Anthropic-KI kooperiert am besten: Studie vergleicht Sprachmodelle in sozialen Situationen

Eine neue Forschungsarbeit untersucht, wie verschiedene KI-Sprachmodelle in sozialen Situationen zusammenarbeiten. Die Ergebnisse zeigen überraschende Unterschiede zwischen den Modellen.
Forscher haben in einer neuen Studie untersucht, wie gut verschiedene KI-Sprachmodelle miteinander kooperieren können. Die Ergebnisse zeigen deutliche Unterschiede: Während einige Modelle stabile Kooperation entwickeln, neigen andere zur gegenseitigen Blockade.
Die Wissenschaftler ließen dazu KI-Agenten, die auf verschiedenen Sprachmodellen basieren, über mehrere "Generationen" hinweg ein klassisches Kooperationsspiel spielen. In diesem "Donor Game" können die Agenten Ressourcen miteinander teilen und davon profitieren.
Die Studie zeigt, dass das Modell Claude 3.5 Sonnet von Anthropic am besten abschnitt. Laut den Forschern entwickelten Claude-basierte KI-Agenten über die Generationen hinweg stabile Kooperationsmuster und erreichten deutlich höhere Gesamtressourcen als die Konkurrenz.
Große Unterschiede zwischen den Modellen
Im Vergleich dazu zeigten Googles Gemini 1.5 Flash und OpenAIs GPT-4o deutlich schlechtere Ergebnisse. Die GPT-4o-Agenten entwickelten sich sogar in Richtung gegenseitiger Blockade, während Gemini nur schwache Kooperationstendenzen zeigte.
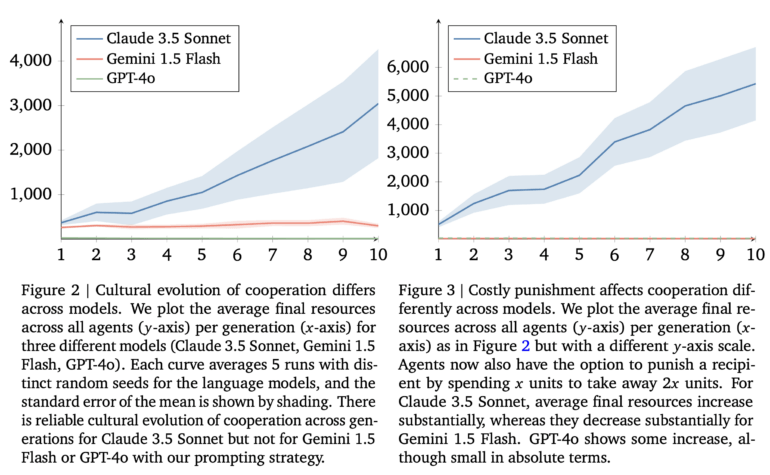
Als die Forscher den KI-Agenten zusätzlich die Möglichkeit gaben, andere für unkooperatives Verhalten zu "bestrafen", verstärkte dies die positive Entwicklung bei Claude 3.5. Die Strategien der erfolgreichen Claude-Agenten wurden im Laufe der Generationen immer komplexer. Sie entwickelten Mechanismen, um kooperatives Verhalten zu belohnen und "Trittbrettfahrer" zu bestrafen.
Bei Gemini hingegen führte die Bestrafungsoption zu einer deutlichen Verschlechterung der Kooperation.
Wichtige Erkenntnisse für den Praxiseinsatz
Die Ergebnisse haben laut den Forschern wichtige Implikationen für den realen Einsatz von KI-Systemen. Wenn KI-Assistenten in Zukunft verstärkt miteinander interagieren, sei ihre Fähigkeit zur Kooperation entscheidend.
Die Studie selbst hat jedoch zahlreiche Einschränkungen: Die Experimente wurden nur mit homogenen Gruppen des jeweils gleichen KI-Modells durchgeführt. In der Realität werden verschiedene Modelle miteinander interagieren müssen. Das verwendete Spiel ist außerdem weit weg von der Komplexität echte Anwendungen. Zudem hat das Team keine Modelle wie OpenAIs o1 in seine Tests integriert - solche Reasoning-Modelle werden aber wohl in Zukunft eine größere Rolle bei Agenten spielen. Auch Googles jüngste Gemini-2.0-Modelle fehlen.
Die Forscher warnen auch, dass Kooperation zwischen KI-Systemen nicht immer wünschenswert ist - etwa wenn es um mögliche Preisabsprachen geht. Eine zentrale Herausforderung sei es daher, KI-Systeme zu entwickeln, die im Sinne der Menschen kooperieren, aber nicht gegen deren Interessen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.