinois in Urbana-Champaign und von Google zeigen jetzt, dass große Sprachmodelle mittels des Chain-of-Thought-Promptings selbstständig Trainingsdaten für ein Nachtraining generieren können und nach dem Training mit diesen Daten häufiger korrekte Schlussfolgerungen ziehen.
Dafür ließ das Forschungsteam Googles großes Sprachmodell PaLM auf eine Reihe von Fragen Antworten in Form einer Argumentationskette generieren. Im nächsten Schritt filterten die Forschenden die konsistentesten Antworten, die nicht notwendigerweise die richtigen sind, nach der Majority-Voting-Methode. Die so gefilterten Antworten verwendeten sie für das Feintuning des Modells. Den Ansatz nennen die Forschenden "Self-Consistency".
Dies ist vergleichbar mit der Art und Weise, wie ein menschliches Gehirn manchmal lernt: Es denkt bei einer Frage mehrere Male nach, um verschiedene mögliche Ergebnisse abzuleiten, kommt zu dem Schluss, wie die Frage gelöst werden sollte, und lernt dann von seiner eigenen Lösung oder prägt sie sich ein.
Auszug aus dem Paper
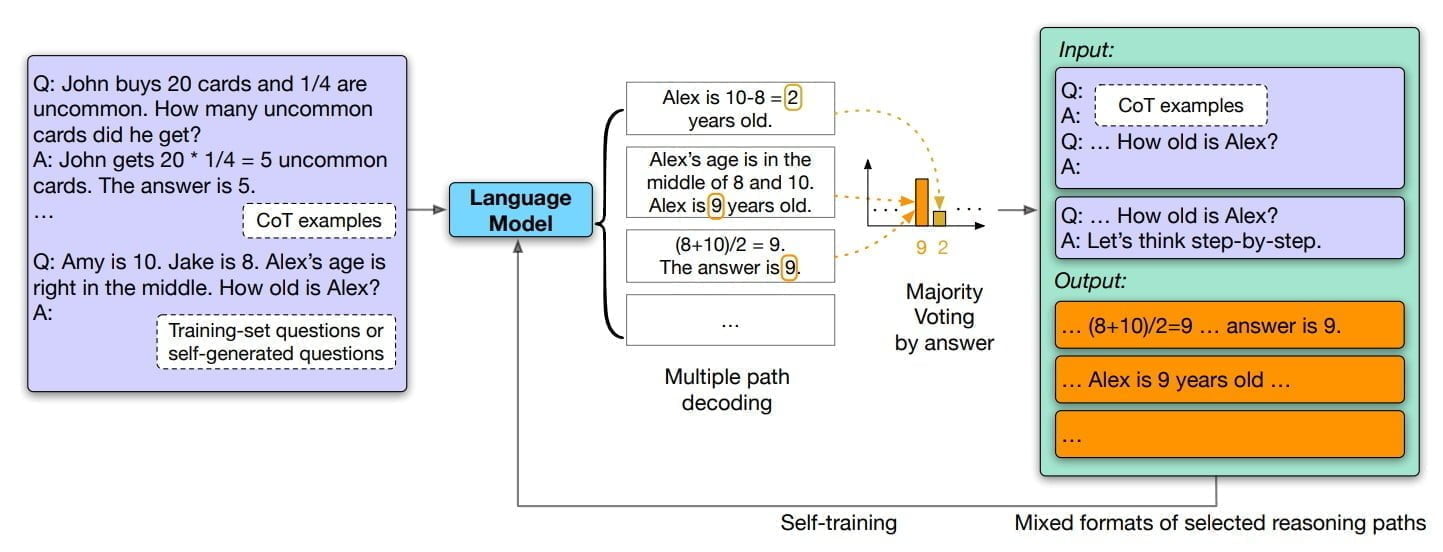
Den etwaigen Einfluss falscher Antworten im Feintuning schätzen die Forschenden als gering ein: Wenn eine Antwort mehr konsistente Gedankenketten habe, sei die Wahrscheinlichkeit höher, dass sie richtig sei. Umgekehrt hätten wahrscheinlich falsche Antworten wenige konsistente Gedankenketten und würden sich beim Feintuning daher nicht signifikant auf die Performance eines Modells auswirken.
Selbstverbesserte Sprachmodelle erzielen neue Bestwerte in Benchmarks
In sechs Benchmarks für maschinelle Schlussfolgerung erzielt das mit selbst erzeugten Schlussfolgerungen feingetunte Sprachmodell Verbesserungen zwischen 1,1 und 7,7 Prozent. In den Benchmarks ARC, OpenBookQA und ANLI schafft es neue Spitzenwerte.
Die Performance-Steigerung des Sprachmodells durch selbst erzeugte, unmarkierte Datensätze zeigt, dass die Systeme ohne grundlegende Veränderungen in der Architektur bessere Leistungen abrufen können - und das mit einem verhältnismäßig einfachen Ansatz. Im nächsten Schritt wollen die Forschenden selbsterzeugte mit gekennzeichneten Daten kombinieren und so die Leistung von LLMs weiter verbessern.
Ein anderes Beispiel für das Optimierungspotenzial großer Sprachmodelle ist Deepminds Mind's Eye. Hier verhelfen Daten aus einem Physik-Simulator dem Sprachmodell zu besseren logischen Schlussfolgerungen für physikalische Fragen. Statt eines speziellen Nachtrainings mit Daten wählt Deepmind hier einen hybriden Ansatz, bei dem Spezialwissen an ein externes System ausgelagert wird.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.