



Das Kontextfenster großer Sprachmodelle gibt an, wie viele Informationen ein KI-Modell auf einen Schlag verarbeiten kann. Es ist heute groß genug, um ganze Büchezusammenzufassen. Doch oft berücksichtigen die Modelle nicht alle darin enthaltenen Informationen. Eine Studie untersucht dies systematisch.
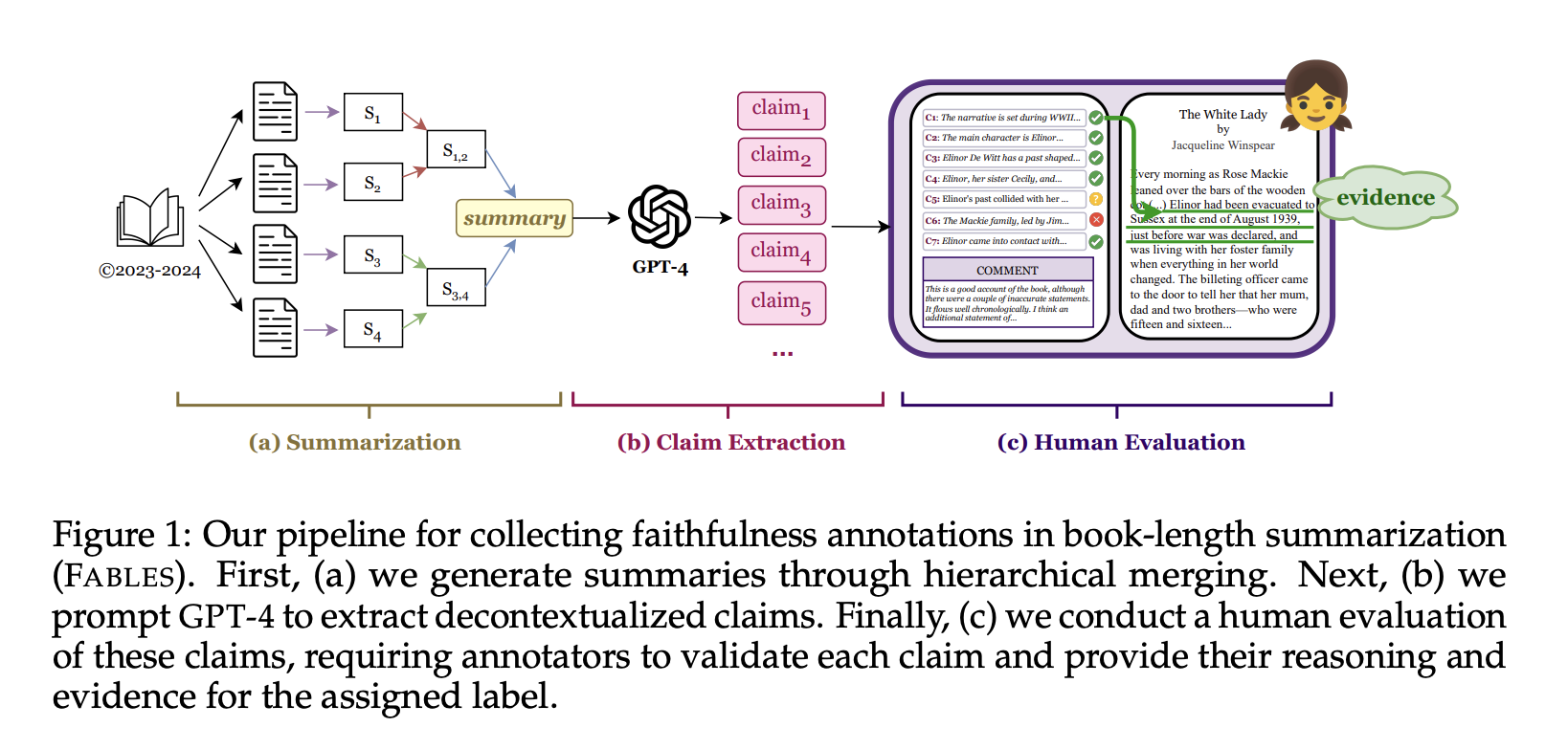
Forscher der UMass Amherst, Adobe, des Allen Institute for AI und der Princeton University haben einen neuen Datensatz namens FABLES (Faithfulness Annotations for Book-Length Summarization) veröffentlicht, um die Forschung zur Bewertung der Zuverlässigkeit und Inhaltsauswahl von KI-generierten Zusammenfassungen für ganze Bücher voranzutreiben.
Die Kontextfenster großer Sprachmodelle sind über die letzten Monate kontinuierlich gewachsen. Die größten finden sich derzeit bei Claude 3 mit 200.000 Token und bei Google Gemini 1.5 Pro sogar mit einer Million Token.
Theoretisch sollten sie also in der Lage sein, lange Dokumente wie ganze Romane zusammenzufassen. Das Problem: Die Qualität dieser Zusammenfassungen kann nur von Personen beurteilt werden, die das umfangreiche Ausgangsmaterial sehr gut kennen. Ein hoher Aufwand.
Zusammenfassungen großer Textmengen: Mixtral gleichauf mit GPT-3.5 Turbo, Claude 3 Opus weit vorne
Um diese Lücke zu schließen, haben die Forscherinnen und Forscher einen Datensatz mit menschlichen Annotationen zu 3.158 Aussagen zusammengestellt, die aus KI-generierten Zusammenfassungen von 26 Romanen extrahiert wurden.
Sie fanden heraus, dass Anthropics neuestes und größtes Modell, Claude 3 Opus, alle Closed-Source-LLMs von OpenAI deutlich übertrifft: 90 Prozent der Behauptungen wurden als zuverlässig eingestuft, gefolgt von GPT-4 und GPT-4 Turbo mit 78 Prozent, GPT-3.5 Turbo mit 72 Prozent und Mixtral, das einzige getestete Open-Source-Modell, mit 70 Prozent nur knapp dahinter.
Die Analyse der Annotationen ergab, dass sich die meisten unzuverlässigen Aussagen auf Ereignisse, Zustände von Personen und Beziehungen bezogen. Um die Aussagen zu widerlegen, war in der Regel eine indirekte, mehrstufige Argumentation notwendig, was die Aufgabe noch komplexer machte.
Gute Methode, aber schlecht skalierbar
Die Studie konzentrierte sich dabei auf Bücher, die in den Jahren 2023 und 2024 veröffentlicht wurden, um zu vermeiden, dass sie bereits im Trainingsmaterial enthalten sind und so möglicherweise das Ergebnis verfälschen.
Um die Kosten und die kognitive Belastung für die Annotatoren so gering wie möglich zu halten, sollten sie die Bücher außerdem zuvor in ihrer Freizeit gelesen haben.
Allerdings stellen sie auch fest, dass ihr Ansatz nur schlecht auf neue Bücher und Datensätze skalierbar ist: Die 14 über Upwork rekrutierten menschlichen Helfer:innen hätten insgesamt 5.200 US-Dollar gekostet. Die Erweiterung und ständige Aktualisierung des Trainingssatzes wäre daher sehr zeit- und kostenintensiv.
Die Forscher:innen experimentierten daher auch damit, LLMs selbst zur automatischen Überprüfung von Behauptungen einzusetzen, nachdem frühere Arbeiten vielversprechende Ergebnisse geliefert hatten.
Aber selbst ihre beste Methode, vergleichbar mit der "Needle in a Haystack"-Methode, bei der Claude 3 Opus aufgefordert wurde, eine einzelne Behauptung anhand des vollständigen Buchtextes zu überprüfen, hatte Schwierigkeiten, falsche Behauptungen zuverlässig zu erkennen.

Über die Korrektheit der Aussagen hinaus haben die Forscher auf der Grundlage der Freitextkommentare der Annotatoren weitere Thesen aufgestellt.
Generell haben alle Sprachmodelle chronologische Fehler gemacht, wobei die Modelle mit einem größeren Kontextfenster weniger betroffen waren.
Alle Modelle wurden auch für das Weglassen wichtiger Informationen kritisiert. Claude 3 Opus schnitt diesbezüglich noch am besten ab, während GPT-4 Turbo und Mixtral sogar einzelne Personen ausließen.
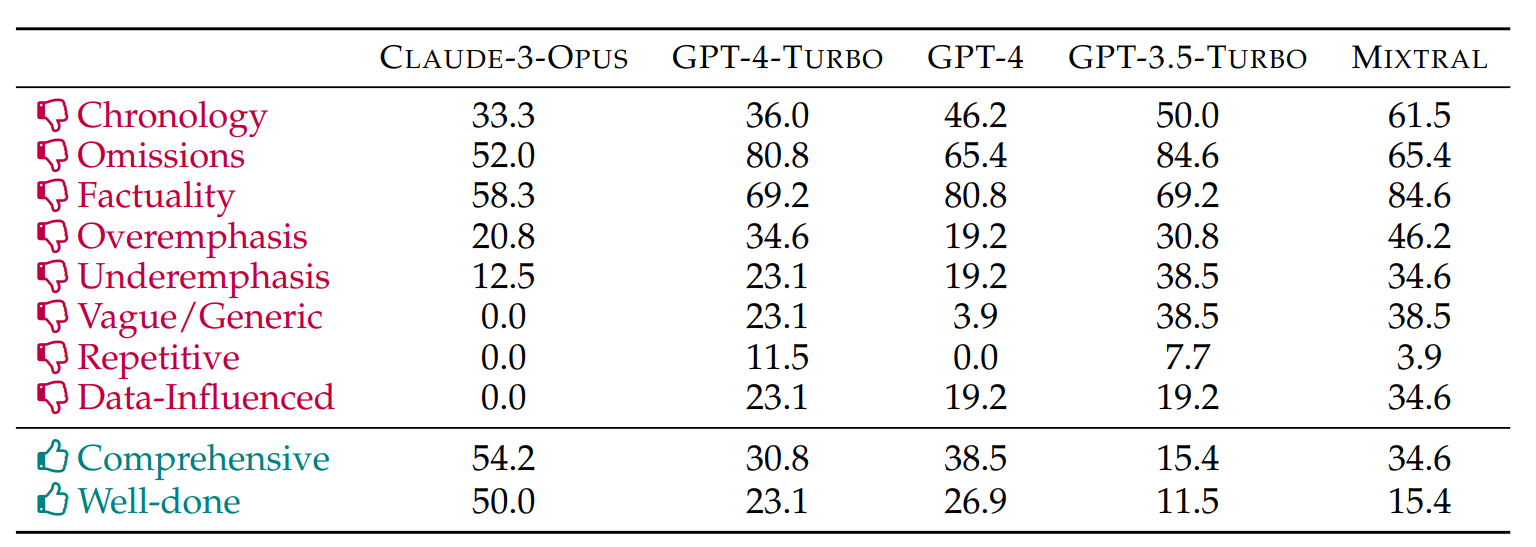
Die Forscher bestätigen auch die zuvor bei verschiedenen Modellen mit sehr langen Kontextfenstern festgestellte Tendenz, dem Inhalt am Ende eines Buches systematisch mehr Bedeutung beizumessen.
Auch wenn es im begleitenden Paper nicht als solches bezeichnet wird, stellt dieses "Lost-in-the-Middle"-Phänomen die KI-Wissenschaft schon seit einiger Zeit vor Probleme.
Die Forscherinnen und Forscher veröffentlichen den FABLES-Datensatz auf GitHub, um weitere Untersuchungen dieser Art zu fördern.