Alibabas Qwen2.5-Turbo liest zehn Romane in knapp einer Minute

Alibabas KI-Labor hat eine neue Version seines Sprachmodells Qwen vorgestellt, die Texte von bis zu einer Million Token verarbeiten kann - das entspricht etwa zehn Romanen. Die Geschwindigkeit wurde dabei vervierfacht.
Qwen hat sein im September vorgestelltes Sprachmodell Qwen2.5 bisher 128.000 auf eine Kontext-Länge von 1 Million Token erweitert. Damit könne Qwen2.5-Turbo zehn vollständige Romane, 150 Stunden Transkripte oder 30.000 Codezeilen verarbeiten.
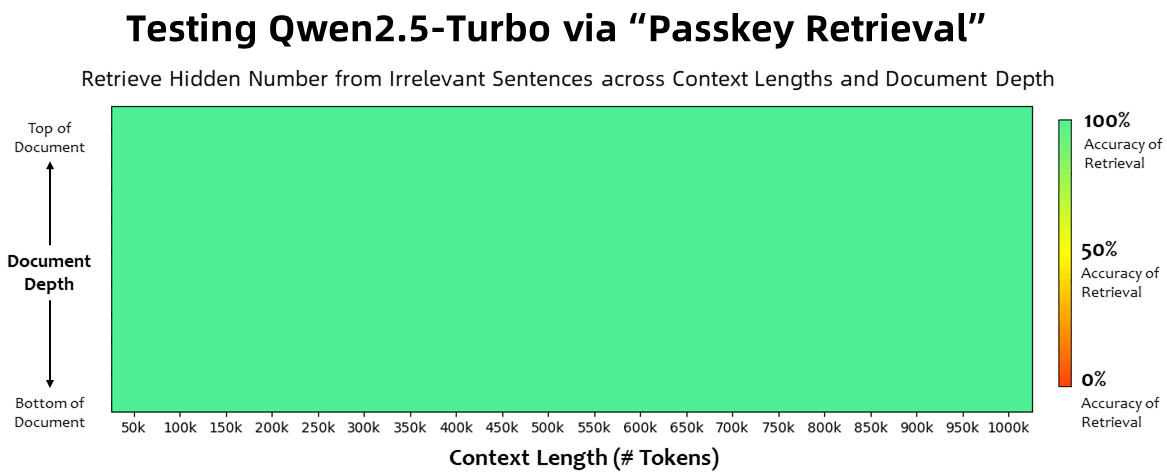
100 Prozent Genauigkeit bei Zahlenabruf
Bei der Passkey-Retrieval-Aufgabe, bei der versteckte Zahlen in 1 Million Token irrelevanten Texts gefunden werden müssen, erreicht das Modell eine Genauigkeit von 100 Prozent, unabhängig von der Position der Information im Dokument. Das "Lost in the Middle"-Phänomen, bei dem ein Sprachmodell hauptsächlich Anfang und Ende eines Prompts berücksichtigt, scheint damit ein Stück weit überwunden zu sein.
In verschiedenen Benchmarks für das Verständnis langer Texte übertrifft Qwen2.5-Turbo Konkurrenzmodelle wie GPT-4 und GLM4-9B-1M. Gleichzeitig bleibt die Leistung bei kurzen Sequenzen mit GPT-4o-mini vergleichbar.
In einer Bildschirmaufnahme demonstriert Qwen die Fähigkeiten seines neuen Sprachmodells, die komplette "Trisolaris"-Trilogie von Cixin Liu mit einer Gesamtlänge von 690.000 Token in kurzer Zeit zusammenzufassen. | Video: Qwen
Sparse Attention beschleunigt Inferenz um Faktor 4,3
Durch die Verwendung von Sparse-Attention-Mechanismen konnte Qwen die Zeit bis zum ersten Token bei der Verarbeitung von 1 Million Token von 4,9 Minuten auf 68 Sekunden reduzieren. Das entspricht einer Beschleunigung um den Faktor 4,3.

Der Preis bleibt bei 0,3 Yuan (4 Cent) pro 1 Million Token. Bei gleichen Kosten kann Qwen2.5-Turbo 3,6-mal so viele Token verarbeiten wie GPT-4o-mini.
Qwen2.5-Turbo ist ab sofort über die API von Alibaba Cloud Model Studio sowie über Demos auf HuggingFace und ModelScope verfügbar.
Qwen sieht noch Verbesserungsbedarf bei langen Sequenzen
Das Unternehmen räumt ein, dass das aktuelle Modell bei der Lösung von Aufgaben mit langen Sequenzen in realen Anwendungen nicht immer zufriedenstellend funktioniert.
Es gebe noch viele ungelöste Herausforderungen, wie die instabilere Leistung des Modells bei langen Sequenzen und die hohen Inferenzkosten, die den Einsatz größerer Modelle erschweren.
Qwen will die Ausrichtung an menschlichen Präferenzen bei langen Sequenzen weiter erforschen, die Inferenzeffizienz optimieren, um die Rechenzeit zu reduzieren, und versuchen, größere und leistungsfähigere Modelle mit langem Kontext auf den Markt zu bringen.
Was nutzen große Kontextfenster?
Die Kontextfenster großer Sprachmodelle sind über die letzten Monate kontinuierlich gewachsen. Als praktikabler Standard hat sich derzeit eine Größenordnung zwischen 128.000 (GPT-4o) und 200.000 (Claude 3.5 Sonnet) eingependelt, es gibt jedoch auch Ausreißer wie Gemini 1.5 Pro mit bis zu 10 Millionen oder Magic AIs LTM-2-mini mit 100 Millionen Token.
Während diese Fortschritte grundsätzlich zum Nutzen großer Sprachmodelle beitragen, lassen Studien immer wieder am Vorteil großer Kontextfenster gegenüber RAG-Systemen zweifeln, bei denen zusätzliche Informationen dynamisch aus Vektordatenbanken abgerufen werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.