Deepmind AlphaZero: Größer ist besser, sagen KI-Forscher

Für große Sprachmodelle fanden KI-Forschende 2020 Skalierungsgesetze. Eine neue Arbeit zeigt, dass es solche auch für Reinforcement Learning Algorithmen geben könnte.
In einer 2020 veröffentlichten Arbeit mit dem Namen "Scaling Laws for Neural Language Models" untersuchten KI-Forschende empirische Skalierungsgesetze für die Leistung von Sprachmodellen wie GPT-2 oder GPT-3. Sie zeigten, dass die Leistung der Modelle je nach Modellgröße, der Datensatzgröße und dem für das Training verwendeten Rechenaufwand um mehrere Größenordnungen skaliert.
In ihrer Arbeit leitete das Team optimale Hyperparameter für das Training großer Sprachmodelle bei fixem Rechenleistungs-Budget ab, also etwa optimale Netzwerkgröße und Datenmengen. 2022 bestätigten Forschende von Deepmind dann mit Chinchilla, dass solche Skalierungsgesetze zwar existieren, die vom ersten Team vorgeschlagenen Hyperparameter jedoch den positiven Einfluss von mehr Trainingsdaten unterschätzt hatten. Laut Deepmind sollte für ein optimales Training die Modellgröße und die Anzahl der Trainings-Token gleichermaßen skaliert werden.
Skalierungsgesetze treiben KI-Entwicklung an
Schon bei der Veröffentlichung von GPT-2 stellten OpenAI-Forschende fest, dass die Leistung ihres Netzwerks mit der Größe skalierte. Mit GPT-3 zeigte das Unternehmen dann, wie groß der mögliche Leistungssprung durch Skalierung war. Die Skalierungsgesetze gaben in 2020 diesem Phänomen eine allgemeinere Grundlage und motivieren seitdem zahlreiche Entwicklungen und Investitionen in größere Modelle.
Abseits der großen Sprachmodelle gab es bisher wenig Versuche, Skalierungsgesetze zu finden. Ähnlich gestaltete Modelle, etwa für die Bildgenerierung oder OpenAIs Video PreTraining für Minecraft zeigen jedoch einen ähnlichen Trend.
Dass es solche Skalierungsgesetze auch außerhalb solcher "Foundation Models" geben könnte, zeigen jetzt Forschende der Goethe-Universität Frankfurt.
Skalierungsgesetze für Reinforcement Learning
In ihrer Arbeit nehmen die Forschenden eine Analyse im Stil des Skalierungsgesetz-Papers von 2020 vor, statt Sprachmodelle skalieren sie jedoch AlphaZero RL-Agenten, die zwei unterschiedliche Spiele spielen: Connect Four und Pentago. Diese Spiele seien geeignete Kandidaten für ihre Untersuchung, da sie nicht trivial zu erlernen und gleichzeitig leicht genug seien, um eine größere Anzahl von Agenten mit einer überschaubaren Menge an Ressourcen zu ermöglichen, heißt es in der Veröffentlichung.
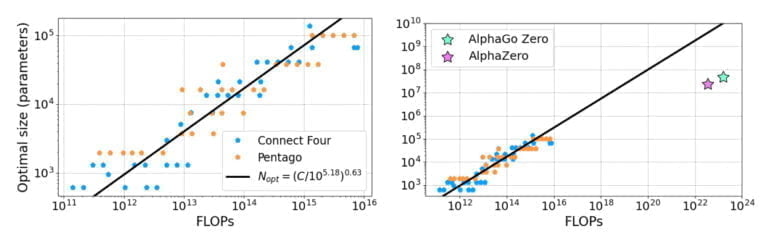
In ihren Versuchen zeigen die Forschenden, dass die Leistung der Agenten als Potenzgesetz mit Größe des neuronalen Netzes skaliert, "wenn die Modelle bis zur Konvergenz an der Grenze der verfügbaren Rechenleistung trainiert werden". Damit sehen sie den Beweis erbracht, dass die aus Sprachmodellen bekannten Skalierungsgesetze auch in den AlphaZero-Modellen vorhanden sind. Sie vermuten, dass auch andere Algorithmen des Reinforcement Learnings ähnliches Skalierungsverhalten aufweisen.
In einer Extrapolation ihrer Ergebnisse zeigt das Team zudem, dass die von Deepmind vorgestellten, bahnbrechenden KI-Systeme AlphaGo Zero und AlphaZero womöglich zu kleine neuronale Netze verwendeten und mit größeren noch bessere Leistung erzielen könnten.
Es sei außerdem möglich, dass Veränderungen an den Hyperparametern, wie sie etwa bei Chinchilla demonstriert wurden, auch im Fall von AlphaZero eine andere optimale Verteilung der Trainingsressourcen ermögliche. Die Untersuchung der Auswirkung der Hyperparameter soll Teil der nächsten Arbeit des Teams werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.