Große KI-Modelle könnten bald viel schneller noch größer werden

Google zeigt eine neue Methode, die Mixture-of-Experts-Modelle verbessert und ihre Trainingsdauer im Schnitt halbiert.
Die Skalierung von Modellgröße, Trainingsdaten und anderen Faktoren hat zu großen Fortschritten in der KI-Forschung geführt, etwa in der Verarbeitung natürlicher Sprache oder der Bildanalyse und -generierung. Forschende konnten bereits mehrfach eine direkte Beziehung zwischen Skalierung dieser Faktoren und der Modellqualität nachweisen.
Immer größere Modelle mit hunderten Milliarden oder sogar Billionen von Parametern sind daher in der Entwicklung. Um die Trainingseffizienz solcher gigantischen Netze zu erhöhen, setzen einige KI-Unternehmen vermehrt auf sogenannte "Sparse Models".
In diesen Modellen werden für die Bearbeitung etwa eines Token in einem Sprachmodell nur Teile des Netzes genutzt. In klassischen "Dense Models" wie GPT-3 wird jede Verarbeitung durch das komplette Netz durchgeführt.
Google verfolgt mit dem Pathways-Projekt die Zukunft Künstlicher Intelligenz, die einmal live neue Aufgaben lernen und zahlreiche Modalitäten verarbeiten können soll. Zentrales Element von Pathways ist die Skalierung - und damit auch Sparse Modelling. In einer neuen Arbeit zeigt Google einen Fortschritt, der das Training der bei Sparse Models verbreiteten Mixture-of-Experts-Architektur deutlich verbessert.
Google forscht seit über zwei Jahren an MoE-Architekturen
Im August 2020 zeigte Google GShard, eine Methode für die Parallelisierung von KI-Berechnungen. Die Methode erlaubte erstmals die Implementierung eines 600 Milliarden Parameter großen "sparse" trainierten Mixture-of-Experts-Modells (MoE-Transformer).
Innerhalb eines Transformer-Moduls gibt es üblicherweise ein einzelnes Feed Forward Network, das Informationen wie Token weiterleitet. In einem MoE-Transformer gibt es mehrere solcher Netze - die namensgebenden Experten. Statt alle Token durch ein einziges Netz zu führen, verarbeiten die Experten nur bestimmte Token.
In dem mit GShard trainierten MoE-Transformer wird üblicherweise jedes Token von zwei Experten verarbeitet. Dahinter steht die Intuition, dass die Künstliche Intelligenz nicht erfolgreich lernen kann, wenn es einen Experten nicht mit mindestens einem weiteren Experten vergleichen kann.
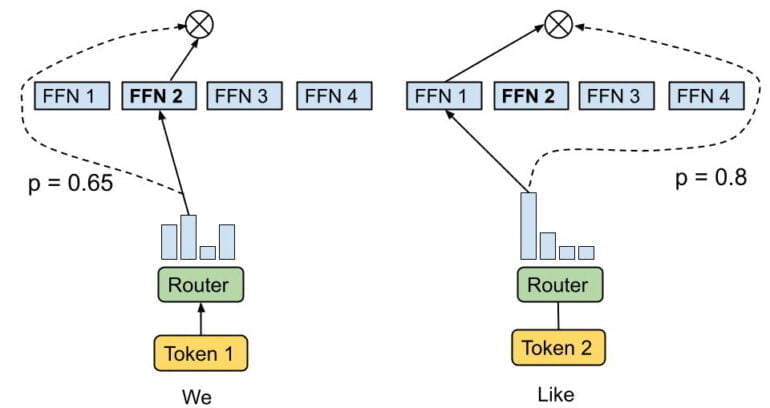
Im Januar 2021 stellten Google-Forschende dann das 1,6 Billionen große "Switch Transformer"-Modell vor, ebenfalls ein sparse trainierter MoE-Transformer. Ein wesentlicher Unterschied: Statt zwei oder mehrerer Experten-Netze pro Token leitet ein Router die Informationen immer nur an ein Netz weiter. Google vergleicht diesen Prozess mit einem Schalter. Daher der Name des KI-Modells.
In der Arbeit zeigte Google, dass der Switch Transformer schneller trainiert werden kann und bessere Ergebnisse erzielt als bisherige Ansätze.
Konventionalle MoE-Architekturen neigen zu Ungleichgewichten
Nun hat Google eine neue Arbeit veröffentlicht, die weitere Verbesserungen für das MoE-System bringt. Bestehende Varianten wie Switch Transformer haben laut der Autor:innen einige Nachteile: So können bestimmte Experten-Netze während des Trainings mit einem Großteil der Tokens trainiert werden, sodass nicht alle Experten ausreichend genutzt werden.
Das führe zu einem Ungleichgewicht, bei der übermäßig ausgelastete Experten-Netze Token nicht verarbeiten, um zu vermeiden, dass ihnen der Speicher ausgeht. In der Praxis führe das zu schlechteren Ergebnissen.
Zudem sei die Latenz des gesamten Systems durch den am meisten belasteten Experten bestimmt. Bei einem Ungleichgewicht gehen so auch einige der Vorteile der Parallelisierung verloren.
Es sei außerdem wünschenswert, dass ein MoE-Modell seine Rechenressourcen flexibel auf der Grundlage der Komplexität der Eingabe verteilt. Bislang wird jedem Token immer die gleiche Anzahl an Experten zugewiesen - im Falle von GShard sind das zwei, beim Switch Transformer einer.
Google zeigt Mixture-of-Experts mit Expert Choice Routing
Als Ursache für diese Nachteile identifiziert Google die gewählte Routing Strategie. Konventionelle MoE-Modelle nutzten "Token-Choice Routing", das selbstständig eine gewisse Anzahl Experten für jedes Token auswählt.
Google schlägt dagegen einen Experten für die Experten vor: Im sogenannten "Expert Choice Routing" wählt der Router eine gewisse Anzahl von Token für jedes Experten-Netz aus. Damit kann die Zuweisung flexibler auf die Komplexität der vorhandenen Token reagieren.
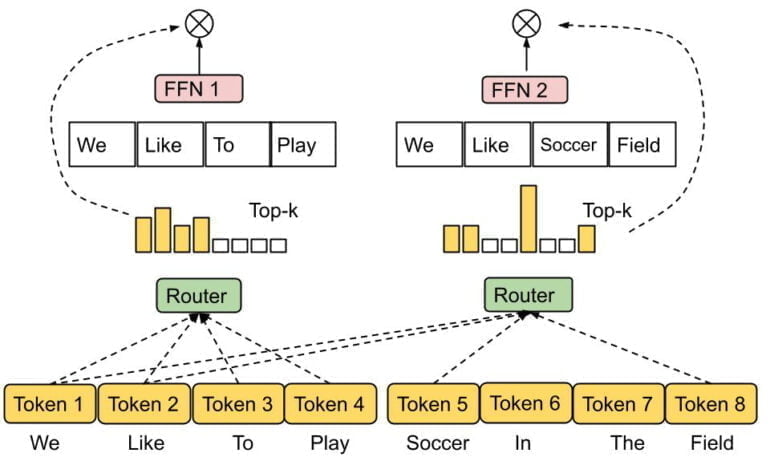
Laut Google erreiche die Methode trotz ihrer Einfachheit durch die Expertenwahl einen perfekten Lastausgleich. Sie ermögliche zudem eine flexiblere Zuweisung von Modellleistung, da die Token von einer variablen Anzahl von Experten verarbeitet werden können.
In einem Vergleich mit Switch Transformer und GShard zeigt Google, dass die neue Methode die Trainingszeit mehr als halbieren kann. Bei gleichem Rechenaufwand zeige sie zudem eine höhere Leistung beim Nachtraining von elf ausgewählten Aufgaben in den Benchmarks GLUE und SuperGLUE. Bei geringeren Aktivierungskosten übertreffe die Methode zudem das dichte T5-Modell in sieben der elf Aufgaben.
Das Team zeigt auch, dass ein Großteil der Token durch die Methode zu einem oder zwei Experten geleitet werden, 23 Prozent zu drei oder vier und nur etwa 3 Prozent zu vier oder mehr Experten. Das bestätige die Hypothese, dass das Expert Choice Routing lernt, den Token eine variable Anzahl von Experten zuzuordnen.
Unser Ansatz für Expert Choice Routing ermöglicht heterogene MoE mit unkomplizierten algorithmischen Innovationen. Wir hoffen, dass dies zu weiteren Fortschritten in diesem Bereich sowohl auf der Anwendungs- als auch auf der Systemebene führen kann.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.